




Dealing with infrastructure costs typically isn’t high on an R&D team’s priority list. But these aren’t typical times, and lowering costs is unfortunately yet another burden that’s now being placed on already overloaded teams.
For those responsible for data-intensive applications, reducing database costs can be a low-hanging fruit for significant cost reduction. If you’re managing terabytes to petabytes of data with millions of read/write operations per second, the total cost of operating a highly-available database and keeping it humming along can be formidable – whether you’re working with open source database on-prem, fully-managed database-as-a-service, or anything in between. Too many teams have been sinking too much into their databases. But, looking on the bright side, this means there’s a lot to be gained by rethinking your database strategy.
For some inspiration, here’s a look at how several dev teams significantly reduced database costs while actually improving database performance.
Comcast: 60% Cost Savings by Replacing 962 Cassandra Nodes + 60 Cache Servers with 78 ScyllaDB Nodes
“We reduced our P99, P999, and P9999 latencies by 95%–resulting in a snappier interface while reducing CapEx and OpEx.” – Phil Zimich, Senior Director of Engineering at Comcast
Comcast is a global media and technology company with three primary businesses: Comcast Cable (one of the United States’ largest video, high-speed internet, and phone providers to residential customers), NBCUniversal, and Sky.
Challenge
Comcast’s Xfinity service serves 15M households with 2B+ API calls (reads/writes) and 200M+ new objects per day. Over the course of 7 years, the project expanded from supporting 30K devices to over 31M devices.
They first began with Oracle, then later moved to Apache Cassandra (via DataStax). When Cassandra’s long tail latencies proved unacceptable at the company’s rapidly-increasing scale, they began exploring new options. In addition to lowering latency, the team also wanted to reduce complexity. To mask Cassandra’s latency issues from users, they placed 60 cache servers in front of their database. Keeping this cache layer consistent with the database was causing major admin headaches.
Solution
Moving to ScyllaDB enabled Comcast to completely eliminate the external caching layer, providing a simple framework in which the data service connected directly to the data store. The result was reduced complexity and higher performance, with a much simpler deployment model.
Results
Since ScyllaDB is architected to take full advantage of modern infrastructure — allowing it to scale up as much as scale out — Comcast was able to replace 962 Cassandra nodes with just 78 nodes of ScyllaDB.
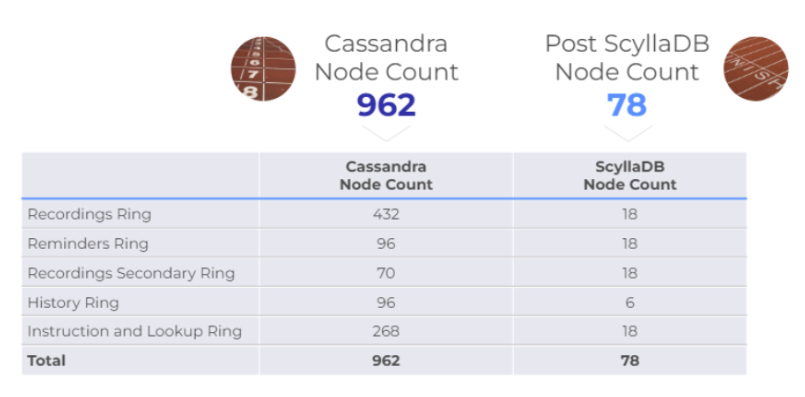
They improved overall availability and performance while completely eliminating the 60 cache servers. The result: a 10x latency improvement with the ability to handle over twice the requests – at a fraction of the cost. This translates to 60% savings over Cassandra operating costs – saving $2.5M annually in infrastructure costs and staff overhead.
Rakuten: 2.5x Lower Infrastructure Costs From a 75% Node Reduction
“Cassandra was definitely horizontally scalable, but it was coming at a stiff cost. About two years ago, we started internally realizing that Cassandra was not the answer for our next stage of growth.” – Hitesh Shah, Engineering Manager at Rakuten
Rakuten allows its 1.5B members to earn cash back for shopping at over 3,500 stores. Stores pay Rakuten a commission for sending members their way, and Rakuten shares that commission with its members.
Challenge
Rakuten Catalog Platform provides ML-enriched catalog data to improve search, recommendations, and other functions to deliver a superior user experience to both members and business partners. Their data processing engine normalizes, validates, transforms, and stores product data for their global operations.
While the business was expecting this platform to support extreme growth with exceptional end-user experiences, the team was battling Apache Cassandra’s instability, inconsistent performance at scale, and maintenance overhead. They faced JVM issues, long Garbage Collection (GC) pauses, and timeouts – plus they learned the hard way that a single slow node can bring down the entire cluster.
Solution
Rakuten replaced 24 nodes of Cassandra with 6 nodes of ScyllaDB. ScyllaDB now lies at the heart of their core technology stack, which also involves Spark, Redis, and Kafka. Once data undergoes ML-enrichment, it is stored in ScyllaDB and sent out to partners and internal customers. ScyllaDB processes 250M+ items daily, with a read QPS of 10k-15k per node and write QPS of 3k-5k per node.
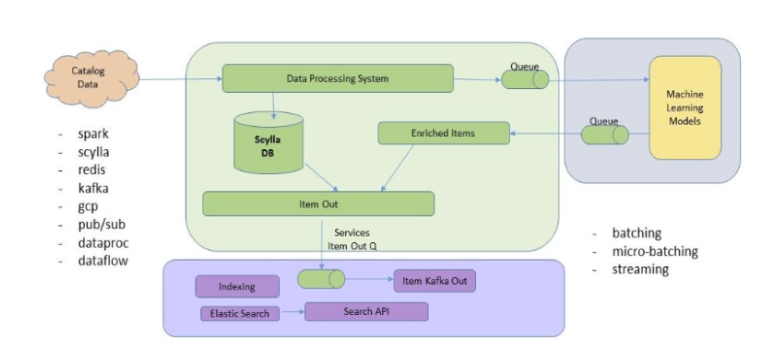
One ScyllaDB-specific capability that increases Rakuten’s database cost savings is Incremental Compaction Strategy (ICS). ICS allows greater disk utility than standard Cassandra compaction strategies, so the same amount of total data requires less hardware. With traditional compaction strategies, users need to set aside half of their total storage for compaction. With ICS, Rakuten can use 85% or more of their total storage for data, enabling far better hardware utilization.
Results
Rakuten can now publish items up to 5x faster, enabling faster turnaround for catalog changes. This is especially critical for peak shopping periods like Black Friday. They are achieving predictably low latencies, which allows them to commit to impressive internal and external SLAs. Moreover, they are enjoying 2.5x lower infrastructure costs following the 4x node reduction.
Expedia: 35% Cost Savings by Replacing Redis + Cassandra
“We no longer have to worry about ‘stop-the-world’ garbage collection pauses. Also, we are able to store more data per node and achieve more throughput per node, thereby saving significant dollars for the company.” – Singaram Ragunathan, Cloud Data Architect at Expedia Group
Expedia is one of the world’s leading full-service online travel brands helping travelers easily plan and book their whole trip with a wide selection of vacation packages, flights, hotels, vacation rentals, rental cars, cruises, activities, attractions, and services.
Challenge
One of Expedia’s core applications provides information about geographical entities and the relationships between them. It aggregates data from multiple systems, like hotel location info, third-party data, etc. This rich geography dataset enables different types of data searches using a simple REST API with the goal of single-digit millisecond P99 read response time.
The team was using a multilayered approach with Redis as a first cache layer and Apache Cassandra as a second persistent data store layer, but they grew increasingly frustrated with Cassandra’s technical challenges. Managing garbage collection and making sure it was appropriately tuned for the workload at hand required significant time, effort, and expertise. Also, burst traffic and workload peaks impacted the P99 response time – requiring buffer nodes to handle peak capacity, which drove up infrastructure costs.
Solution
The team migrated from Cassandra to ScyllaDB without modifying their data model or application drivers. As Singaram Ragunathan, Cloud Data Architect at Expedia Group put it: “From an Apache Cassandra code base, it’s frictionless for developers to switch over to ScyllaDB. There weren’t any data model changes necessary. And the ScyllaDB driver was compatible, and a swap-in replacement with Cassandra driver dependency. With a few tweaks to our automation framework that provisions an Apache Cassandra cluster, we were able to provision a ScyllaDB cluster.”
Results
With Cassandra, P99 read latency was previously spiky, varying from 20 to 80 ms per day. With ScyllaDB, it’s consistently around 5 ms. ScyllaDB throughput is close to 3x Cassandra’s. Moreover, ScyllaDB is providing 35% infrastructure cost savings.

iFood: Moving Off DynamoDB to Scale with 9X Cost Savings
“One thing that’s really relevant here is how fast iFood grew. We went from 1M orders a month to 20M a month in less than 2 years.” – Thales Biancalana, Backend Developer at iFood
iFood is the largest food delivery company in Latin America. It began as a Brazilian startup, and has since grown into the clear leader, with a market share of 86%. After becoming synonymous for ‘food delivery’ in Brazil, iFood expanded its operations into Columbia and Mexico.
Challenge
The short answer: online ordering at scale, with PostgreSQL as well as DynamoDB.
Each online order represents about 5 events in their database, producing well over 100M events on a monthly basis. Those events are sent to restaurants via the iFood platform, which uses SNS and SQS. Since internet connections are spotty in Brazil, they rely on an HTTP-based polling service that fires off every 30 seconds for each device. Each of those polls invokes a database query.
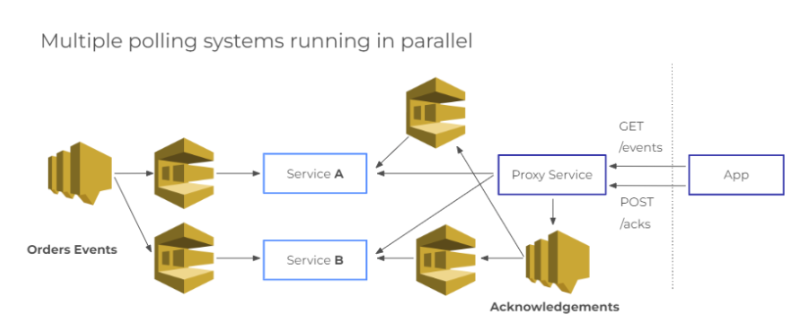
After they hit 10 million orders a month and were impacted by multiple PostgreSQL failures, the team decided to explore other options. They moved to NoSQL and selected DynamoDB for their Connection-Polling service. They quickly discovered that DynamoDB’s autoscaling was not fast enough for their use case. iFood’s bursty intraday traffic naturally spikes around lunch and dinner times. Slow autoscaling meant that they could not meet those daily bursts of demand unless they left a high minimum throughput (which was expensive) or managed scaling themselves (which is work that they were trying to avoid by paying for a fully-managed service).
Solution
iFood transitioned their Connection-Polling service to ScyllaDB Cloud. They were able to keep the same data model that they built when migrating from PostgreSQL to DynamoDB. Even though DynamoDB uses a document-based JSON notation, and ScyllaDB used the SQL-like CQL, they could use the same query strategy across both.
Results
iFood’s ScyllaDB deployment easily met their throughput requirements and enabled them to reach their mid-term goal of scaling to support 500K connected merchants with 1 device each. Moreover, moving to ScyllaDB reduced their database expenses for the Connection-Polling service from $54k to $6K — a 9x savings.
Wrap Up
These examples are just the start. There are quite a few ways to reduce your database spend:
- Improve your price-performance with more powerful hardware – and a database that’s built to squeeze every ounce of power out of it, such as ScyllaDB’s highly efficient shard-per-core architecture and custom compaction strategy for maximum storage utilization.
- Reduce admin costs by simplifying your infrastructure (eliminating external caches, reducing cluster size, or moving to a database that requires less tuning and babysitting).
- Tap technologies like workload prioritization to run OLTP and OLAP workloads on the same cluster without sacrificing latency or throughput.
- Consider DBaaS options that allow flexibility in your cloud spend rather than lock you into one vendor’s ecosystem.
- Move to a DBaaS provider whose pricing is better aligned with your workload, data set size, and budget (compare multiple vendors’ prices with this DBaaS pricing calculator).
And if you’d like advice on which – if any – of these options might be a good fit for your team’s particular workload, use case, and ecosystem, our architects would be happy to provide a technical consultation.



