




A look at the top reasons why teams decide to leave DynamoDB: throttling, latency, item size limits, and limited flexibility…not to mention costs
Full disclaimer: I love DynamoDB. It has been proven at scale and is the back-end that many industry leaders have been using to power business-critical workloads for many years. It also fits nicely within the AWS ecosystem, making it super easy to get started, integrate with other AWS products, and stick with it as your company grows.
But (hopefully!), there comes a time when your organization scales quite significantly. With massive growth, costs become a natural concern for most companies out there, and DynamoDB is fairly often cited as one of the primary reasons for runaway bills due to its pay per operations service model.
You’re probably thinking: Oh, this is yet another post trying to convince me that DynamoDB costs are too high, and I should switch to your database, which you’ll claim is less expensive”.
Hah! Smart guess, but wrong. Although costs are definitely an important consideration when selecting a database solution (and ScyllaDB does offer quite impressive price-performance vs DynamoDB), it is not always the most critical consideration. In fact, many times, switching databases is often seen as an “open-heart surgery”: something you never want to experience – and certainly not more than once.
If costs are a critical consideration for you, there are plenty of other resources you can review. To name a few:
- ScyllaDB vs. DynamoDB Benchmark: Comparing Price Performance Across Workloads
- Alex Debrie’s article on How you should think about DynamoDB costs
- Tobias Schmidt’s very comprehensive Amazon DynamoDB Pricing Explained
But let’s switch the narrative, and discuss other aspects you should consider when deciding whether to shift away from DynamoDB.

DynamoDB Throttling
Throttling in any context is no fun. Seeing a ProvisionedThroughputExceededException makes people angry. If you’ve seen it, you’ve probably hated it and learned to live with it. Some may even claim they love it after understanding it thoroughly.
There are a variety of ways you can become a victim of DynamoDB throttling. In fact, it happens so often that AWS even has a dedicated troubleshooting page for it. One of the recommendations here is “switch to on-demand mode” before actually discussing evenly distributed access patterns.
The main problem with DynamoDB’s throttling is that it considerably harms latencies. Workloads with a Zipfian distribution are prone to it… and the results achieved in a recent benchmark aren’t pretty:
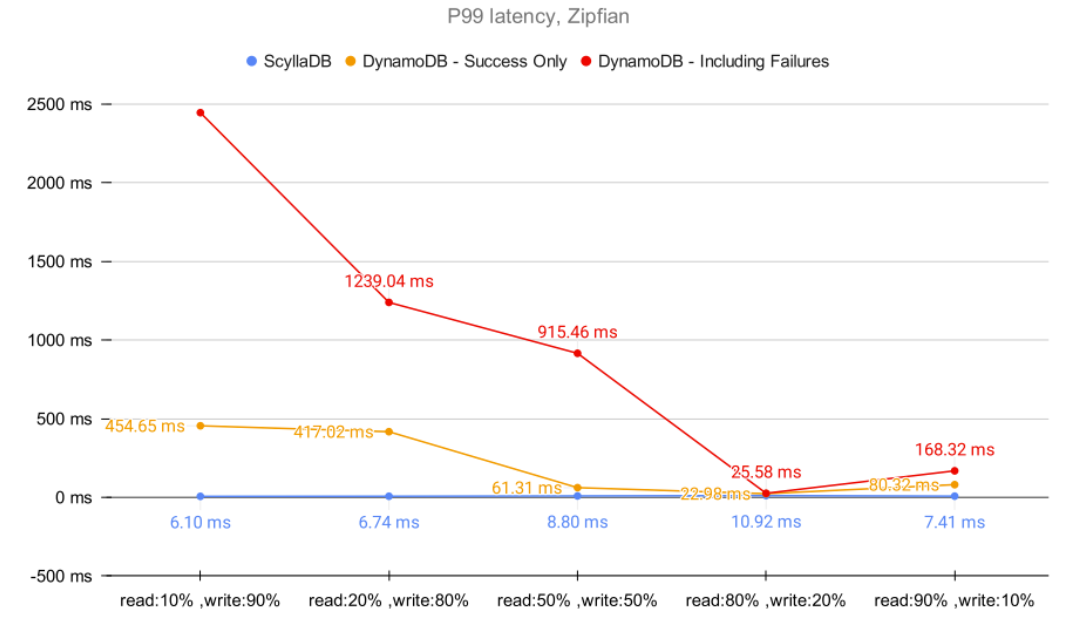
ScyllaDB versus DynamoDB – Zipfian workload
During that benchmark, it became apparent that throttling could cause the affected partition to become inaccessible for up to 2.5 seconds. That greatly magnifies your P99 tail latencies.
While it is true that most databases have some built-in throttling mechanism, DynamoDB throttling is simply too aggressive. It is unlikely that your application will be able to scale further if it happens to frequently access a specific set of items crossing the DynamoDB partition or table limits.
Intuition might say: “Well, if we are hitting DynamoDB limits, then let’s put a cache in front of it!” Okay, but that will also eventually throttle you down. It is – in fact – particularly hard to find hard numbers on DynamoDB Accelerator’s precise criteria for throttling, which seems primarily targeted to CPU utilization (which isn’t the best criteria for load shedding).
DynamoDB Latency
You may argue that the Zipfian distribution shown above targets DynamoDB’s Achilles heel, and that the AWS solution is a better fit for workloads that follow a uniform type of distribution. We agree. We’ve also tested DynamoDB under that assumption:
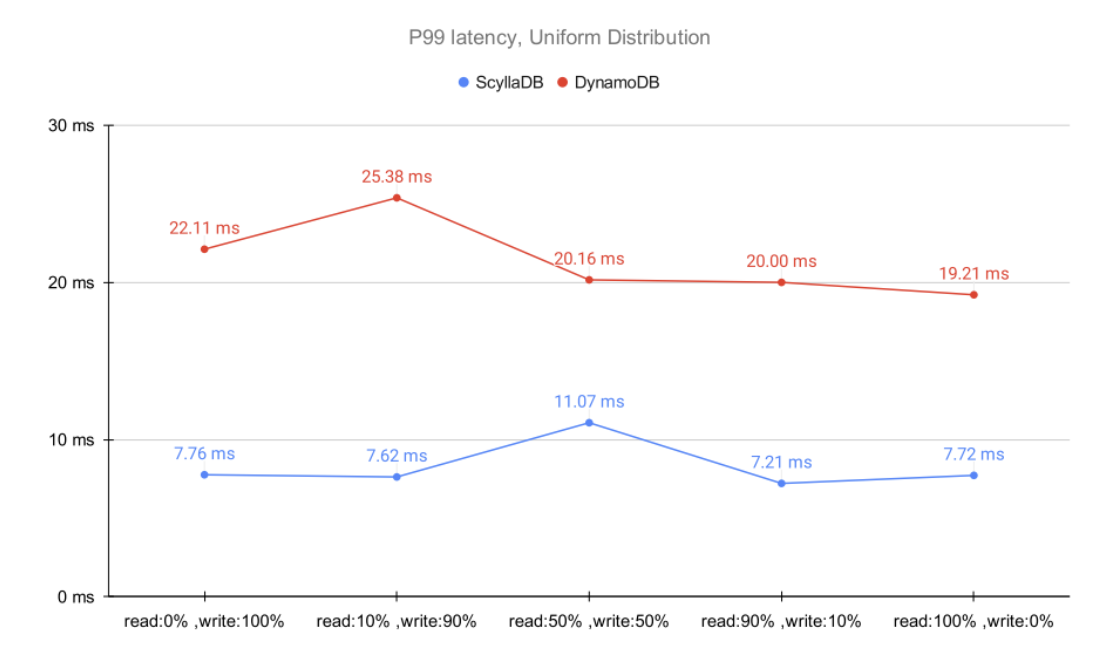
ScyllaDB versus DynamoDB – Uniform distribution
Even within DynamoDB’s sweet spot, P99 latencies are considerably higher compared to ScyllaDB across a variety of scenarios.
Of course, you may be able to achieve lower DynamoDB latencies than the ones presented here. Yet, DynamoDB falls short when required to deliver higher throughputs, causing latencies to eventually start to degrade.
One way to avoid such spikes is to use DynamoDB Accelerator (or any other caching solution, really) for a great performance boost. As promised, I’m not going to get into the cost discussion here, but rather point out that DynamoDB’s promised single-digit millisecond latencies are harder to achieve in practice.
To learn more about why placing a cache in front of your database is often a bad idea, you might want to watch this video on Replacing Your Cache with ScyllaDB.
DynamoDB Item Size Limits
Every database has an item size limit, including DynamoDB. However, the 400KB limit may eventually become too restrictive for you. Alex DeBrie sheds some light on this and thoroughly explains some of the reasons behind it in his blog on DynamoDB limits:
“So what accounts for this limitation? DynamoDB is pointing you toward how you should model your data in an OLTP database.
Online transaction processing (or OLTP) systems are characterized by large amounts of small operations against a database. (…) For these operations, you want to quickly and efficiently filter on specific fields to find the information you want, such as a username or a Tweet ID. OLTP databases often make use of indexes on certain fields to make lookups faster as well as holding recently-accessed data in RAM.”
While it is true that smaller payloads (or Items) will generally provide improved latencies, imposing a hard limit may not be the best idea. ScyllaDB users who decided to abandon the DynamoDB ecosystem often mention this limit, positioning it as a major blocker for their application functionality.
If you can’t store such items in DynamoDB, what do you do? You likely come up with strategies such as compressing the relevant parts of your payload or storing them in other mediums, such as AWS S3. Either way, the solution becomes sub-optimal. Both introduce additional latency and unnecessary application complexity.
At ScyllaDB, we take a different approach: A single mutation can be as large as 16 MB by default (this is configurable). We believe that you should be able to decide what works best for you and your application. We won’t limit you by any means.
Speaking of freedom: Let’s talk about …
DynamoDB’s Limited Freedomlexibility
This one is fairly easy.
DynamoDB integrates perfectly within the AWS ecosystem. But that’s precisely where the benefit ends. As soon as you engage in a multi-cloud strategy or decide to switch to another cloud vendor, or maybe fallback to on-prem (don’t get me started on AWS Outposts!), you will inevitably need to find another place for your workloads.
Of course, you CANNOT predict the future, but you CAN avoid future problems. That’s what differentiates good engineers from brilliant ones: whether your solution is ready to tackle your organization’s growing demands.
After all, you don’t want to find yourself in a position where you need to learn a new technology, change your application, perform load testing in the new DBMS, migrate data over, potentially evaluate several vendors… Quite often, that can become a multi-year project depending on your organization size and the number of workloads involved.
DynamoDB workloads are naturally a good fit for ScyllaDB. More often than not, you can simply follow the very same data modeling you already have in DynamoDB and use it on ScyllaDB. We even have ScyllaDB Alternator – an open source DynamoDB compatible API – to allow you to migrate seamlessly if you want to continue using the same API to communicate with your database, thus requiring fewer code changes.
Final Remarks
Folks, don’t get me started on DynamoDB… is a nice Reddit post you may want to check out. It covers a number of interesting real-life stories, some of which touch on the points we covered here. Despite the notorious community feedback, it does include a fair list of other considerations you may want to be aware of before you stick with DynamoDB.
Still, the first sentence of this article remains true: I love DynamoDB. It is a great fit and an economical solution when your company or use case has low throughput requirements or isn’t bothered by some unexpected latency spikes.
As you grow, data modeling and ensuring you do not exceed DynamoDB’s hard limits can become particularly challenging. Plus you’ll be locked in, and may eventually require considerable effort and planning if your organization’s direction changes.
When selecting a database, it’s ultimately about choosing the right tool for the job. ScyllaDB is by no means a replacement for each and every DynamoDB use case out there. But when a team needs a NoSQL database for high throughput and predictable low latencies, ScyllaDB is invariably the right choice.



