





Teams sometimes need lower latency, lower costs (especially as they scale) or the ability to run their applications somewhere other than AWS
It’s easy to understand why so many teams have turned to Amazon DynamoDB since its introduction in 2012. It’s simple to get started, especially if your organization is already entrenched in the AWS ecosystem. It’s relatively fast and scalable, with a low learning curve. And since it’s fully managed, it abstracts away the operational effort and know-how traditionally required to keep a database up and running in a healthy state.
But as time goes on, drawbacks emerge, especially as workloads scale and business requirements evolve. Teams sometimes need lower latency, lower costs (especially as they scale), or the ability to run their applications somewhere other than AWS. In those cases, ScyllaDB, which offers a DynamoDB-compatible API, is often selected as an alternative.
Let’s explore the challenges that drove three teams to leave DynamoDB.
Multi-Cloud Flexibility and Cost Savings
Yieldmo is an online advertising platform that connects publishers and advertisers in real-time using an auction-based system, optimized with ML. Their business relies on delivering ads quickly (within 200-300 milliseconds) and efficiently, which requires ultra-fast, high-throughput database lookups at scale. Database delays directly translate to lost business.
They initially built the platform on DynamoDB. However, while DynamoDB had been reliable, significant limitations emerged as they grew. As Todd Coleman, Technical Co-Founder and Chief Architect, explained, their primary concerns were twofold: escalating costs and geographic restrictions. The database was becoming increasingly expensive as they scaled, and it locked them into AWS, preventing true multi-cloud flexibility.
While exploring DynamoDB alternatives, they were hoping to find an option that would maintain speed, scalability, and reliability while reducing costs and providing cloud vendor independence. Yieldmo first considered staying with DynamoDB and adding a caching layer. However, caching couldn’t fix the geographic latency issue. Cache misses would be too slow, making this approach impractical.
They also explored Aerospike, which offered speed and cross-cloud support. However, Aerospike’s in-memory indexing would have required a prohibitively large and expensive cluster to handle Yieldmo’s large number of small data objects. Additionally, migrating to Aerospike would have required extensive and time-consuming code changes.
Then they discovered ScyllaDB. And ScyllaDB’s DynamoDB-compatible API (Alternator) was a game changer.
Todd explained, “ScyllaDB supported cross cloud deployments, required a manageable number of servers, and offered competitive costs. Best of all, its API was DynamoDB compatible, meaning we could migrate with minimal code changes. In fact, a single engineer implemented the necessary modifications in just a few days.”
The migration process was carefully planned, leveraging their existing Kafka message queue architecture to ensure data integrity. They conducted two proof-of-concept (POC) tests: first with a single table of 28 billion objects, and then across all five AWS regions.
The results were impressive. Todd shared, “Our database costs were cut in half, even with DynamoDB reserved capacity pricing.” And beyond cost savings, Yieldmo gained the flexibility to potentially deploy across different cloud providers. Their latency improved, and ScyllaDB was as simple to operate as DynamoDB.
Wrapping up, Todd concluded: “One of our initial concerns was moving away from DynamoDB’s proven reliability. However, ScyllaDB has been an excellent partner. Their team provides monitoring of our clusters, alerts us to potential issues, and advises us when scaling is needed in terms of ongoing maintenance overhead. The experience has been comparable to DynamoDB, but with greater independence and substantial cost savings.”
Migrating to GCP with Better Performance and Lower Costs
Digital Turbine, a major player in mobile ad tech with $500 million in annual revenue, faced growing challenges with its DynamoDB implementation. While its primary motivation for migration was standardizing on Google Cloud Platform following acquisitions, the existing DynamoDB solution had been causing both performance and cost concerns at scale.
“It can be a little expensive as you scale, to be honest,” explained Joseph Shorter, vice president of Platform Architecture at Digital Turbine.
“We were finding some performance issues. We were doing a ton of reads — 90% of all interactions with DynamoDB were read operations. With all those operations, we found that the performance hits required us to scale up more than we wanted, which increased costs.”
Digital Turbine needed the migration to be as fast and low-risk as possible, which meant keeping application refactoring to a minimum. The main concern, according to Shorter, was “How can we migrate without radically refactoring our platform, while maintaining at least the same performance and value – and avoiding a crash-and-burn situation? Because if it failed, it would take down our whole company. “

After evaluating several options, Digital Turbine moved to ScyllaDB and achieved immediate improvements. The migration took less than a sprint to implement and the results exceeded expectations.
“A 20% cost difference — that’s a big number, no matter what you’re talking about,” Shorter noted. “And when you consider our plans to scale even further, it becomes even more significant.”
Beyond the cost savings, they found themselves “barely tapping the ScyllaDB clusters,” suggesting room for even more growth without proportional cost increases.
High Write Throughput with Low Latency and Lower Costs
The User State and Customizations team for one of the world’s largest media streaming services had been using DynamoDB for several years. As they were rearchitecting two existing use cases, they wondered if it was time for a database change. The two use cases were:
- Pause/resume: If a user is watching a show and pauses it, they can pick up where they left off – on any device, from any location.
- Watch state: Using that same data, determine whether the user has watched the show.
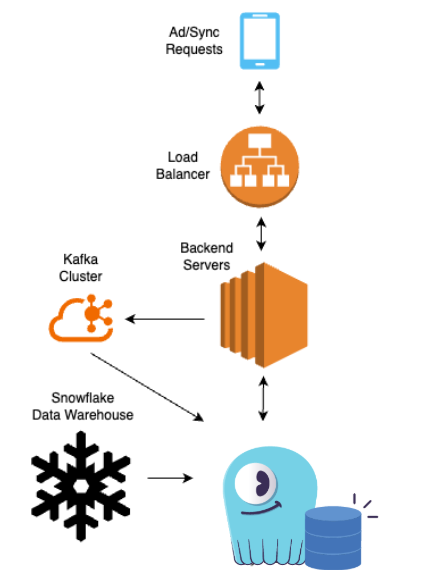
Here’s a simple architecture diagram:

Every 30 seconds, the client sends heartbeats with the updated playhead position of the show and then sends those events to the database. The Edge Pipeline loads events in the same region as the user, while the Authority (Auth) Pipeline combines events for all five regions that the company serves. Finally, the data has to be fetched and served back to the client to support playback. Note that the team wanted to preserve separation between the Auth and Edge regions, so they weren’t looking for any database-specific replication between them.
The two main technical requirements for supporting this architecture were:
- To ensure a great user experience, the system had to remain highly available, with low-latency reads and the ability to scale based on traffic surges.
- To avoid extensive infrastructure setup or DBA work, they needed easy integration with their AWS services.
Once those boxes were checked, the team also hoped to reduce overall cost.
“Our existing infrastructure had data spread across various clusters of DynamoDB and Elasticache, so we really wanted something simple that could combine these into a much lower cost system” explained their backend engineer.
Specifically, they needed a database with:
- Multiregion support, since the service was popular across five major geographic regions.
- The ability to handle over 170K writes per second. Updates didn’t have a strict service-level agreement (SLA), but the system needed to perform conditional updates based on event timestamps.
- The ability to handle over 78K reads per second with a P99 latency of 10 to 20 milliseconds. The use case involved only simple point queries; things like indexes, partitioning and complicated query patterns weren’t a primary concern.
- Around 10TB of data with room for growth.
Why move from DynamoDB? According to their backend engineer, “DynamoDB could support our technical requirements perfectly. But given our data size and high (write-heavy) throughput, continuing with DynamoDB would have been like shoveling money into the fire.”
Based on their requirements for write performance and cost, they decided to explore ScyllaDB. For a proof of concept, they set up a ScyllaDB Cloud test cluster with six AWS i4i 4xlarge nodes and preloaded the cluster with 3 billion records. They ran combined loads of 170K writes per second and 78K reads per second. And the results? “We hit the combined load with zero errors. Our P99 read latency was 9 ms and the write latency was less than 1 ms.”
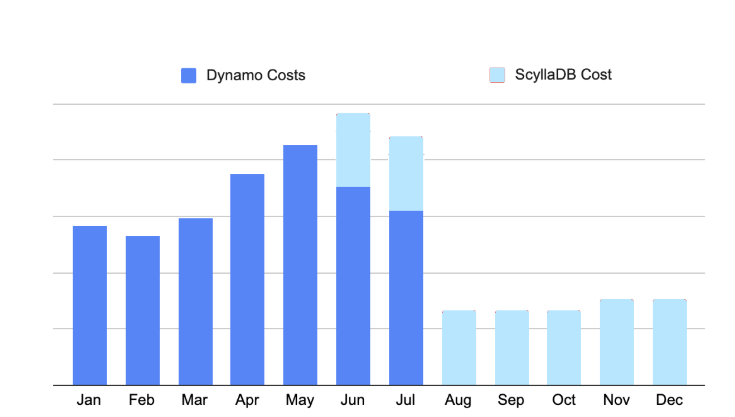
These low latencies, paired with significant cost savings (over 50%) convinced them to leave DynamoDB. Beyond lower latencies at lower cost, the team also appreciated the following aspects of ScyllaDB:
- ScyllaDB’s performance-focused design (being built on the Seastar framework, using C++, being NUMA-aware, offering shard-aware drivers, etc.) helps the team reduce maintenance time and costs.
- Incremental Compaction Strategy helps them significantly reduce write amplification.
- Flexible consistency level and replication factors helps them support separate Auth and Edge pipelines. For example, Auth uses quorum consistency while Edge uses a consistency level of “1” due to the data duplication and high throughput.
Their backend engineer concluded: “Choosing a database is hard. You need to consider not only features, but also costs. Serverless is not a silver bullet, especially in the database domain.
“In our case, due to the high throughput and latency requirements, DynamoDB serverless was not a great option. Also, don’t underestimate the role of hardware. Better utilizing the hardware is key to reducing costs while improving performance.”
Is Your Team Next?
If your team is considering a move from DynamoDB, ScyllaDB might be an option to explore. Sign up for a technical consultation to talk more about your use case, SLAs, technical requirements and what you’re hoping to optimize. We’ll let you know if ScyllaDB is a good fit and, if so, what a migration might involve in terms of application changes, data modeling, infrastructure and so on.
Bonus: Here’s a quick look at how ScyllaDB compares to DynamoDB


