




This is the first post in a series of four about the different compaction strategies available in ScyllaDB. The series will look at the good and the bad properties of each compaction strategy, and how to choose the best compaction strategy for your workload. This first post will focus on ScyllaDB’s default compaction strategy, size-tiered compaction strategy.
Although we’ll discuss the ScyllaDB database throughout these posts, almost everything said here also applies to Apache Cassandra, which supports most of the same compaction strategies as ScyllaDB does. I said most because the Hybrid Compaction strategy, presented in the third post, is unique to ScyllaDB and not available in Cassandra. We’ll see in that third post how this new compaction strategy has unique advantages over the Size-Tiered compaction strategy (which we investigate in this post) and over the Leveled compaction strategy (which we’ll discuss in the second post). The fourth post will conclude the series with advice on how to choose the right compaction strategy for your workload.
These posts are based on a talk that I gave (with Raphael Carvalho) at the last annual ScyllaDB Summit in San Francisco. The video and slides for the talk are available on our Tech Talk page.
Compaction
If you’re already familiar with compaction in ScyllaDB, feel free to skip this section. Otherwise, this section will introduce you to compaction in three paragraphs: what it does and why it’s needed.
ScyllaDB’s write path follows the familiar Log Structured Merge (LSM) design for efficient writes that are immediately available for reads (one of the first projects to make this technique popular was the Lucene search engine, in 1999).
ScyllaDB writes updates to a memory table (memtable), and when that becomes too big, it is flushed to a new disk file. This file is sorted (and hence known as sstable, “sorted string table”) to make it easy to search and later merge.
As more updates come in, the number of separate sstables continues to grow and two problems start to appear: First, data in one sstable which is later modified or deleted in another sstable wastes space. Second, when data is split across many sstables, read requests may need to read from more sstables, slowing reads down. ScyllaDB mitigates the second problem by using a bloom filter and other techniques to avoid reading from sstables which it knows will not include the desired partition, but as the number of sstables grows, inevitably so do the number of disk files from which we need to read on every read query.
For these reasons, as soon as enough sstables have accumulated, some of them are compacted together. Compaction merges several sstables into one new sstable which contains only the live data from the input sstables. Merging several sorted files to get a sorted result is an efficient process, and this is the main reason why sstables are kept sorted.
A compaction strategy is what determines which of the sstables will be compacted, and when.
Size-Tiered Compaction Strategy
ScyllaDB’s default compaction strategy, which was also the first compaction strategy introduced in Cassandra (and still its default today), is Size-Tiered compaction strategy (STCS). The idea of STCS is fairly straightforward, as illustrated here:
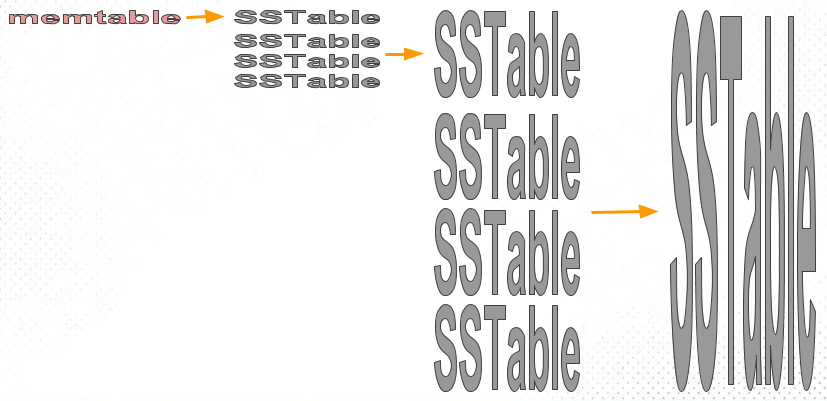
As usual, memtables are periodically flushed to new sstables. These are pretty small, and soon their number grows. As soon as we have enough (by default, 4) of these small sstables, we compact them into one medium sstable. When we have collected enough medium tables, we compact them into one large table. And so on, with compacted sstables growing increasingly large.
The full STCS algorithm is more complex than what we just described, because sstables may have overlapping data or deletions and thus the compacted sstables have varying sizes that don’t fall neatly into “small, medium, large, etc.” categories. Therefore STCS tries to fit the sstables into buckets of similarly-sized sstables, and compacts sstables within each of these buckets. Understanding these details is not necessary for the point of this post, but if you’re curious, refer to this blog post from 2014 or any other documentation of ScyllaDB’s or Cassandra’s size-tiered compaction strategy.
Size-tiered compaction has several compelling properties which made it popular as the first and default compaction strategy of Cassandra and ScyllaDB, and of many other LSM implementations. It results in a low and logarithmic (in size of data) number of sstables, and the same data is copied during compaction a fairly low number of times. We’ll address these issues again, using measures called read amplification and write amplification, in the following posts. In this post, we want to focus on the weakest aspect of size-tiered compaction, known as space amplification. This weakness is what eventually led to the development of alternative compaction strategies, such as leveled compaction and hybrid compaction which we will investigate in the next two posts.
Space Amplification
A compaction strategy has a space amplification problem when it requires that the disk be larger than a perfectly-compacted representation of the data (i.e., all the data in one single sstable).
In the past, spinning disks were cheap and supported a low number of random reads per second, so wasting disk space was almost excusable. In those days, the space amplification problem was not a major concern. But it has definitely become a major concern on modern SSDs. For example, a recent paper by Facebook researchers explains that “storage space is most often the primary bottleneck when using Flash SSDs under typical production workloads at Facebook”.
Let’s look at two experiments with STCS to demonstrate that it has, sadly, a serious space amplification problem. As mentioned above, all experiments were run with ScyllaDB, but Cassandra would have yielded similar results.
Experiment 1
The first experiment is a straightforward write-only workload: a cassandra-stress write workload, writing 10,000 different partitions (with cassandra-stress’s default schema) per second until 30 million partitions are written1. The server has one node, with one shard (CPU), and of course using the size-tiered compaction strategy.
If we graph the amount of disk space being used at each time, ideally we would like to see a straight line with a constant slope: The disk usage should be growing by the size of 10,000 partitions (about 3 MB) every second. At the end of the run, disk usage should be about 9 GB. However, what we actually measure is this graph:

We can clearly see disk-usage spikes during compactions. The height of the spike depends on the size of the sstables being compacted: Looking from the left, we see small spikes at times 125, 250, and 375, each of those corresponds to a small compaction of four small sstables into one medium sstable. By time 500, we have created 4 medium sstables and start compacting all of them into one large sstable. By time 2000, we have 4 large sstables and compact them all into one huge sstable.
The disk usage spikes happen because, during compaction, the input sstables cannot be deleted until we finished writing the output sstable. So right before the end of the compaction, we have the data on disk twice – in the input sstables and output sstables. At some points of the run, when we happen to compact all the sstables, we temporarily need the disk to be twice larger than all the data in the database. For example, at time 2000 in the above experiment, we are holding 6 GB of data but temporarily need a 12 GB disk.
Although the extra disk-space need is only temporary, it is nevertheless a serious problem. It has led Cassandra “best practices” manuals to state that users of size-tiered compaction must ensure that half the disk is free at all times. If you reach 51% disk usage, everything may be fine for a while, until the unlucky moment when all your data is in the largest size tier and STCS decides to compact it. This 2-fold space amplification, buying twice the disk space you really need, is an expensive problem.
It is interesting to note that on many-core machines, the temporary-space-need problem is actually less serious in ScyllaDB than in Apache Cassandra. ScyllaDB (unlike Cassandra) is sharded inside each node, meaning that in a node with N cores, each core gets 1/N of the data in its own separate sstables. Each core is also responsible for its own compactions. Had all the cores decided to compact everything at exactly the same time, we would have the same problem. But more typically, not all cores will be compacting all their data at the same time, so rather than having on disk two copies of all the data, at each time we may have two copies of “just” 1/N of the data. Nevertheless, in today’s ScyllaDB, if we’re unlucky or using major compaction (which asks all shards to compact everything, now), we can nevertheless reach a situation where all shards reach their peak disk usage at the same time. While this can, in theory, be avoided (by not doing a large compaction on one shard while too many other shards are doing large compactions), as we’ll see in the “hybrid compaction strategy” post later in this series, we can completely avoid the temporary disk space usage by compacting sstables in small parts, and that will be a much better solution to this problem.
The second experiment will demonstrate an even more serious space-amplification problem with STCS: We will see space amplification much higher than 2, and not as brief in time as the one we saw in the first experiment and therefore more likely to affect all shards at the same time:
Experiment 2
Size-tiered compaction strategy wastes most space when we already have data in a large sstable and then we get an overwrite of the same data – this may be exactly the same data again, or different values in the same row, or a deletion. In each case, the new data will be written to a new small sstable, and both copies will remain on disk until enough (by default 4) large sstables have been written and can be compacted. By that time, we can already have 4 copies of the same data in all 4 sstables, and with the additional copy written during compaction (as in experiment 1), we end up with 5-fold space amplification! But actually, it can be even worse: The same data may end up not only in 4 copies in the same size tier, but in additional copies in the smaller tiers, further increasing the space amplification.
To demonstrate how bad this overwrite-related space amplification problem is for STCS, we look at a simple overwrite workload: we run a simple cassandra-stress write-only workload writing 4 million different partitions2 and repeat this same workload, writing exactly the same data, 15 consecutive times. The graph showing disk usage vs. time now looks like this:

In this graph, we can see the amount of data we really have in our database is 1.2 GB – this is the disk usage that remains after we do a major compaction at the end of the run (i.e., compact all the data into one sstable). But the peak disk usage was 9.3 GB, an almost 8-fold space amplification! We can also see that we reached this peak several times, and space amplification was higher than 3-fold during most of the run. Even if we had multiple shards whose disk peaks were unsynchronized, we would see this very high space amplification.
This STCS huge space amplification is, clearly, a problem for workloads where the same data needs to be overwritten again and again. But some users have been hit with this problem – and a full disk – even though they had only a few overwrites. For example, we saw one user whose ScyllaDB database was uploaded in bulk from external data, and a glitch in that uploading system caused all the same data to be uploaded again into ScyllaDB. For another user, a repair process that found small differences in a large number of partitions caused all these partitions – plus many neighboring partitions that haven’t changed – to be re-written into the database. These users suddenly discovered that even though they had half their disk free – as is recommended in STCS because of what we saw in experiment 1 – this was not enough when the surprise overwrites started.
What’s Next?
In this post, we saw that space amplification is a serious problem for the Size-Tiered Compaction Strategy and makes it unsuitable for many kinds of workloads. In the upcoming posts in this series, we will look at two compaction strategies which solve this problem: The next post will be about Leveled Compaction Strategy (supported by both ScyllaDB and Cassandra), which solves the space amplification problem but unfortunately replaces it with a new problem: write amplification. The subsequent post will present the Hybrid Compaction Strategy, a strategy unique to ScyllaDB, which aims to improve the space amplification of size-tiered compaction without giving up on its low write amplification.
1. cassandra-stress example 1:cassandra-stress write n=30000000 -pop seq=1..30000000 -schema "replication(strategy=org.apache.cassandra.locator.SimpleStrategy,factor=1)" -rate threads=30 limit=10000/s
2. cassandra-stress example 2: cassandra-stress write n=4000000 -pop seq=1..4000000 -schema "replication(strategy=org.apache.cassandra.locator.SimpleStrategy,factor=1)"



