



Cassandra Data Model FAQs
What is a Cassandra Data Model?
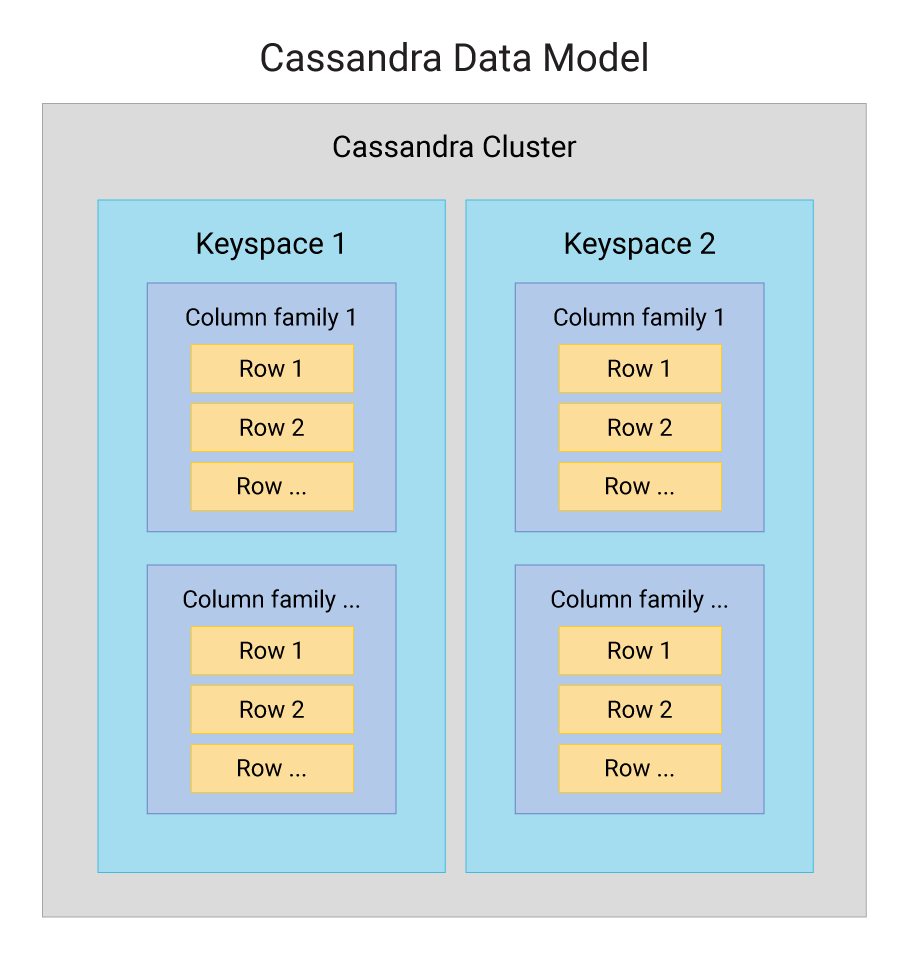
A Cassandra database is distributed across machines operating in tandem. Cassandra assigns data to nodes in the outermost container in a ring cluster: the Keyspace. Each node contains a replica that takes charge in case of failure handling.
Data modeling involves identifying items to be stored or entities and the relationships between them. Data modeling in Cassandra follows a query-driven approach, organizing data based on specific queries.
The design of Cassandra’s database is based on fast read and write requirements, so the speed of data retrieval improves with schema design. Queries select data from tables; query patterns define example user phrases and schema defines how table data is arranged.
In contrast, relational databases write the queries that will be made only after normalizing data based on the relationships and tables designed. Unlike the query-driven Cassandra approach, data modeling in relational databases is table-driven. The database expresses relationships between tables in queries as table joins.
The Cassandra data model offers tunable consistency, or the ability for the client application to choose how consistent the requested data must be for any given read or write operation. Tuning consistency is a factor in latency, but it is not part of the formal data modeling process.Find Cassandra data model documentation here.
Cassandra Keyspaces
In Cassandra, a Keyspace has several basic attributes:
- Column families: Containers of rows collected and organized that represent the data’s structure. There is at least one column family in each keyspace and there may be many.
- Replication factor: The number of cluster machines that receive identical copies of data.
- Replica placement strategy: Analogous to a load balancing algorithm, this is simply the strategy for placement of replicas in the ring cluster. There are rack-aware strategies and datacenter-shared strategies.
Cassandra Primary Keys
Each Cassandra table must have a primary key, a set of columns. (This is why tables were called column families in past iterations of Cassandra.) The primary key shapes the table’s data structure and determines the uniqueness of a row.
There are two parts to the Cassandra primary key:
Partition key: The primary key is the required first column or set of columns. The hashed partition key value determines where in the cluster the partition will reside.
Clustering key: Also called clustering columns, clustering keys are optional columns after the partition key. The clustering key determines the order of rows sort themselves into within a partition by default.

Learn Cassandra data modeling stratgies from Discord’s Bo Ingram in this free on-demand masterclass
What are Cassandra Data Model Design Best Practices?
The overall aim of Cassandra data modeling and analysis is to develop an organized, complete, high-performance Cassandra cluster. Wide column data modeling best practices for Cassandra-API-compatible databases like ScyllaDB are also applicable to Cassandra.
Cassandra Data Modeling: Query-Centered Design
Avoid trying to use Apache Cassandra like a relational database. Aim for query-centered design, and define how data tables will be accessed at the beginning of the data modeling process. Cassandra does not support derived tables or joins so denormalization is critical to Cassandra table design.
The first step in Advanced Cassandra data modeling and analysis is reviewing data access patterns and requirements. The Cassandra data model differs significantly from the standard RDBMS model in that the data model is based around the queries and not just around the domain entities.
Designing a Cassandra database for optimal storage is different than with relational databases, because it is important to optimize data distribution around the cluster. And sorting can be done only as specified in the primary key on the clustering columns, so in Cassandra or any similar NoSQL database, sorting is a design decision.
Selecting an Effective Partition Key
As a distributed database, Cassandra becomes more efficient when data is grouped together on nodes by partition for reads and writes. Response time improves as fewer partitions that must be queried to get an answer to a question, the faster the response.
By hashing a data attribute called partition key, Cassandra groups incoming data into discrete partitions and distributes them among cluster nodes. A successful Cassandra data model selects a partition key that:
- Evenly distributes data across cluster nodes; and
- Minimizes partitions accessed in a single query read
How to Design Cassandra Data Models to Meet Data Distribution Goals
A good Cassandra data model evenly distributes data across cluster nodes, limits partition size, and minimizes the query returns.
Avoid hot spots—where some nodes experience excessive load while others remain idle—and ensure even data distribution around the Cassandra cluster by the model by selecting a partition key with high cardinality. Enhance performance and limit partition size by keeping partition keys between 10 and 100MB with bounds on the possible values. And because reading many partitions at once is costly, it’s ideal for each query to read a single partition.
It is important to the development process to ensure that partition keys have a bounded range of values, distribute data evenly across cluster nodes, and adhere to any restrictive search conditions that affect design.
Cassandra Data Model Examples
Cassandra data modeling focuses on the queries.
Consider crime statistics as an example of how to model the Cassandra table schema to handle specific queries. One basic query (Q1) for crime statistics is a list of murder rates by state, including each state’s name and the recorded murder rate. Each state’s murder rate is uniquely identified in the table, and data can be pulled based on simple queries. A related query (Q2) searches for all states within a category—say, those with murder rates higher than a certain level.
It is essential to consider entities and their relationships during table design. All entities involved in a relationship that a query touches on must be in a single table, since queries are designed to access just one table most effectively. Tables may involve a single entity and its attributes or multiple entities and their attributes.
Cassandra queries can be performed more rapidly because the database uses a single table approach, in contrast to the relational database strategy which stores data in multiple tables and relates it between them using foreign keys.
Cassandra Data Modeling Resources
Three top resources for learning more about Cassandra data modeling include:
Wide Column Store NoSQL vs SQL Data Modeling video: NoSQL schemas are designed with very different goals in mind than SQL schemas. Where SQL normalizes data, NoSQL denormalizes. Where SQL joins ad-hoc, NoSQL pre-joins. And where SQL tries to push performance to the runtime, NoSQL bakes performance into the schema. Join us for an exploration of the core concepts of NoSQL schema design, using ScyllaDB as an example to demonstrate the tradeoffs and rationale.
Data Modeling and Application Development training course: This is an intermediate level course that explains basic and advanced data modeling techniques including information on workflow application, query analysis, denormalization and other NoSQL data modeling topics. After completing this course, you will be able to perform workflow application and query analysis, explain commonly used data types, understand collections and UDTs, and understand denormalization.
Data Modeling Best Practices: Migrating SQL Schemas for Wide Column NoSQL: To maximize the benefits of Cassandra or ScyllaDB, you must adapt the structure of your data. Data modeling for wide column databases should be query-driven based on your access patterns– a very different approach than normalization for SQL tables. In this video, you will learn how tools can help you migrate your existing SQL structures to accelerate your digital transformation and application modernization.
Cassandra Data Modeling Tools
There are several tools that can help manage and design a Cassandra data modeling framework and build queries based on Cassandra data modeling best practices.
Hackolade is a Cassandra data modeling tool that supports schema design for many NoSQL databases. It supports multiple data types including UDTs and collections and unique CQL concepts such as clustering columns and partition keys. It also lets you capture the database schema with a Chebotko diagram.
Kashlev Data Modeler is a Cassandra data modeling tool that automates the Cassandra data modeling principles described in the Cassandra data model documentation, including schema generation, logical, conceptual, and physical data modeling, and identifying access patterns. It also includes model design patterns.
Various CQL plugins for several Integrated Development Environments (IDEs) exist, such as Apache NetBeans and IntelliJ IDEA. Generally, these plugins offer query execution, schema management, and other features. Some Cassandra tools and IDEs do not natively support CQL, and instead use a JDBC/ODBC driver to access and interact with Cassandra. When choosing Cassandra data model tools, ensure they support CQL and reinforce best practices for Cassandra data modeling techniques as presented in the Cassandra data model documentation.
Does ScyllaDB Support Cassandra Data Modeling?
ScyllaDB is a modern high-performance NoSQL wide column store database that is API-compatible with Apache Cassandra. ScyllaDB supports core Cassandra models, with the benefit of deep architectural advancements that increase performance while reducing maintenance, overhead, and costs.
Cassandra was revolutionary when it first debuted in 2008, leading to its broad adoption. However, more than a decade later, many companies have recognized its underlying limitations and have now moved on. Leading companies such as Discord, Comcast, Fanatics, Expedia, Samsung, and Rakuten have replaced Cassandra with ScyllaDB. ScyllaDB delivers on the original vision of NoSQL — without the architectural downsides associated with Apache Cassandra (or the costs at volume of databases like Amazon DynamoDB). ScyllaDB is built with deep knowledge of the underlying Linux operating system and architectural advancements that enable consistently high performance at extreme scale.
Access white papers, benchmarks, and engineer perspectives on ScyllaDB vs Apache Cassandra.
Cassandra Data Model FAQs
What is Cassandra data model design?
Cassandra data model design is the process of defining tables based on your application’s query patterns. Unlike SQL, you design for how you read data, not how it relates — this is called query-centered design.
How does a Cassandra NoSQL data model differ from a relational database?
The Cassandra NoSQL data model uses wide-column storage with no joins. Data is denormalized and duplicated across tables to support specific queries, enabling horizontal scalability and low-latency access at scale.
Where can I find Cassandra data model documentation?
Official Cassandra data model documentation is maintained by the Apache Cassandra project at cassandra.apache.org, covering keyspace design, primary key selection, and CQL table definitions.