





A database like ScyllaDB can be limited by the network, disk I/O or the processor. Which one it is often dynamic and depends on both the hardware configuration and the workload. The only way of dealing with that is to attempt to achieve good throughput and low latency regardless of what is the bottleneck. There are many things that can be done in each of these cases that range from high-level changes in the algorithms to very low-level tweaks. In this post, I am going to take a closer look at fairly recent changes to ScyllaDB which improved the performance for the CPU-bound workloads.
Diagnosing the problem
When it comes to investigating situations when the CPU is the bottleneck Flame Graphs are truly invaluable. They can quickly point you to a part of the code that is much slower than it feels it should be and armed with that information appropriate steps can be taken in order to optimize it. Unfortunately, knowing how much processor time was spent in particular functions may be not enough. When the CPU is busy it may be so because it is actually doing some work or is stalled waiting for memory, as Brendan Gregg has explained it very well in this post. A useful metric that can be used to quickly determine whether the processor stalls are an issue is the number of completed instructions per cycle (IPC). If it is low, less than 1, it is very likely that the application is, in fact, memory bound.
Even though IPC can be very useful in pointing the performance analysis in the right direction it is certainly not enough to fully understand the problem. Fortunately, modern processors have Performance Monitoring Unit (PMU) which gives insight into what is actually happening at the microarchitectural level. The amount of the available information can be quite overwhelming unless an appropriate methodology is used.
A very handy tool for collecting and analyzing data provided by the PMU is toplev. It employs the Top-Down Analysis, which uses a hierarchical representation of the processor architecture to keep track of pipeline slots. This enables tools like toplev to show the percentages of slots the were stalled, wasted by bad speculation or used by a successfully retired instruction.
The diagram below shows, in a very simplified way, the microarchitecture of a modern x86 CPU from the point of view of Top-Down Analysis. There are many things missing, but it should be sufficient for the purposes of this post.
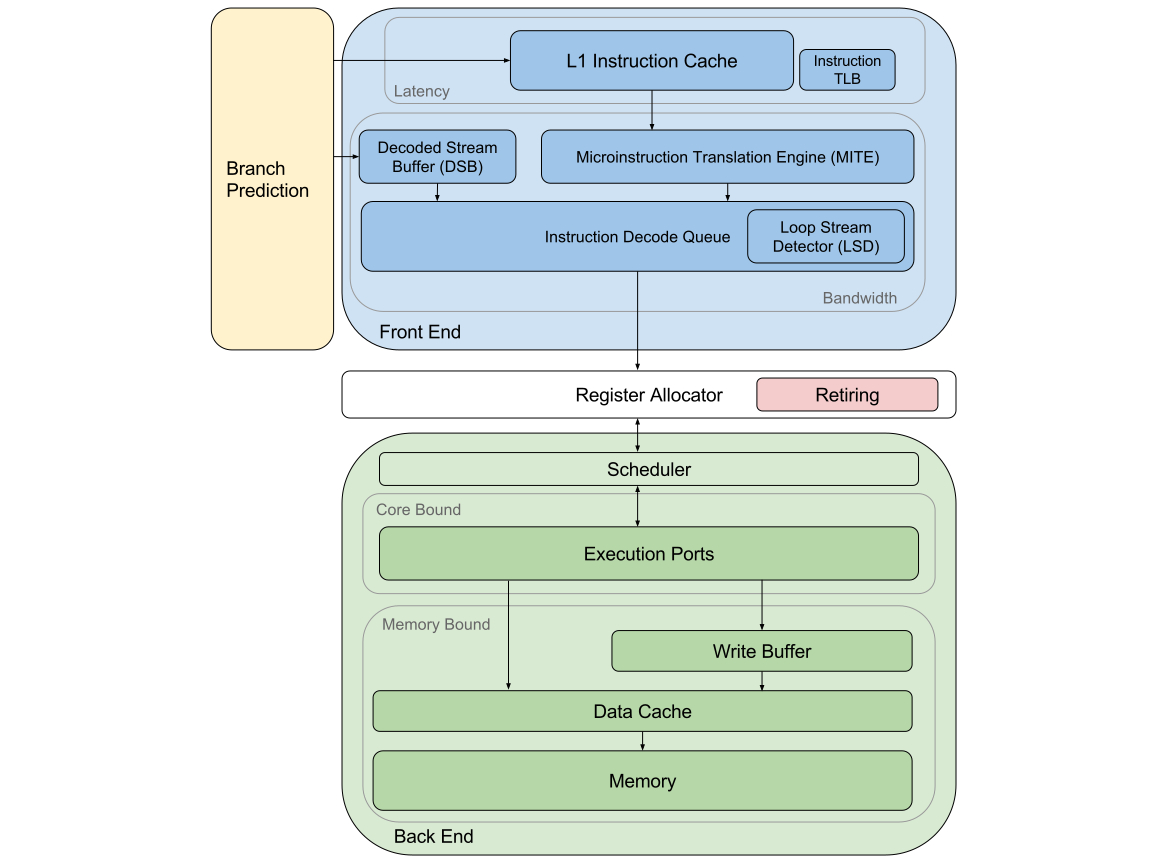
Microarchitecture of a modern x86 CPU
At the top level, there are four major categories Front End Bound, Back-End Bound, Bad Speculation and Retiring. The first two mean that there was a stall, Bad Speculation denotes pipeline slots that did the work that was not necessary because of a branch misprediction and slots classified as Retiring were able to successfully retire the µop that was being executed.
Processor’s front end is responsible for fetching and decoding instructions that are going to be executed. It may become a bottleneck when there is either a latency problem or the bandwidth is not sufficient. The former can be caused, for example, by instruction cache misses. The latter happens when the instruction decoders cannot keep up, the solution there may be to attempt to make the hot path, or at least significant portions of it, fit in the decoded µop cache (DSB) or be recognizable by the loop detector (LSD).
Pipeline slots classified by the Top-Down Analysis as Bad Speculation are not stalled but wasted. This happens when a branch is mispredicted and the rest of the CPU executes a µop that eventually cannot be committed. While the branch predictor is generally considered to be a part of the front end, its problems can affect the whole pipeline in a different way than just causing the back end to be undersupplied by the instruction fetch and decode.
Back end receives decoded µops and executes them. A stall may happen either because of an execution port being busy or a cache miss. At the lower level, a pipeline slot may be core bound either due to data dependency or an insufficient number of available execution units. Stalls caused by memory can be caused by cache misses at different levels of data cache, external memory latency or bandwidth.
Finally, there are pipeline slots which get classified as Retiring. They are the lucky ones that were able to execute and commit their µop without any problems. When 100% pipeline slots are able to retire without a stall then the program has achieved the maximum number of instructions per cycle for that model of the CPU. Whilst very desirable this, however, doesn’t mean that there is nothing to improve. It just means that the CPU is fully utilized and the only way to improve the performance is to reduce the number of instructions.
Let’s see then what toplev has to say about ScyllaDB 1.7. Unless stated otherwise all test results shown in this post are read workloads with 75,000,000 one-row partitions. The entire population fits in memory, there are no cache misses. There is a single ScyllaDB server with 4 cores (the processor is an eight-core Haswell) and 64GB of memory. The loader is a single 4 core (8 logical CPUs) machine running 4 scylla-bench processes each pinned to its own core. The 1Gbit network is far from being saturated since the partitions are very small. The purpose of this setup is to ensure that ScyllaDB is actually CPU bound.

Toplev Test Results – Before SEDA
The message the PMU is trying to convey here is quite clear. ScyllaDB is completely dominated by the front end, instruction cache misses in particular. If we think about this for a moment it shouldn’t really be very surprising, though. The pipeline that each client request goes through is quite long. For example, write requests may need to go through transport protocol logic, CQL layer, coordinator code, then it becomes a commitlog write and then it is applied to the memtable. The situation is no better for reads, which means that individual ScyllaDB requests usually involve a lot of logic and relatively little data, which is a scenario that stresses the CPU front end significantly.
Looking for a solution
Once the problem has been diagnosed it is time to come up with a solution. The most obvious one is to attempt to reduce the amount of logic in the hot path. Unfortunately, this is not something that has a huge potential for a significant performance improvement. The CQL protocol supports prepared statements which allow splitting the preparation and the execution part of the request processing so that as much work as possible can be pushed out of the hot path. ScyllaDB already does all that, so while there undoubtedly are some things that could be improved they are unlikely to make a big difference.
Another thing to consider is templates and inline functions. Both ScyllaDB and Seastar are heavy users of those which brings the risk of ending up with excessively bloated binaries. However, this is quite tricky since inlining can, in some situations, actually reduce the amount of code in the hot path if the inlined function can be subject to some optimizations that wouldn’t be otherwise possible. One particular place where we have seen a significant difference was serialization code which was writing several fixed size objects. Because the size of the object to serialize was known at the compile time if the serialization functions were inlined the compiler was able to constant-fold them to just a few instructions, significantly improving the overall performance. The point is that whether to inline or not is more a matter of fine-tuning which has the disadvantage of making any optimizations fragile and is probably unlikely to cause a huge improvement.
Keen readers of GCC documentation will notice that there is optimization flag “-freorder-blocks-and-partition” which promises to split hot and cold parts of the function and place them at different locations. This sounds very encouraging, but unfortunately, that flag works only with PGO (Profile-Guided Optimisation) and conflicts with the support for stack unwinding, which is required by the C++ exception implementation. The bottom line is that this flag, sadly, is unusable for ScyllaDB.
There is, however, a higher level way of dealing with instruction cache problems. SEDA (Staged Event-Driven Architecture) is a server architecture that splits the request processing pipeline into a graph of stages. Each stage represents a part of the server logic and consists of a queue and a thread pool. The main problem of this architecture are context switches and inter-processor communication when requests are moved between stages, but this can be partially alleviated by processing them in batches. This is all very friendly towards the instruction cache since each thread executes always the same operation, multiple times before a context switch happens, so the code locality can be expected to be very good. Unfortunately, while such architecture can be acceptable when the focus is primarily on achieving high throughput, it is rather unsuitable for low-latency applications.
ScyllaDB is using Thread Per Core architecture which avoids context switches and minimizes inter-processor communication making it much better suited for low latency tasks than SEDA. However, the ability to insert queues in the request processing pipeline which would allow batching some of the operations is something that could be very useful, provided that it is done carefully lest it hurts latency. That’s exactly what we implemented.
Implementing execution stages
The idea to deal with front-end latency problem was to process certain function calls in batches so that the first invocation warms up the instruction cache and the subsequent ones can execute with a minimal number of icache misses.
Fortunately, the fact that Seastar is based on future, promise, continuation model made it very easy to introduce execution stages to the existing code. Let’s say we have some server code with process_request() function that calls internal do_process_request() which contains the actual logic:
future<response> do_process_request(request r);
future<response> process_request(request r) {
return do_process_request(std::move(r));
}
Execution stages were implemented as wrappers that produce a function object with almost the same signature as the original function. Now, if we want to batch calls to do_process_request() we can write:
future<response> do_process_request(request r);
thread_local auto processing_stage = seastar::make_execution_stage("processing-stage", do_process_request);
future<response> process_request(request r) {
return processing_stage(std::move(r));
}
The changes to the code are rather minimal, but nothing more is needed. Instead of a call to do_process_request() there is an invocation of the processing_stage object which can freely decide when to call the original function which result will be forwarded to the future returned by the execution stage.
What happens underneath is that each call to the execution stage pushes the function arguments to a queue and returns a future that will be resolved when the function call actually happens. At some point the execution stage is going to be flushed, a new task is going to be scheduled that would execute all of the queued function calls. This is when one has to be careful as the last sentence has introduced two potential latency problems.
Firstly, while having large batches is beneficial, function calls must not be kept in the queue for too long. The solution is fairly easy, Seastar periodically polls for new events and makes an effort to ensure that this doesn’t happen less often than once per a specified interval called task quota. Execution stages register themselves as pollers and flush the queue when they are polled. If the server is heavily loaded the stages are going to be flushed not less often than once per task quota and if the server is lightly loaded the flush is going to happen every time there are no other tasks to run. The batches can be quite small in this case, but keeping the latency low is more important.
Secondly, it is possible that processing the whole batch of function calls may take a lot of time. This could ruin the latency of other tasks, so the execution stage needs to respect the task quota itself and interrupt executing the queued function calls if its time quota runs out. Again, that is something that may limit the size of the batches and the overall effectiveness of the execution stages, but this is a trade-off between the latency and throughput and the proper solution is somewhere in the middle ground.
With the execution stages implemented at the Seastar level, it was quite easy to introduce them to ScyllaDB. They were added more or less in places where request processing moves from one subsystem to another.
- Transport protocol – CQL native protocol is asynchronous as there may be numerous outstanding requests in a scope of a single connection, an execution stage was added just before the actual request processing logic.
- CQL layer – a stage was introduced before the execution of a SELECT, BATCH, UPDATE or INSERT statement starts.
- Coordinator – all write requests are queued and then processed in batches by the coordinator logic.
- Database write – there is an execution stage before the database write implementation that collects incoming requests both from local and remote coordinators.
- Database read – ScyllaDB reads are either data queries or mutation queries. The former is more lightweight used for single-partition reads while the latter is used for range queries and as a fallback for data queries. Both have their own execution stages now.
Results
It is time to finally show some numbers. The load is, again, reads with no cache miss, the server is CPU bound. Let’s look at the throughput first.
| Throughput | Before | After | Difference |
| Reads [op/s] | 162696 | 234326 | +44.03% |
That’s a significant improvement, but it is worth ensuring that the latencies didn’t fall victim to the function call batching. In order to test this, the loaders were limited to 28,000 operations per second. The graph below compares 99th percentile request latencies of ScyllaDB 1.7 with and without execution stage patches.

Execution Stage Latency
The latencies are actually slightly better. This can be attributed to the fact that the penalty of moderate batching is lower than the performance increase caused by better instruction cache locality. Summary of a 15-minute run shows the general reduction of request latency.
| Latency at 28000 OPS | Before | After |
| 99.9th %ile | 819µs | 786µs |
| 99th %ile | 524µs | 491µs |
| 95th %ile | 425µs | 393µs |
| 90th %ile | 393µs | 360µs |
| Mean | 292µs | 282µs |
The increase in throughput is accompanied by an increase of IPC (Instructions Per Cycle), as reported by perf stat, from around 0.81 to 1.31. The ratio of instruction cache misses is reduced from 5.39% to 3.05%. Toplev results have changed as well:

Toplev Test Results – After SEDA
‘The front-end latency issues are, clearly, still there, but they are not dominating as much as they used to do. The bandwidth of the front end is also limiting ScyllaDB performance when the instructions are being issued by the MITE (MicroInstruction Translation Engine), as opposed to the decoded icache or the loop detector. There are also L1 cache misses which make the back end a more important bottleneck than it was before.
The introduction of execution stages did not eliminate instruction cache misses to the point that toplev doesn’t notice them, but at this point simply adding more stages is not necessarily the best solution. Each stage potentially hurts latency so they have to be added wisely and carefully. The important thing that impacts the effectiveness of the stage are the sizes of the batches we can actually get. Appropriate metrics were introduced to monitor that. For the read test data query stage on each shard has been processing around 58,000 function calls per second and scheduling 1,000 batches per second which make the average batch size of 58. This is certainly not bad but is going to be much lower if the ScyllaDB isn’t fully loaded or the network or disk I/O is a bottleneck and when the batches are small the stages become an overhead rather than an improvement. One cannot also forget that the batching is an enemy of the latency and if it made too aggressive the latency penalty may outweigh the benefits of the better instruction cache locality. So, while it would be tempting to try to make batching aggressive, it is not necessarily a right direction.
What could be beneficial is more fine tuning of the positions where the actual queues are introduced in the pipeline. As it was mentioned before, execution stages were added more or less at the conceptual boundaries of the ScyllaDB subsystems which doesn’t necessarily mean that these are the optimal places. However, at this point, it becomes more and more a matter of fine-tuning and while it could still allow us to squeeze even more performance from ScyllaDB it can be quite fragile when the code changes and it may be more worthwhile to focus on the other bottlenecks.
Conclusion
Function call batching inspired by SEDA has brought a major performance improvement for CPU-bound loads and helped to shift the bottleneck to the other parts of the processor microarchitecture. The change itself wasn’t very intrusive nor was it complex, but it has significantly increased the throughput in the cases where instruction cache misses were the limiting factor. With proper methodology for analyzing information provided by the PMU, it was relatively easy to find out what the problem was and choose the most cost effective solution. There are still many things that could be done to improve the performance but this has to be done step by step, each time dealing with the current most significant bottleneck and in this case, the goal of reducing its impact have been definitely achieved.


