





A detailed walk-through of an end-to-end DynamoDB to ScyllaDB migration
We previously discussed ScyllaDB Migrator’s ability to easily migrate data from DynamoDB to ScyllaDB – including capturing events. This ensures that your destination table is consistent and abstracts much of the complexity involved during a migration.
We’ve also covered when to move away from DynamoDB, exploring both technical and business reasons why organizations seek DynamoDB alternatives, and examined what a migration from DynamoDB looks like, walking through how a migration from DynamoDB looks like and how to accomplish it within the DynamoDB ecosystem.
Now, let’s switch to a more granular (and practical) level. Let’s walk through an end-to-end DynamoDB to ScyllaDB migration, building up on top of what we discussed in the two previous articles.
Before we begin, a quick heads up: The ScyllaDB Spark Migrator should still be your tool of choice for migrating from DynamoDB to ScyllaDB Alternator – ScyllaDB’s DynamoDB compatible API. But there are some scenarios where the Migrator isn’t an option:
- If you’re migrating from DynamoDB to CQL – ScyllaDB’s Cassandra compatible API
- If you don’t require a full-blown migration and simply want to stream a particular set of events to ScyllaDB
- If bringing up a Spark cluster is an overkill at your current scale
You can follow along using the code in this GitHub repository.

End-to-End DynamoDB to ScyllaDB Migration
Let’s run through a migration exercise where:
- Our source DynamoDB table contains Items with an unknown (but up to 100) number of Attributes
- The application constantly ingests records to DynamoDB
- We want to be sure both DynamoDB and ScyllaDB are in sync before fully switching
For simplicity, we will migrate to ScyllaDB Alternator, our DynamoDB compatible API. You can easily transform it to CQL as you go.
Since we don’t want to incur any impact to our live application, we’ll back-fill the historical data via an S3 data export. Finally, we’ll use AWS Lambda to capture and replay events to our destination ScyllaDB cluster.
Environment Prep – Source and Destination
We start by creating our source DynamoDB table and ingesting data to it. The create_source_and_ingest.py script will create a DynamoDB table called source, and ingest 50K records to it. By default, the table will be created in On-Demand mode, and records will be ingested using the BatchWriteItem call serially. We also do not check whether all Batch Items were successfully processed, but this is something you should watch out for in a real production application.
The output will look like this, and it should take a couple minutes to complete:
Next, spin up a ScyllaDB cluster. For demonstration purposes, let’s spin a ScyllaDB container inside an EC2 instance:
Beyond spinning up a ScyllaDB container, our Docker command-line does two things:
Exposes port 8080 to the host OS to receive external traffic, which will be required later on to bring historical data and consume events from AWS Lambda
Starts ScyllaDB Alternator – our DynamoDB compatible API, which we’ll be using for the rest of the migration.
Once your cluster is up and running, the next step is to create your destination table. Since we are using ScyllaDB Alternator, simply run the create_target.py script to create your destination table:
NOTE: Both source and destination tables share the same Key Attributes. In this guided migration, we won’t be performing any data transformations. If you plan to change your target schema, this would be the time for you to do it. 🙂
Back-fill Historical Data
For back-filling, let’s perform a S3 Data Export. First, enable DynamoDB’s point-in-time recovery:
Next, request a full table export. Before running the below command, ensure the destination S3 bucket exists:
Depending on the size of your actual table, the export may take enough time for you to step away to grab a coffee and some snacks. In our tests, this process took around 10-15 minutes to complete for our sample table.
To check the status of your full table export, replace your table ARN and execute:
Once the process completes, modify the s3Restore.py script accordingly (our modified version of the LoadS3toDynamoDB sample code) and execute it to load the historical data:
NOTE: To prevent mistakes and potential overwrites, we recommend you use a different Table name for your destination ScyllaDB cluster. In this example, we are migrating from a DynamoDB Table called source to a destination named dest.
Remember that AWS allows you to request incremental backups after a full export. If you feel like that process took longer than expected, simply repeat it in smaller steps with later incremental backups. This can be yet another strategy to overcome the DynamoDB Streams 24-hour retention limit.
Consuming DynamoDB Changes
With the historical restore completed, let’s get your ScyllaDB cluster in sync with DynamoDB. Up to this point, we haven’t necessarily made any changes to our source DynamoDB table, so our destination ScyllaDB cluster should already be in sync.
Create a Lambda function
Name your Lambda function and select Python 3.12 as its Runtime:
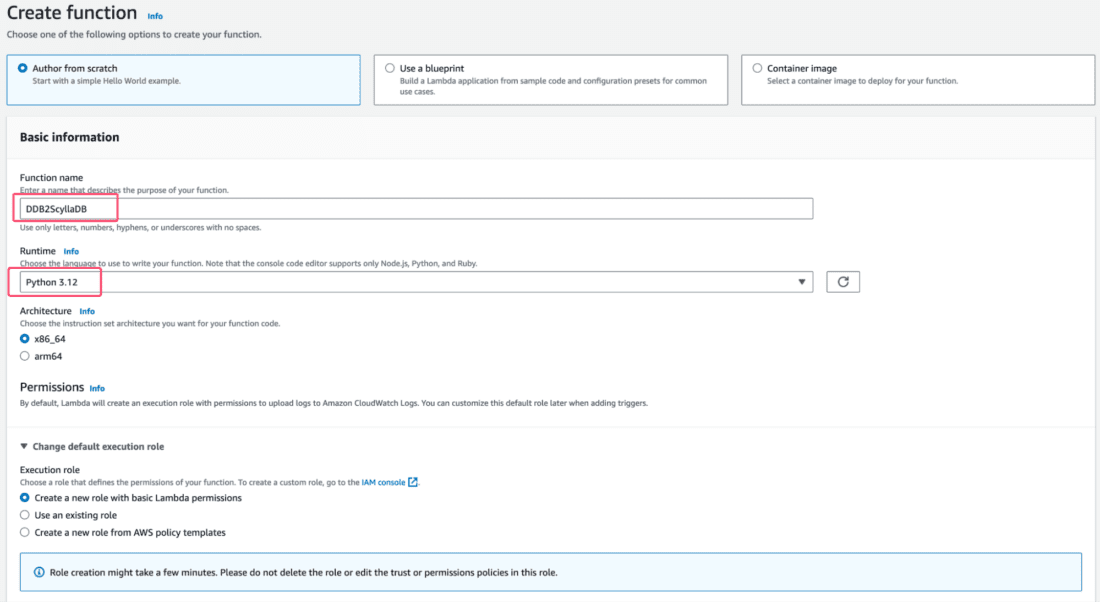
Expand the Advanced settings option, and select the Enable VPC option. This is required, given that our Lambda will directly write data to ScyllaDB Alternator, currently running in an EC2 instance. If you omit this option, your Lambda function may be unable to reach ScyllaDB.
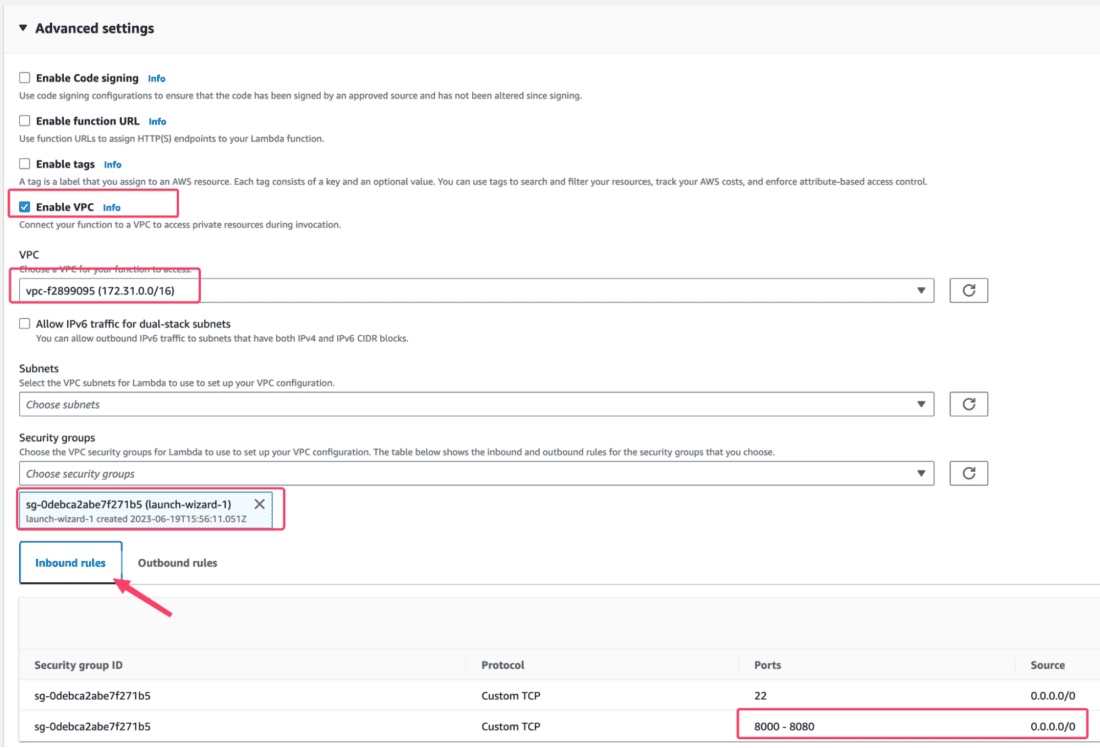
Once that’s done, select the VPC attached to your EC2 instance, and ensure that your Security Group allows Inbound traffic to ScyllaDB. In the screenshot below, we are simply allowing inbound traffic to ScyllaDB Alternator’s port:
Finally, create the function.
NOTE: If you are moving away from the AWS ecosystem, be sure to attach your Lambda function to a VPC with external traffic. Beware of the latency across different regions or when traversing the Internet, as it can greatly delay your migration time. If you’re migrating to a different protocol (such as CQL), ensure that your Security Group allows routing traffic to ScyllaDB relevant ports.
Grant Permissions
A Lambda function needs permissions to be useful. We need to be able to consume events from DynamoDB Streams and load them to ScyllaDB.
Within your recently created Lambda function, go to Configuration > Permissions. From there, click the IAM role defined for your Lambda:
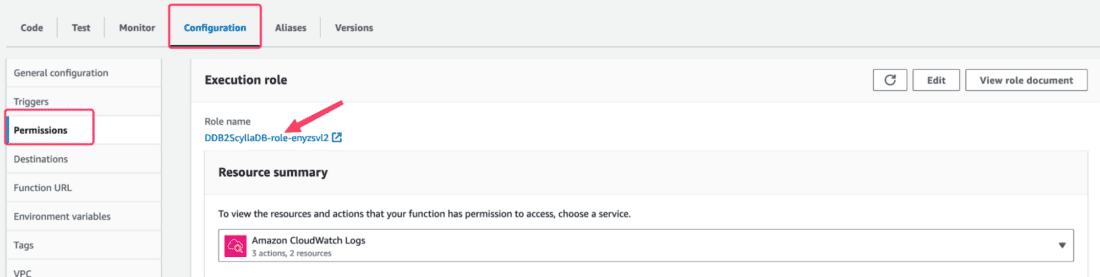
This will take you to the IAM role page of your Lambda. Click Add permissions > Attach policies:
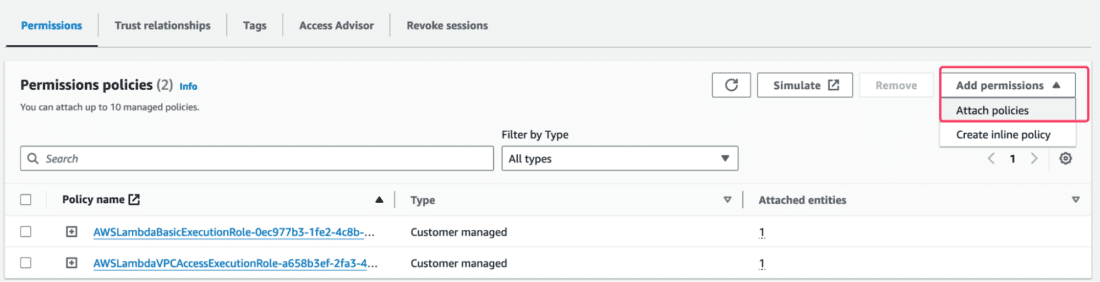
Lastly, proceed with attaching the AWSLambdaInvocation-DynamoDB policy.
Adjust the Timeout
By default, a Lambda function runs for only about 3 seconds before AWS kills the process. Since we expect to process many events, it makes sense to increase the timeout to something more meaningful.
Go to Configuration > General Configuration, and Edit to adjust its settings:

Increase the timeout to a high enough value (we left it at 15 minutes) that allows you to process a series of events. Ensure that when you hit the timeout limit, DynamoDB Streams won’t consider the Stream to have failed processing, which effectively sends you into an infinite loop.
You may also adjust other settings, such as Memory, as relevant (we left it at 1Gi).
Deploy
After the configuration steps, it is time to finally deploy our logic! The dynamodb-copy folder contains everything needed to help you do that.
Start by editing the dynamodb-copy/lambda_function.py file and replace the alternator_endpoint value with the IP address and port relevant to your ScyllaDB deployment.
Lastly, run the deploy.sh script and specify the Lambda function to update:
NOTE: The Lambda function in question simply issues PutItem calls to ScyllaDB in a serial way, and does nothing else. For a realistic migration scenario, you probably want to handle DeleteItem and UpdateItem API calls, as well as other aspects such as TTL and error handling, depending on your use case.
Capture DynamoDB Changes
Remember that our application is continuously writing to DynamoDB, and our ultimate goal is to ensure that all records ultimately exist within ScyllaDB, without incurring any data loss.
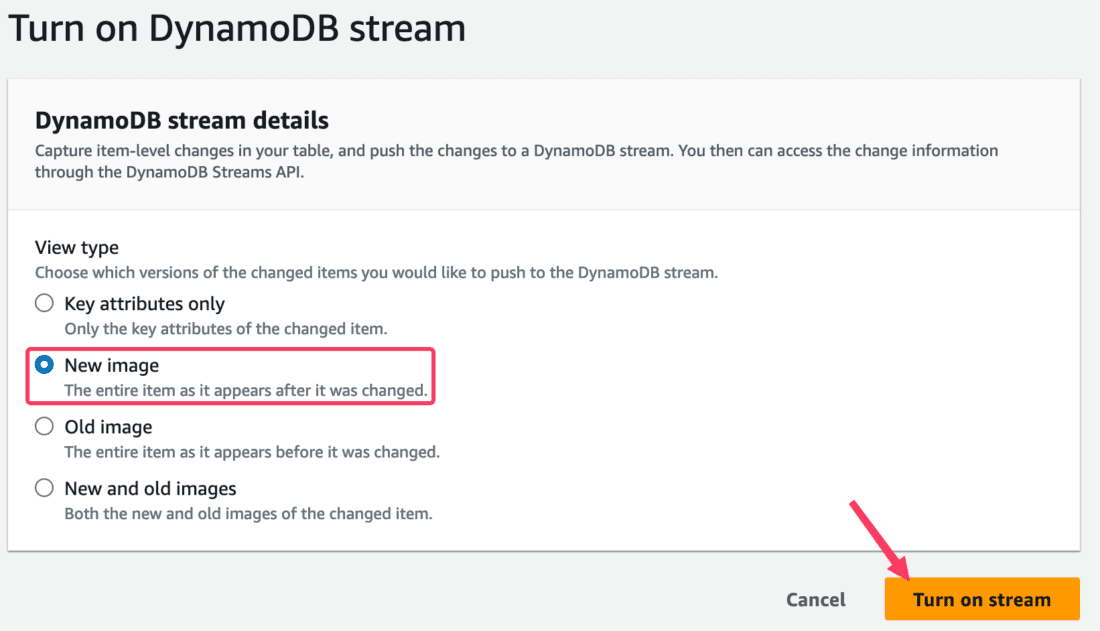
At this step, we’ll simply enable DynamoDB Streams to Capture change events as they go. To accomplish that, simply turn on DynamoDB streams to capture Item level changes:

In View Type, specify that you want a New Image capture, and proceed with enabling the feature:
Create a Trigger
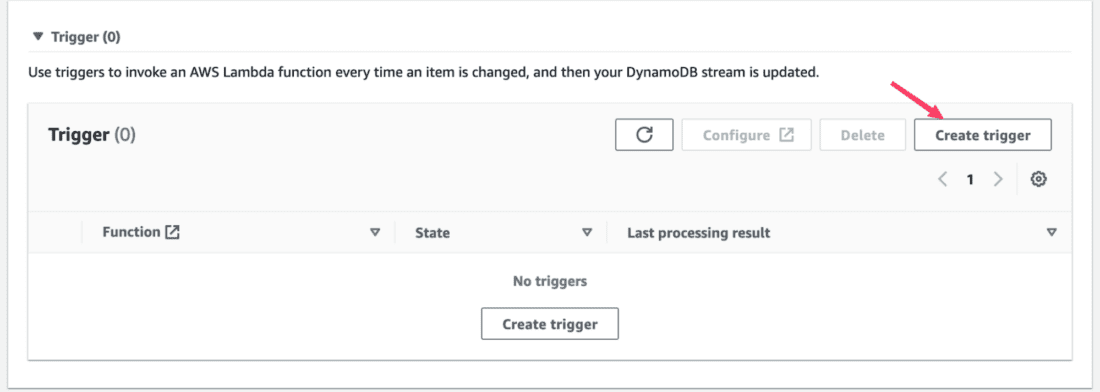
At this point, your Lambda is ready to start processing events from DynamoDB. Within the DynamoDB Exports and streams configuration, let’s create a Trigger to invoke our Lambda function every time an item gets changed:
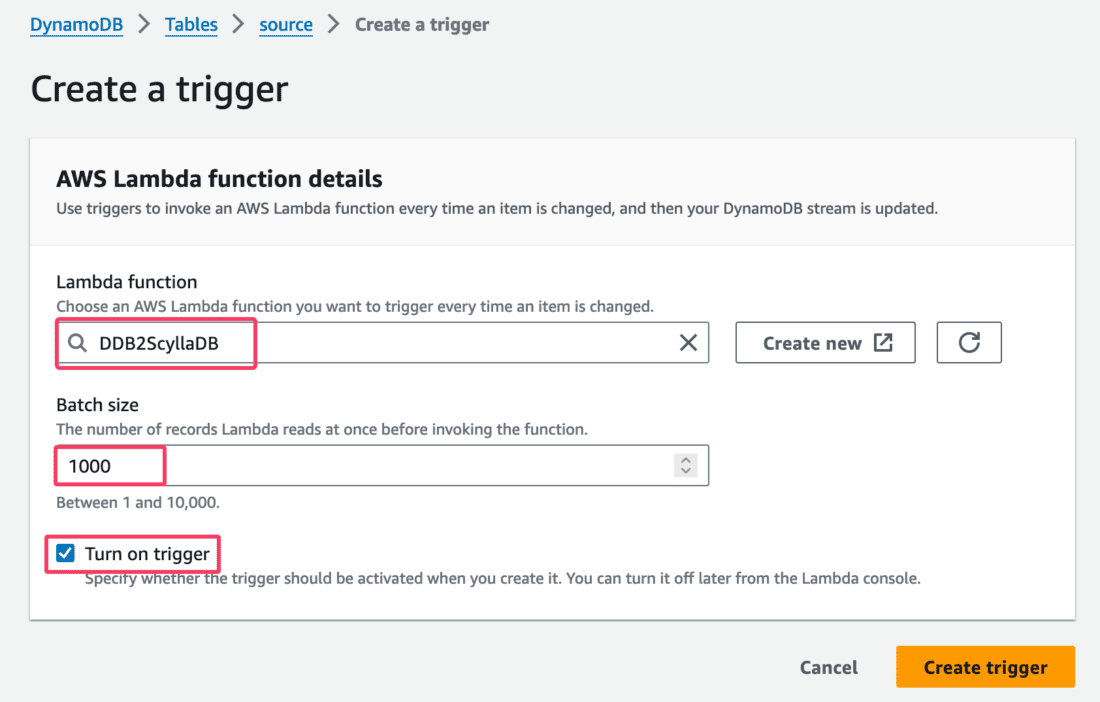
Next, choose the previously created Lambda function, and adjust the Batch size as needed (we used 1000):
Once you create the trigger, data should start flowing from DynamoDB Streams to ScyllaDB Alternator!
Generate Events
To show the situation of an application frequently updating records, let’s simply re-execute the initial create_source_and_ingest.py program: It will insert another 50K records to DynamoDB, whose Attributes and values will be very different from the existing ones in ScyllaDB:
The program found out the source table already exists and has simply overwritten all its existing records. The new records were then captured by DynamoDB Streams, which should now trigger our previously created Lambda function, which will stream its records to ScyllaDB.
Comparing Results
It may take some minutes for your Lambda to catch up and ingest all events to ScyllaDB (did we say coffee?). Ultimately, both databases should get in sync after a few minutes.
Our last and final step is simply to compare both database records. Here, you can either compare everything, or just a few selected ones.
To assist you with that, here’s our final program: compare.py! Simply invoke it, and it will compare the first 10K records across both databases and report any mismatches it finds:
Congratulations! You moved away from DynamoDB! 🙂
Final Remarks
In this article, we explored one of the many ways to migrate a DynamoDB workload to ScyllaDB. Your mileage may vary, but the general migration flow should be ultimately similar to what we’ve covered here.
If you are interested in how organizations such as Digital Turbine or Zee migrated from DynamoDB to ScyllaDB, you may want to see their recent ScyllaDB Summit talks. Or perhaps you would like to learn more about different DynamoDB migration approaches? In that case, watch my talk in our NoSQL Data Migration Masterclass.
If you want to get your specific questions answered directly, talk to us!


