




 Update: For the latest and greatest on how to test and benchmark database clusters, see Chapter 9 of Database Performance at Scale — a new 270 page book that’s available for free.
Update: For the latest and greatest on how to test and benchmark database clusters, see Chapter 9 of Database Performance at Scale — a new 270 page book that’s available for free.
The goal of that chapter is to share strategies that ease the pain slightly and, more importantly, increase the chances that the pain pays off by helping you select options that meet your performance needs. It begins by looking at the two key types of benchmarks and highlighting critical considerations for each objective. Then, it presents a phased approach that should help you expose problems faster and with lower costs. Next, it dives into the do’s and don’ts of benchmark planning, execution, and reporting, with a focus on lessons learned from the best and worst benchmarks we’ve witnessed over the past several years. Finally, the chapter closes with a look at some less common benchmarking approaches you might want to consider for specialized needs.
Also, you can access a free virtual masterclass on how to test and benchmark your database clusters on demand. Here, Dr. Daniel Seybold (benchANT) and Felipe Mendes discuss proven strategies that help you rightsize your performance testing infrastructure, account for the impact of concurrency, recognize and mitigate coordinated omission, and understand probability distributions.
***
In an archived webinar from 2020, VP of Solutions Eyal Gutkind and Solutions Architect Moreno Garcia presented on how users perform benchmarks and real-life workload simulations in their environments. Their roles require them to work closely with customers in early adoption — especially during Proof-of-Concepts (POC) and entering into production. They also have a wealth of experience in provisioning and sizing, as well as various migration strategies.
Eyal encouraged users to do benchmarking early in the inception of a project. “Benchmarking will help you fail fast and recover fast before it’s too late.”
Teams should always consider benchmarking as part of the acceptance procedure for any application. What is the overall user experience that you want to bake into the application itself? Ensure that you can support scaling your customer base without compromising user experience or the actual functionality of the app. Users should also consider their disaster recovery targets. Eyal suggested to ask yourself “How much infrastructure overhead am I willing to purchase in order to maintain the availability of my application in dire times?” And, of course, to think about the database’s impacts on the day-to-day lives of your DBAs.
1. Develop Tangible Targets
Eyal set forth the following considerations for your team to set tangible targets:
- What is the Use Case? — this should determine what database technology you are benchmarking. You have to choose databases that have dominant features to address the needs of your use case.
- Timeline for testing & deployment — Your timeline should drive your plans. What risks and delays may you be facing?
- MVP, medium, and long-term application scale — many times people just look at the MVP without considering the application lifecycle. “You’re not going to need 1,000 nodes on day one,” but not thinking ahead can lead to dead-end development. “Have a good estimate on the scaling that you need to support.”
- Budget for your database — both for your POC and your production needs. Overall application costs, including servers, software licenses, and manpower. Consider how some technologies can start out cheap, but do not scale linearly.
2. Create a Testing Schedule
“Scheduling is more than just install the servers and let’s go for it.” Eyal emphasized that your timeline needs to take into consideration getting consensus from the different stakeholders. Bringing them into the process. Deploying a service or servers might be as easy as the click of a button. But that doesn’t take into account any bureaucratic procedures you may need to bake into your schedule.
“Bake into your schedule the processes needed…. Also make sure you have the right resources to help you evaluate the system. Developers, DBAs, and systems administrators are limited resources in any organization. Make sure you schedule your testing with their availability in mind.”
To help organize your POC schedule, Eyal presented an example project plan. You can use this checklist for your own projects:
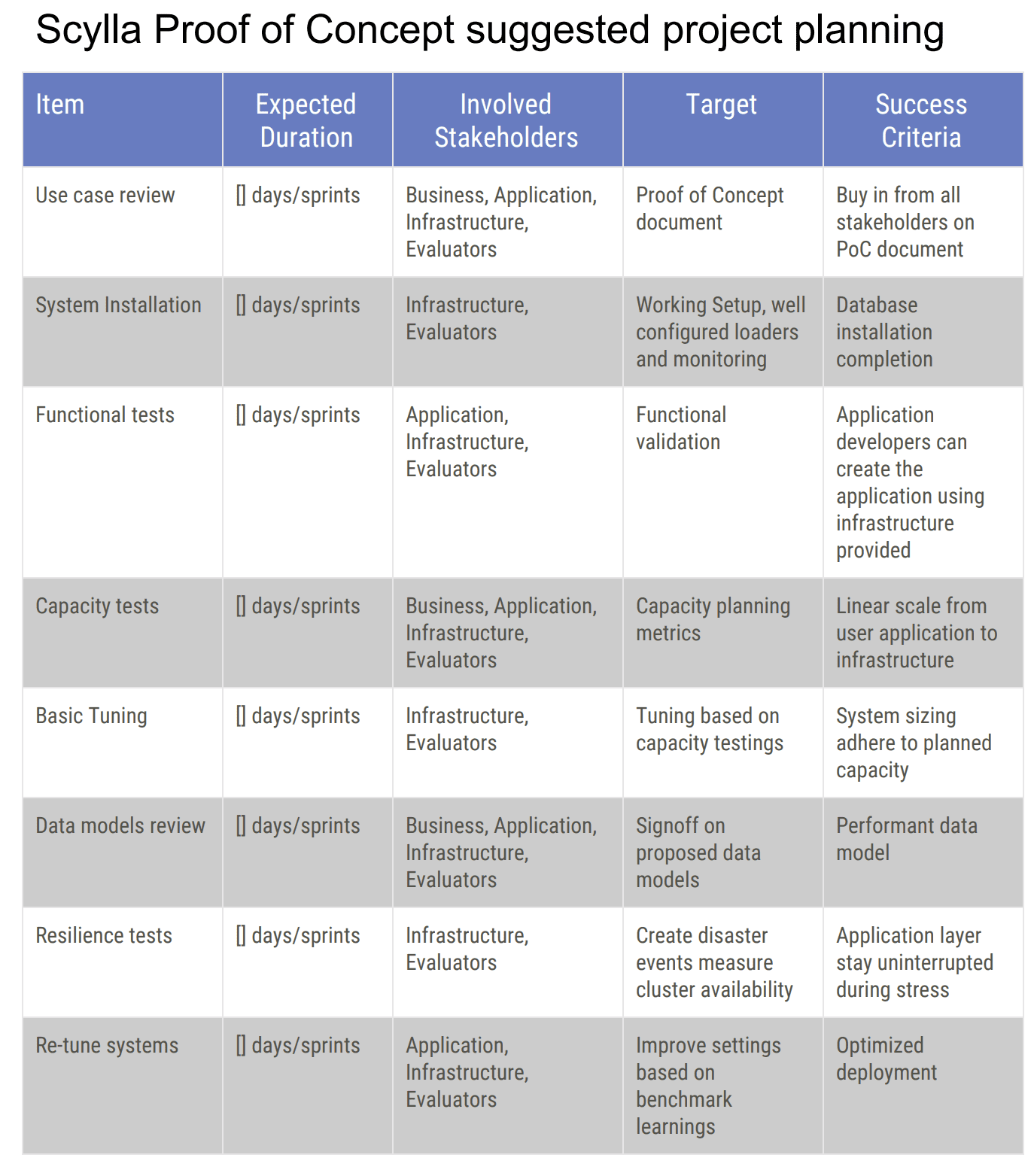
DOWNLOAD THE SCYLLA PROOF OF CONCEPT CHECKLIST
This is the checklist that every ScyllaDB user should follow in every proof of concept conducted. Eyal noted, “We’re taking into consideration many of the aspects that you sometimes do not think are part of the benchmarking, but does take a lot of resources and a lot of time from your perspective and from your team.”
3. Understand Data Patterns of Your Application
Data modeling itself can lead to many horror stories with benchmarking. Eyal cited an example of a user who tried to force a blob of one, two, or even five gigabytes into a single cell. Eyal suggested to keep only the metadata in the database, and put the actual object in storage outside of the database. Not only will this make better sense operationally, but also financially.
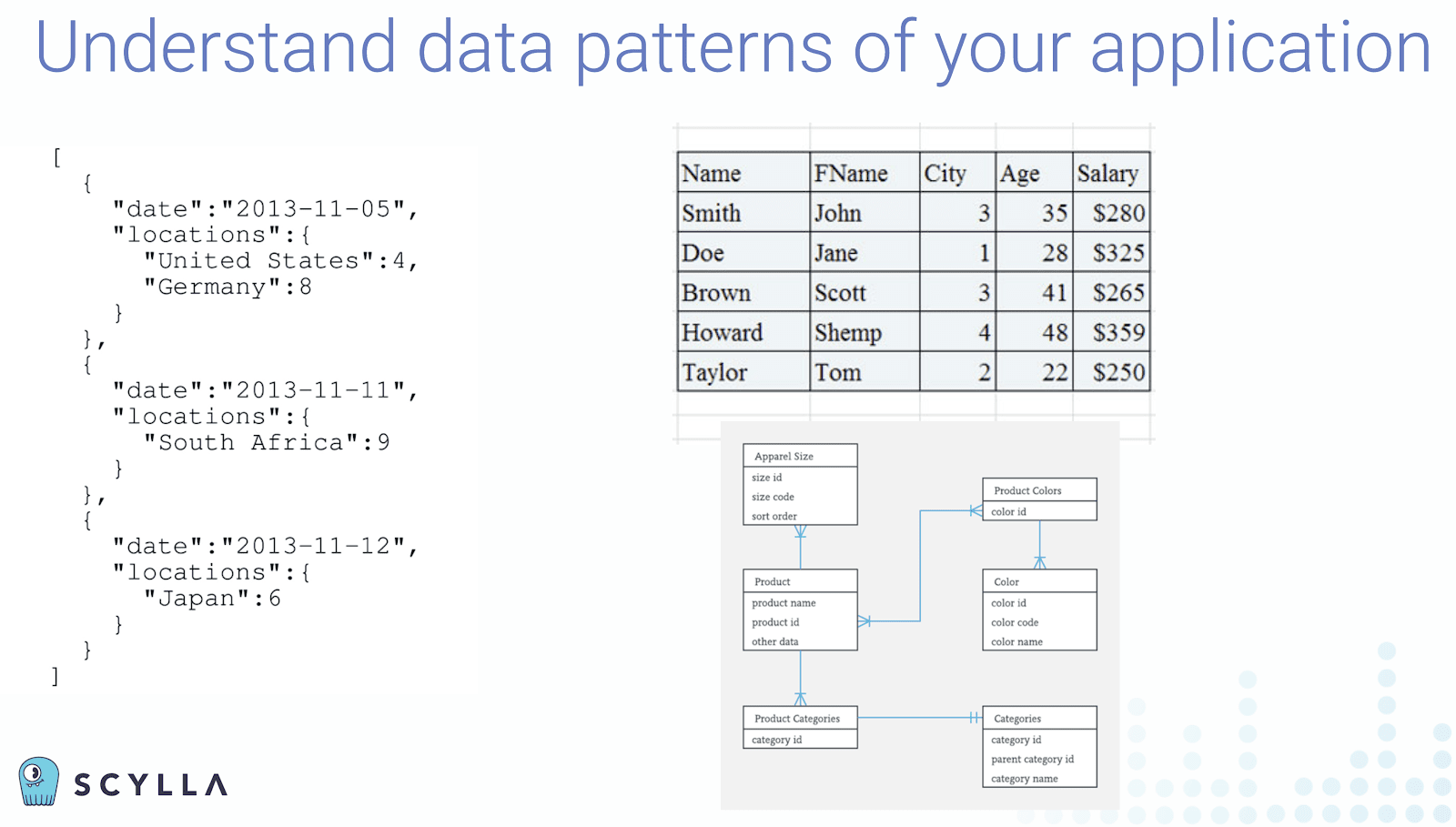
“Databases are optimized for certain data models and access patterns from your application.” Eyal suggested making sure that the application data can be easily stored and accessed. Also that the developers you have for the POC are trained on data modeling for the target database.
(Reminder, ScyllaDB offers a course in ScyllaDB University on both beginning and advanced data modeling. We can also arrange live training for your team if you wish. We also invite you to register for ScyllaDB Summit 2021, where we will have free online live training!)
Also, realize that not all benchmarking stressing tools have data modeling capabilities in them. Eyal suggested going beyond generic tests. If you have your own data model requirement and can benchmark your application with it, “That’s the best case.” He suggested looking at the synthetic tools to see if they were capable of data model modifications.
4. Benchmarking Hardware
Eyal also noted that, while it is understandable, many benchmarks fail because of underpowered testing environments; using hardware systems too small to provide an adequate test experience. Especially compared to what their production systems would be like. “Too many times we see evaluators trying to squeeze the life out of a dime.” These underpowered test systems can highly but unfairly bias your results. “Think about the amount of CPUs you’re going to give to the system.” To see a system’s benefits, and for a fair performance evaluation, “Don’t run it on a laptop.”
5. Stress Test Tools & Infrastructure
Make sure you have dedicated servers as stressing nodes executing the stressing tools like cassandra-stress and Yahoo Cloud Server Benchmark (YCSB). Because if you run the stress tools on the same server as the database, it can cause resource contentions and collisions. It also helps set up the test as realistically as possible.
In the same vein, use a realistic amount of data, to make sure you’re pushing and creating enough unique data. “There’s a huge difference in performance if you have only 10 gigabytes of data in the server or 10 terabytes. This is not an apples to apples comparison.” (We’ve been pointing out for many years how other databases do not scale linearly in performance.)
Eyal also suggested you look at the defaults that various stress tests use, and modify them for your use case where and if possible. “Let’s say cassandra-stress is doing a 300 byte partition key. That might not be representative of your actual workload. So you want to change that. You want to change how many columns are there, so on and so forth. Make sure that your stressing tool is representing your actual workload.”
6. Disaster Recovery Testing
“You need to test your ability to sustain regular life events. Nodes will crash. Disks will corrupt. And network cables will be disconnected. That will happen for sure, and I will tell you it always happens during peak times. It’s going to be on your Black Friday. It’s going to be during the middle of your game.” Things happen at exactly the wrong time. So you need to take disaster into account and test capacity planning with reduced nodes, a network partition, or other undesired events. This has the added benefit of teaching you about the true capabilities of resiliency of a system.
“The challenging task of coming alive back from a backup must be tested.” So you should also spend a little bit more time (and money) by testing a backup and restore process to see how fast and easy your restoration will be, and that restoration works properly.
7. Observability
Eyal urged the audience to ensure they understand the capabilities of their observability. “A powerful monitoring system is required for you to understand the database and system capabilities.” This allows you to understand the performance of your data model and your application efficiency. You can also discover data patterns.
Demonstration of nosqlbench
After this, Eyal turned the presentation over to Moreno Garcia, who took the audience through a demo of the nosqlbench stressing tool. You can watch it starting around the 18 minute mark in our on-demand webinar.
WATCH THE ON-DEMAND WEBINAR NOW
From POC to Production
Also, once you have finished with your POC you aren’t done yet! For the next steps of getting into production, you will need a checklist to make sure you are ready. Handily we prepared that for you!
If you have further questions about getting ready for your POC or your move to production, we’d welcome to hear your questions in our Slack channel, or feel free to reach out to contact us privately.







