




Implementing a file system is a complex task, but contrary to popular belief it is not equivalent to writing a kernel module and implementing the full API specified and standardized by POSIX, with hard links, 3 types of file locking mechanisms, extended attributes et al. In fact, any program or library which allows its users to have a notion of a “file,” which can be looked up, written to and read from, is already a file system. Today, file systems come in many varieties — some are distributed, some reside only in RAM, and a fair share of them are actually written in userspace. In this post, I’ll present the details of a student project sponsored by ScyllaDB, which resulted in creating a fully asynchronous log-structured file system, written from scratch in Seastar.
Intro: student projects
In 2019, ScyllaDB sponsored a program for Computer Science students organized by the University of Warsaw. Throughout the whole academic year, 3 teams of undergraduate students collaborated with and learned from ScyllaDB engineers to bring new features to ScyllaDB and its underlying Seastar engine. The projects picked for 2019 edition were:
- Parquet support for Seastar and ScyllaDB (see Part I)
- SeastarFS: an asynchronous userspace file system for Seastar (this post)
- Kafka client for Seastar and ScyllaDB (still to come!)
This blog post describes the progress on the SeastarFS project. This work is all to the credit of the students who wrote it, Krzysztof Małysa, Wojciech Mitros, Michał Niciejewski and Aleksandr Sorokin, and their supervisor, Dr. Jacek Sroka.
Motivation
Why write a file system from scratch? The first, most obvious reason is that it’s fun! In the case of SeastarFS, the following factors were also very important:
- Lack of alternatives. ScyllaDB has very specific latency requirements for file systems, and XFS was the only system so far that is considered good enough. ScyllaDB’s write path could benefit from a log-structured file system (more on that below), but no such system fulfills the requirements to a satisfactory degree.
- Overhead. Traditional file systems are implemented in the kernel, which means that a user is forced to use system calls to communicate with them. That created additional overhead which could be avoided by moving more work to userspace.
- Safety. Relying on third-party software is easy, but it comes with risks — a bug sneaking into XFS in the future could result in ruining latency guarantees, because the file system would no longer behave the same way as ScyllaDB expected it to. Providing our own implementation reduces the dependency on external projects.
- Control. Having a file system written 100% in Seastar, we’re able to:
- integrate with the Seastar scheduler by setting proper priority for each operation
- tightly control how much memory is used by the file system
- provide strict latency guarantees, since everything is written with Seastar asynchronous primitives
- gather valuable metrics in very specific places
- add debug code wherever we please, without recompiling the kernel
- Shard-awareness. Seastar is written in a shared-nothing design in mind, and using a centralized file system in the kernel does not fit well into that model.
- Completeness. Seastar is already inches away from being a full-fledged operating system. It has its own schedulers, memory management, I/O primitives, threads… the only thing missing is its own file system!
Interface
SeastarFS does not strive to be a general-purpose, POSIX-compliant file system. It’s a highly specialized project which aims to provide highest possible throughput and lowest latency under several assumptions:
- The files are large. While the system should work correctly on small files, it should be optimized for sizes counted in mega-, giga- and terabytes.
- No hot files or directories. Given the shared-nothing design of Seastar, the system expects multiple users to work on their own files, without having to share resources between many of them. While it should be possible to access any file by any user, the optimized path assumes there are no conflicts and each client works on its own files.
- Sequential read/write mostly. The system allows many convenient operations on files and directories (e.g. renaming files), but it expects the most common operation to be reading and writing long sequences — and they will be optimized even at the cost of making other operations, like a rename or a random write, slower.
Fortunately, ScyllaDB does just that – it mainly operates on large, append-only files (commitlogs and SSTables), and is already written in Seastar’s shared-nothing design.
The interface of SeastarFS is similar to what users can do on a POSIX-compliant system, but without all the esoteric features like extended attributes or in-system file locking. Here’s a draft interface of what a file can currently do in SeastarFS:
Log-structured file system
SeastarFS is a log-structured file system, which means that it stores its data and metadata in logs (duh). Traditional file systems usually keep their metadata and data in blocks allocated on a device. Writing a file to such a file system results in updating some on-disk metadata structures, allocating blocks for data and finally flushing the data to disk. Here’s a crude example of what could happen underneath, when a simple operation of writing 1000 bytes in the middle of a 500-byte file reaches the device:
- write 8 bytes at offset 672 // mtime (modification time) of file F is updated
- write 8 bytes at offset 608 // size of file F is updated
- write 512 bytes at offset 1036288 // the first block of F’s data is written
- write 8 bytes at offset 48 // file system’s metadata is updated: a new block was allocated
- write 488 bytes at offset 4518912 // the new, second block of F’s data is written
Disk accesses:
![]()
The main point is that even writing a single, consecutive stream of bytes results in many random writes reaching the storage device. That’s a suboptimal pattern even for modern NVMe drives, not to mention good old HDDs — for which the total time for performing an operation is Ls + x/T, where Ls is the seek latency, T is throughput and x is the number of bytes read/written. With Ls = 4ms and T = 500 MiB/s, the average time of writing 1,000 bytes in one chunk would be 4ms +2µs ≈ 4ms, while writing 1,000 bytes in batches of 100 at 10 different offsets would last around 10(4ms +0.2µs) ≈ 40ms, which clearly makes the seek latency a deciding factor. Even modern SSD disks prefer sequential access in large batches — especially if the operations are smaller than internal page sizes. Small operations means more work in case of reading, and faster device wear in case of writing, because internal SSD garbage collection needs to perform more work underneath — flash drives tend to erase with block granularity.
The problem stated in a paragraph above can be addressed by changing the way the file system stores both its data and metadata. For instance, imagine that the whole disk is divided into a relatively small number of fixed-size blocks (e.g. 16MiB), acting as logs. Now, each metadata operation sent to the file system is appended to one of such logs, always at the end. Respectively to the example above, updating metadata in such a system could look like this, assuming that the first free position in the log is at byte 376:
- write 16 bytes at offset 376 // mtime of file F is updated
- write 16 bytes at offset 384 // size of file F is updated
- write 16 bytes at offset 392 // a new block was allocated
Disk accesses so far:
![]()
Now, a similar idea can be applied for data:
- very small writes, with size comparable to the size of metadata entries, can be stored directly in the metadata log
- moderately small writes end up in a special log dedicated for medium writes
- large writes, with sizes bigger than blocks themselves, are simply split into blocks
Continuing our simplified example, a 1000B write ends up in one of the medium data logs:
![]()
What happens when a particular block used as a metadata log becomes full? Assuming that there are free blocks available in the system, a new block is allocated, and a “pointer” (which is just an on-disk offset) to this new log is appended to the old log as the last entry. That way, metadata logs create a linked list stored on disk. The list can be traversed later when booting the system.
Bootstrapping
SeastarFS, like any other file system, needs to be bootstrapped before it’s used — all the metadata needs to be verified and loaded to RAM. In order to be able to do that, a bootstrap record is created in a specific offset on the device — at first, it’s done by a helper program which formats the disk — just like mkfs does. The bootstrap record contains file system metadata, control sums, offsets of the metadata and data logs, and so on. When the system is started, it tries to load the structure from the specified offset (e.g. 0), and if it succeeds in verifying that the bootstrap record is genuine and consistent, all the metadata is loaded from the on-disk logs. The verification includes:
- checking a magic number, which is customary for file systems (e.g. XFS uses a 32-bit number which represents “XFSB” in ASCII);
- sanity-checking file system metadata: e.g. if a block size is larger than the device itself, something is probably off and we shouldn’t continue booting;
- loading the metadata from metadata logs, which includes verifying metadata checksums and various sanity checks.
Here’s how a bootstrap record looks like for SeastarFS:
Compactions
Log-structured file systems sound just great with their better device access patterns, but there’s a catch. Entries are always appended to the back of the log, but that also means that some stored information starts to be completely redundant. That wouldn’t be a problem if our disks were infinitely large or we never had to read the whole log when booting the system, but none of this is unfortunately true. Let’s see an example log (simplified):
- Create a file f in directory /, assign inode number F
- Update size of file F to 3
- Write “abc” to file F at offset 0
- Update size of file F to 7
- Write “defg” to file F at offset 3
- Truncate file F to size 0
- Rename file F from /f to /some/other/directory/g
- Remove file F
- Create a file h in directory /, assign inode number H
At the time of performing each of the 8 operations, its metadata entry makes a lot of sense and is needed to keep the information up-to-date. However, by the time we’re right after performing operation 6, operations 1-5 become obsolete. If the system is turned off right now and metadata is later restored from the log, it doesn’t matter whether something was temporarily written to the file, since its size is ultimately 0. Similarly, after reaching operation 8, operations 1-7 are not needed at all. That’s good news – an opportunity to reclaim some space. How to do that? We can’t just rewrite the log in place, because that would ruin the whole idea about avoiding random writes, and could also be a source of inconsistencies if the power runs out in the middle of a rewrite. What we can do is pick a new, empty log, rewrite only the meaningful part of the old log, and only then remove the old log. A compacted form of a log above looks like this:
- Create a file h in directory /, assign inode number H
And that’s it!
When to compact logs? It’s not a trivial decision, since compacting involves rewriting whole blocks, which is costly in terms of I/O. It’s also best to only compact blocks if a significant part of it will be discarded. For instance, if only 3 out of 10,000 entries in a log are obsolete, it makes little sense to rewrite 9,997 entries to a new log just to reclaim a couple of bytes. If, however, 60% of the log is already obsolete, it’s tempting to start a compaction process. Note that even though compaction’s ultimate goal is to reclaim memory, it temporarily needs to allocate a new block for a rewrite. It’s best to have some blocks reserved for compactions only, since if 100% of the disk is already taken by user data, it’s already too late to compact anything.
If possible, it would be best to perform the compaction when the load on the file system is low, e.g. all the users are currently asleep, but, given that Seastar is proficient at assigning proper priorities to background tasks, compactions can also progress slowly even if the system is heavily used at the moment.
Perceptive readers probably noticed a similarity between this process and compaction performed on SSTables — no coincidence here, ScyllaDB’s write path is heavily influenced by a log-structured design already.
Locking
Concurrent operations on a file system must be performed with caution, since the metadata needs to always be in a consistent state. No locks can easily lead to inconsistencies (e.g. creating two files with an identical path), and naïve locking can cause subtle deadlocks. In order to prevent such problems, our implementation included a lock management system, which offers both exclusive and shared locking as well as lock ordering to prevent deadlocks. The core idea is that the file system needs two basic types of locks: an inode lock and a dentry lock. An inode lock is associated with a specific file, while a dentry lock guards a specific directory entry. A single file system operation may involve multiple locks. For instance, creating a file involves:
- Locking a directory (shared lock) – so that it’s not deleted in the middle of an operation,
which would create an orphaned file without a parent directory. - Locking a newly created directory entry (exclusive lock) – in order to prevent creating two files with identical paths.
Naturally, we could also get away with locking a directory in exclusive mode, but that’s a performance issue, because a directory locked in such a way quickly becomes a bottleneck — think adding 100,000 independent files to the / directory at once.
Multiple locks are a first step towards deadlock. In order to prevent that, we take advantage of the fact that all locks present in the file system can be linearly ordered — and thus we can always take the locks in increasing order, which ensures that there won’t be any loops. The order of locking in our file system is defined as follows. Let x be an inode, (x) is then a lock for that inode, and (x, d) is a lock for the directory entry corresponding to that inode:
(x) < (y) ⇔ x < y
(x) < (y, d) ⇔ x ≤ y
(x, d) < (y) ⇔ x < y
(x, d) < (y, d’) ⇔ (x<y) ∨(x=y∧d < d’)
Now, given that inodes are represented as 64-bit integers and directory entries are strings, we’re always able to compare two locks and decide which one is “smaller” than the other.
Test results
SeastarFS is not production-ready by the time of writing this blog, but a significant part of it is already coded and tested (see last paragraph for details). Testing a file system is a big project by itself, and it consists of checking:
- correctness of all file system operations under various loads
- latency of the operations under various loads with different client concurrency levels
- general throughput of the file system
- correctness of the compaction process
- performance of the compaction process — both in terms of how much data can be reclaimed and how many resources are needed for that
- how the system compares to other systems, like XFS.
Comparing to XFS was not a trivial task, since SeastarFS is in fact a userspace library with a specific API, and XFS is an inherent part of the Linux kernel with a different interface. Still, there are tools for benchmarking and checking (click here and here) the underlying file systems written specifically for Seastar, and they were quite easy to port to SeastarFS. As a result, it was possible to see how well SeastarFS performs when compared to others. Here’s a sample chart, showing how consistent SeastarFS is with regard to latency of operations:
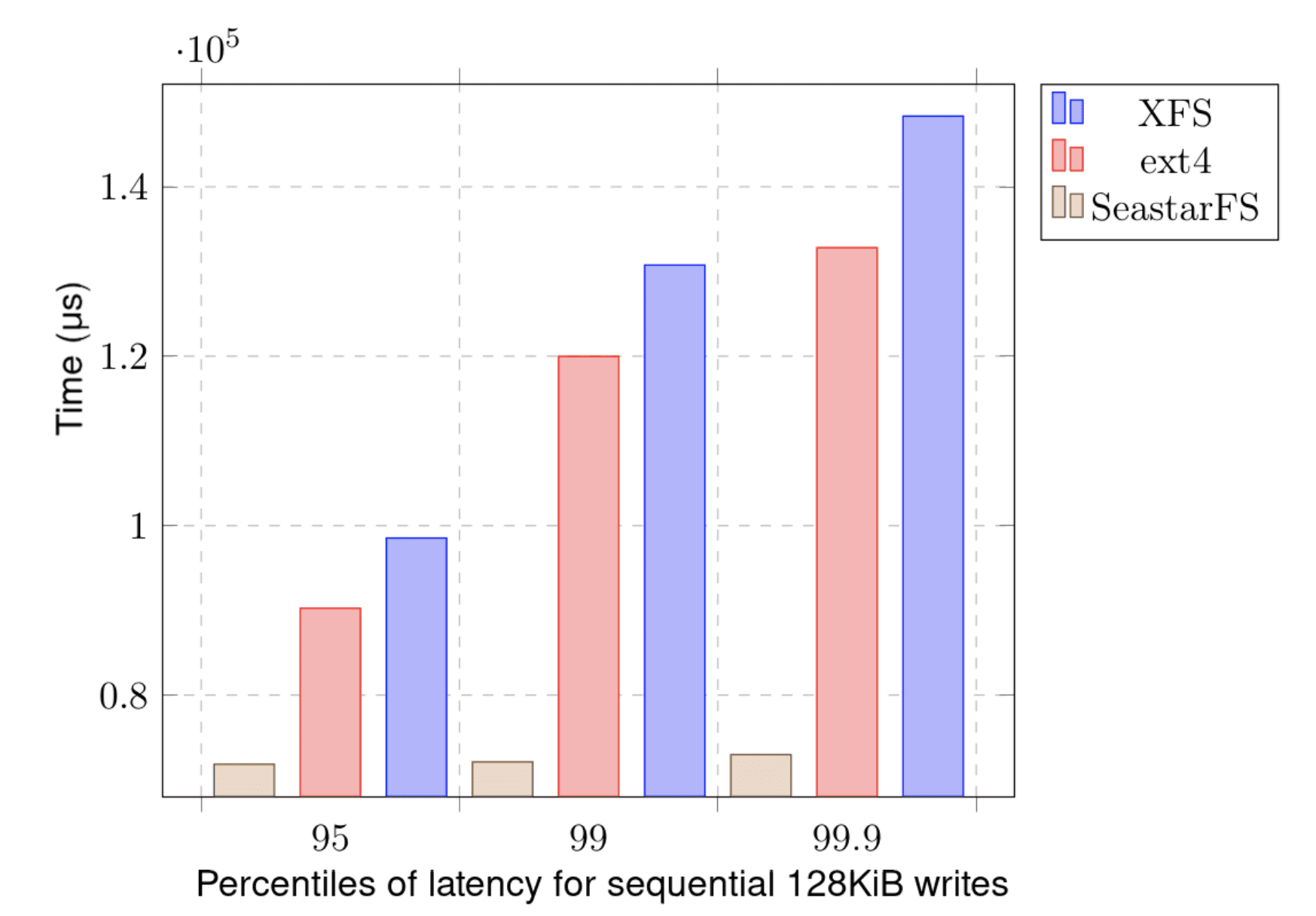
Many more results, charts and conclusions can be found in the next paragraph.
Source code and the paper
All of the code produced during this project is open-source and available on GitHub and seastar-dev mailing list:
- [RFC PATCH 01/34] fs: prepare fs/ directory and conditional compilation
- https://github.com/psarna/seastar/tree/fs-metadata-log
- https://github.com/psarna/seastar/tree/fs-compaction
Each project was also a foundation for the Bachelor’s thesis of the students who took part in it. The thesis was already reviewed and accepted by the University of Warsaw and is public to read. You can find a detailed description of the design, goals, performed tests and results in this document, in Polish. Volunteers for a translation are very welcome!: zpp_fs.pdf.
We’re very proud of contributing to the creation of this academic paper – congrats to all brand new BSc degree holders! We are definitely looking forward to continuing our cooperation with the students and the faculty of the University of Warsaw in the future. Happy reading!







