




There are literally dozens upon dozens of NoSQL databases available these days. A lot of choices for users to consider. Yet databases are not all built the same. There are times when you are looking to build specifically for high performance and high scalability — to the tune of hundreds of thousands or millions of operations per second. What criteria do you use to short list a database to consider for your specific use case?
In our most recent Masterclass, hosted in partnership between the database experts at ScyllaDB, the fastest NoSQL Database, and Pythian, we dove into the factors for decision-making, and made the case for wide column NoSQL databases. How and why they are used for modern high performance applications? How do you get the most out of a wide column database?
The Case for Wide Column NoSQL
I was the host for the first session: A Survey of High Performance NoSQL Systems. I began by looking at the most popular databases these days — SQL, NoSQL, and so-called “multimodel” databases that can be a mix of both SQL and NoSQL, or multiple NoSQL data models. Then, I broke down the various most popular types of NoSQL data models these days — key value stores, document databases, graph and wide column.
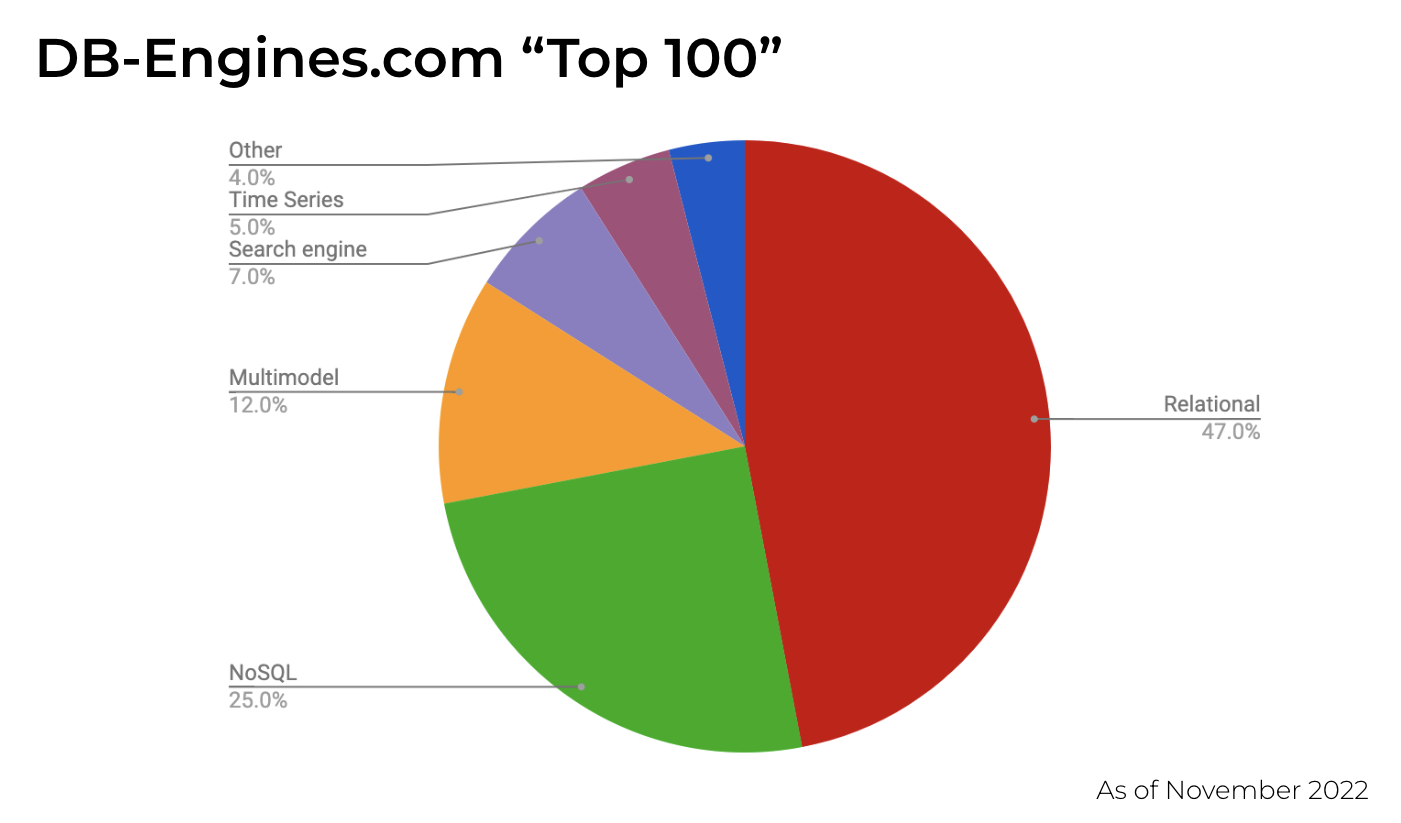
Once laying out that orientation I made the case for using wide column NoSQL databases, such as Apache Cassandra or ScyllaDB, for high performance use cases. What attributes and capabilities do they provide that make them ideally suited for massive scale out, and, in the case of ScyllaDB, scale up as well?
Modeling Data and Queries for Wide Column NoSQL
Next up was Pythian’s lead database consultant Allan Mason. His session focused on how to be successful with wide column NoSQL by understanding the nature of its data model and query structure. While many users are familiar with Structured Query Language (SQL) popular across RDBMS systems, Cassandra Query Language (CQL) is deceptively similar but fundamentally different. With RDBMS, you usually begin with a schema-first design. With a wide column database like ScyllaDB or Cassandra, you begin with a query-first design. Then, step-by-step, Allan showed how to model tables around your query patterns.

Scaling for Performance
The third session was hosted by ScyllaDB Solutions Architect and author Felipe Cardeneti Mendes. His session was focused on the features and capabilities that let you scale for your specific use case. From how to do workload prioritization to balance read-write workloads of OLTP and read-heavy workloads of OLAP in the same cluster, to how to select the right compaction strategy to match your workload.

Felipe also covered aspects of deployment and production readiness, reinforcing the points made in Allan’s talk about data modeling, but also including testing, application design, sizing and observability.
A Winning Formula: ScyllaDB’s Masterclass Format
This is the third of a series of Masterclasses we offered over the course of 2022. Prior Masterclass sessions included the Distributed Data System Masterclass in partnership with StreamNative, and the Performance Engineering Masterclass, which we hosted in conjunction with Grafana k6 and Dynatrace. For those who have not attended one of our Masterclasses before, the format is as follows:
- Three expert video presentations, grounding you in the topic
- A live panel talk between the three experts, where you can ask questions
- A test, which, if you pass, you can share your achievement on your LinkedIn profile
It’s more than a webinar or YouTube video, but short of a full tech conference in length. Plus, you can’t just bury the browser tab in the background and sort of half-listen. You need to be paying attention, because there is going to be a test!
Rest assured, if you don’t pass on the first try, we offer Masterclass attendees a chance to retake the test. With a careful re-watching of the materials you’ll find the correct answers were all covered in the materials presented.
This tough but fair test format has been key to the enthusiastic user response to the ScyllaDB Masterclass series. Users need to keep on their toes and stay engaged in the content. They feel challenged intellectually, and then have a chance to show that they’ve integrated the key lessons from the materials.
We look forward to hosting more Masterclass sessions in the future. If you have any ideas, feel free to join our user Slack and drop your ideas in the #events channel, or post your thoughts in a thread on our new user Forum.
Curious? Watch Now!
If you missed the live event, never fear! We have you covered. You can watch the High Performance NoSQL Masterclass now on demand. Totally online and totally free. Enjoy!




