




In 2019, ScyllaDB sponsored a program for Computer Science students organized by the University of Warsaw. Throughout the whole academic year, 3 teams of undergraduate students collaborated with and learned from ScyllaDB engineers to bring new features to ScyllaDB and its underlying Seastar engine. The projects picked for 2019 edition were:
- Parquet support for Seastar and ScyllaDB
- SeastarFS: an asynchronous userspace file system for Seastar
- Kafka client for Seastar and ScyllaDB.
We’re pleased to announce that the cooperation was very successful and we look forward to taking part in future editions of the program! Now, let’s see some details on the results of the first project on the list: Parquet support for Seastar and ScyllaDB. This work is all to the credit of the students who wrote it, Samvel Abrahamyan, Michał Chojnowski, Adam Czajkowski and Jacek Karwowski, and their supervisor, Dr. Robert Dąbrowski.
Introduction
Apache Parquet is a well known columnar storage format, incorporated into Apache Arrow, Apache Spark SQL, Pandas and other projects. In its columns, it can store simple types as well as complex nested objects and data structures. Representing the data as columns brings interesting advantages over the classic row-based approach:
- fetching specific columns from a table requires less I/O, since no redundant values from other columns are read from disk
- values from a column are often the same or similar to each other, which increases the efficiency of compression algorithms
- interesting data encoding schemes, like bit-packing integers, can be easily applied
- more complex operations, like aggregating all values from a single column,
can be implemented more efficiently (e.g. by leveraging vectorized CPU instructions)
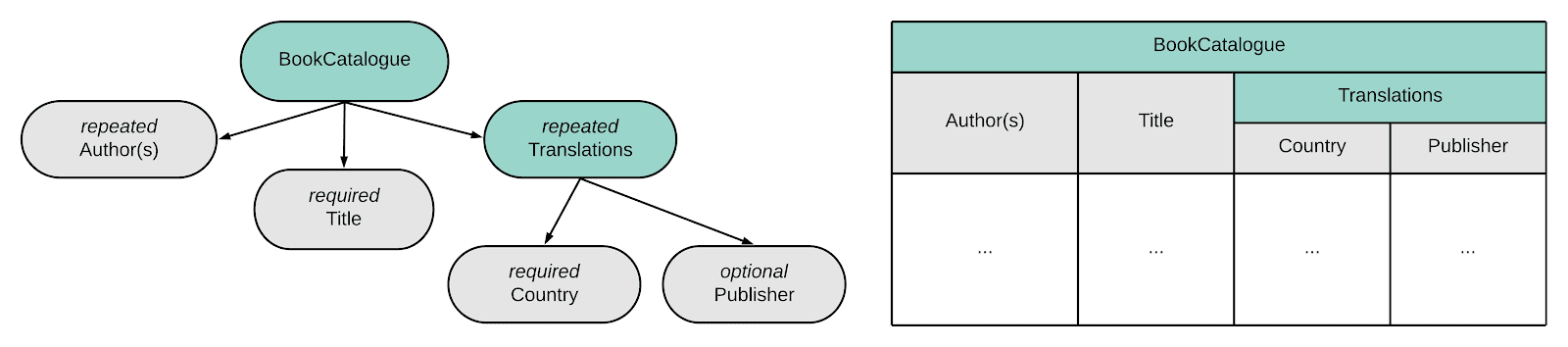
An example of the Parquet file format, showing how it can optimize based on repeated values in columnar data.
ScyllaDB uses SSTables as its native storage format, but we’re interested in allowing our users to pick another format — like Parquet — for certain workloads. That was the main motivation for pursuing this student project.
How to integrate ScyllaDB with Parquet?
Parquet is open-source, very popular and broadly used by many projects and companies, so why not use an existing C++ library and plug it right into ScyllaDB? The short answer is “latency.”
ScyllaDB is built on top of Seastar, an asynchronous high-performance C++ framework. Seastar was created in accordance with the shared-nothing principle and it has its own nonblocking I/O primitives, schedulers, priority groups and many other mechanisms designed specifically for ensuring low latency and most optimized hardware utilization. In the Seastar world, issuing a blocking system call (like read()) is an unforgivable mistake and a performance killer. That also means that many libraries which rely on traditional, blocking system calls (used without care) would create such performance regressions when used in a Seastar-based project — and Parquet’s C++ implementation was not an exception in that matter.
There are multiple ways of adapting libraries for Seastar, but in this case the simplest answer turned out to be the best — let’s write our own! Parquet is well documented and its specification is quite short, so it was a great fit for a team of brave students to try and implement it from scratch in Seastar.
Implementing parquet4seastar
Spoiler alert: the library is already implemented and it works!
https://github.com/michoecho/parquet4seastar
The first iteration of the project was an attempt to simply copy the whole code from Arrow’s repository and replace all I/O calls with ones compatible with Seastar. That also means rewriting everything to Seastar’s future/promise model, which is a boring and mechanical task, but also easy to do. Unfortunately, it quickly turned out that Parquet implementation from Apache Arrow has quite a lot of dependencies within Arrow itself. Thus, in order to avoid rewriting more and more lines, a decision was made: let’s start over, take Parquet documentation and write a simple library for reading and writing Parquet files, built from scratch on top of Seastar.
Other advantages to this approach cited by the students: by writing it over from scratch, they would avoid carrying over any technical debt and minimize the amount of lines-of-code to be added to the existing code base, and, most of all, they thought it would be more fun!
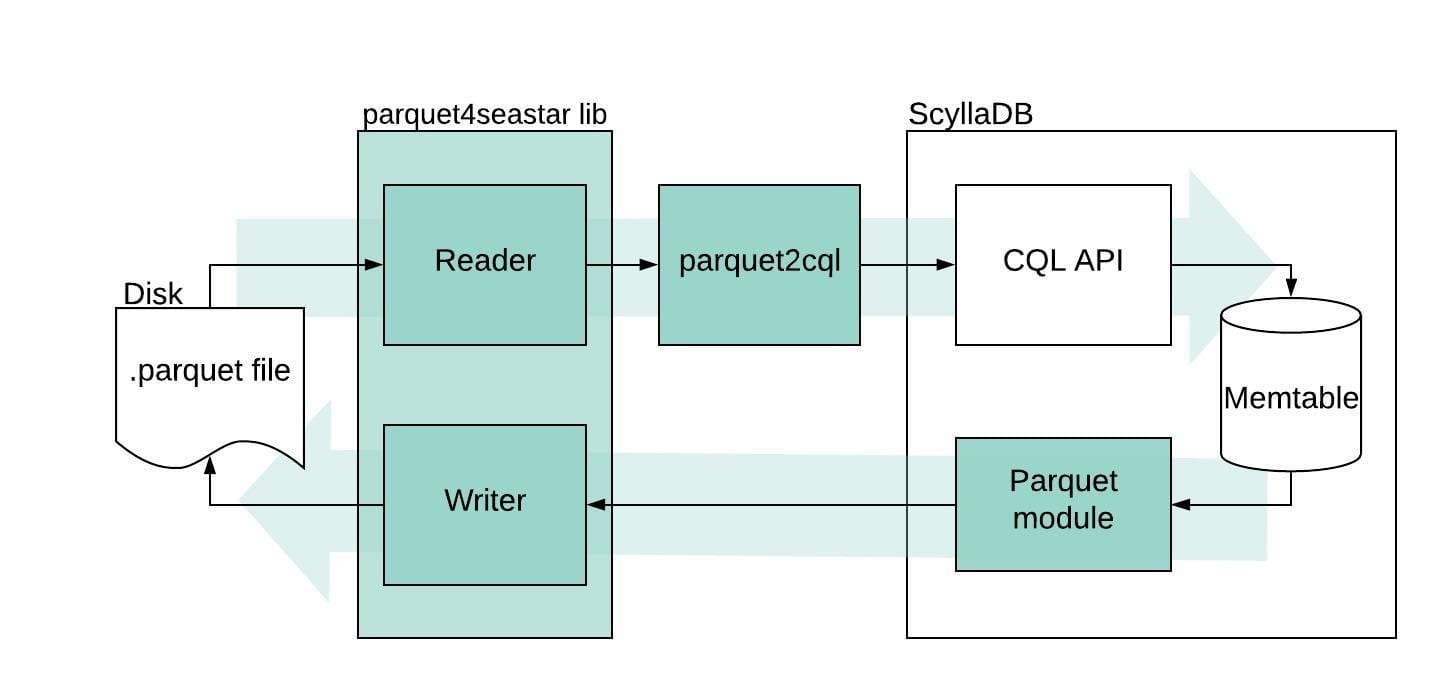
A block diagram of how parquet4seastar and parquet2cql were designed to interact with the ScyllaDB database.
The library was written using state-of-the-art Seastar practices, which means that measures have been taken to maximize the performance while keeping the latencies low. The performance tests indicated that the reactor stalls all came from external compression libraries – which, of course, can be rewritten in Seastar as well.
We were also pleased to discover that Parquet’s C++ implementation in Apache Arrow comes with a comprehensive set of unit tests – which were adjusted for parquet4seastar and used for ensuring that our reimplementation is at least as correct as the original.
Still, our main goal was to make the library easy to integrate with existing Seastar projects, like ScyllaDB. As a first step and a proof-of-concept for the library, a small application which reads Parquet files and translates them into CQL queries was created.
parquet2cql
parquet2cql is a small demo application which shows the potential of parquet4seastar library. It reads Parquet files from disks, takes a CQL schema for a specific table and spits out CQL queries, ready to be injected into ScyllaDB via cqlsh or any CQL driver. Please find a cool graph which shows how parquet2cql works below. `p4s` stands for `parquet4seastar`.
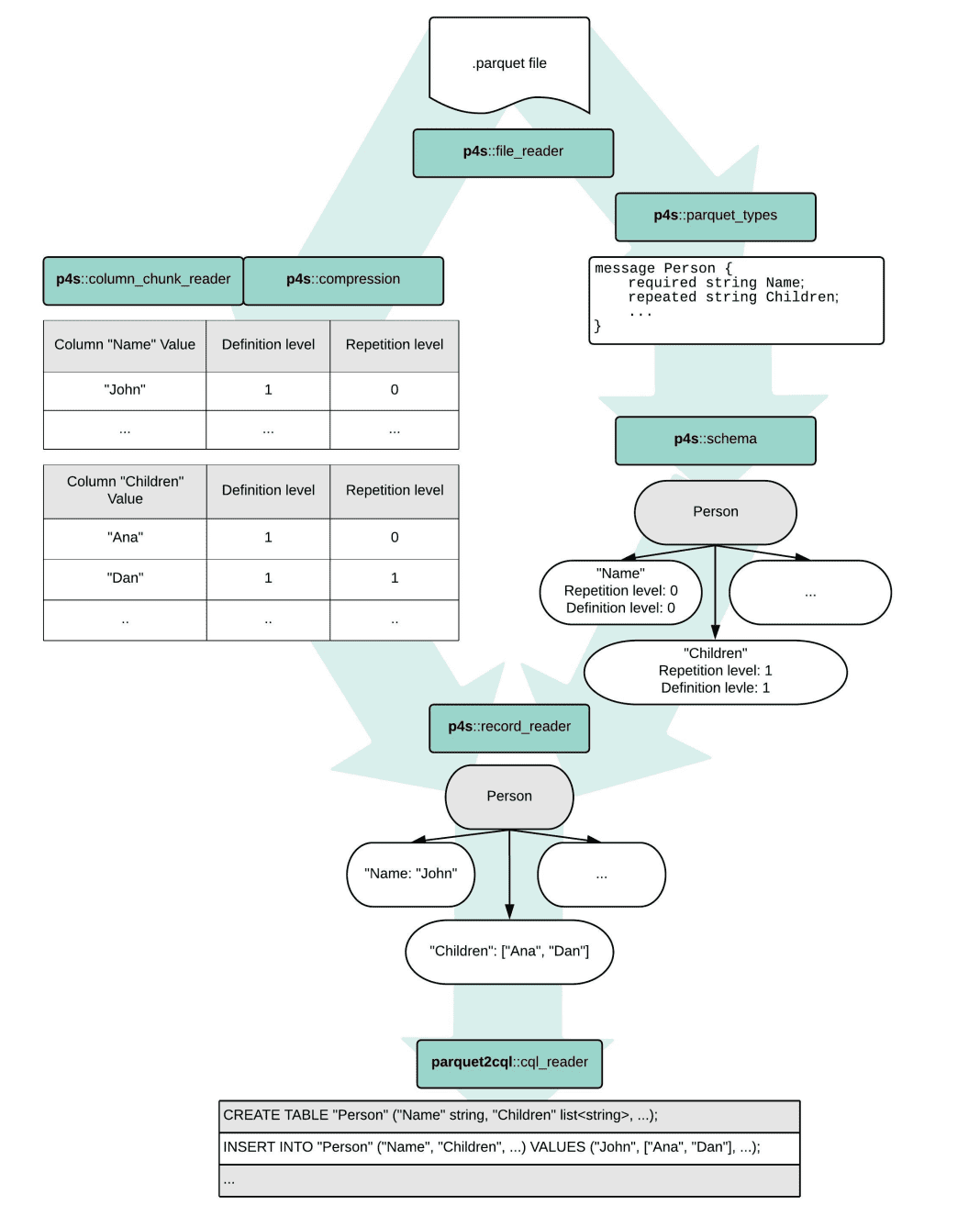
parquet2cql can be used as a crude way of loading Parquet data straight into ScyllaDB, but it’s still only a demo application – e.g. it does not support CQL prepared statements, which would make the process much more optimized. For those interested in migrating Parquet data to ScyllaDB clusters, there’s a way to ingest Parquet files using our ScyllaDB Spark Migrator.
Integration with ScyllaDB
Allowing ScyllaDB to store its data directly in Parquet instead of the classic SSTable format was way out of scope for this project, but, nonetheless, a proof-of-concept demo which stores SSTable data files not only in the native MC format, but also in Parquet was performed successfully! The implementation assumed that no complex types (lists, set) were present in the table. This experiment allowed us to compare the performance and storage overhead of using Parquet vs SSTable mc format for various workloads. Here’s a diagram showing how the experiment was performed:
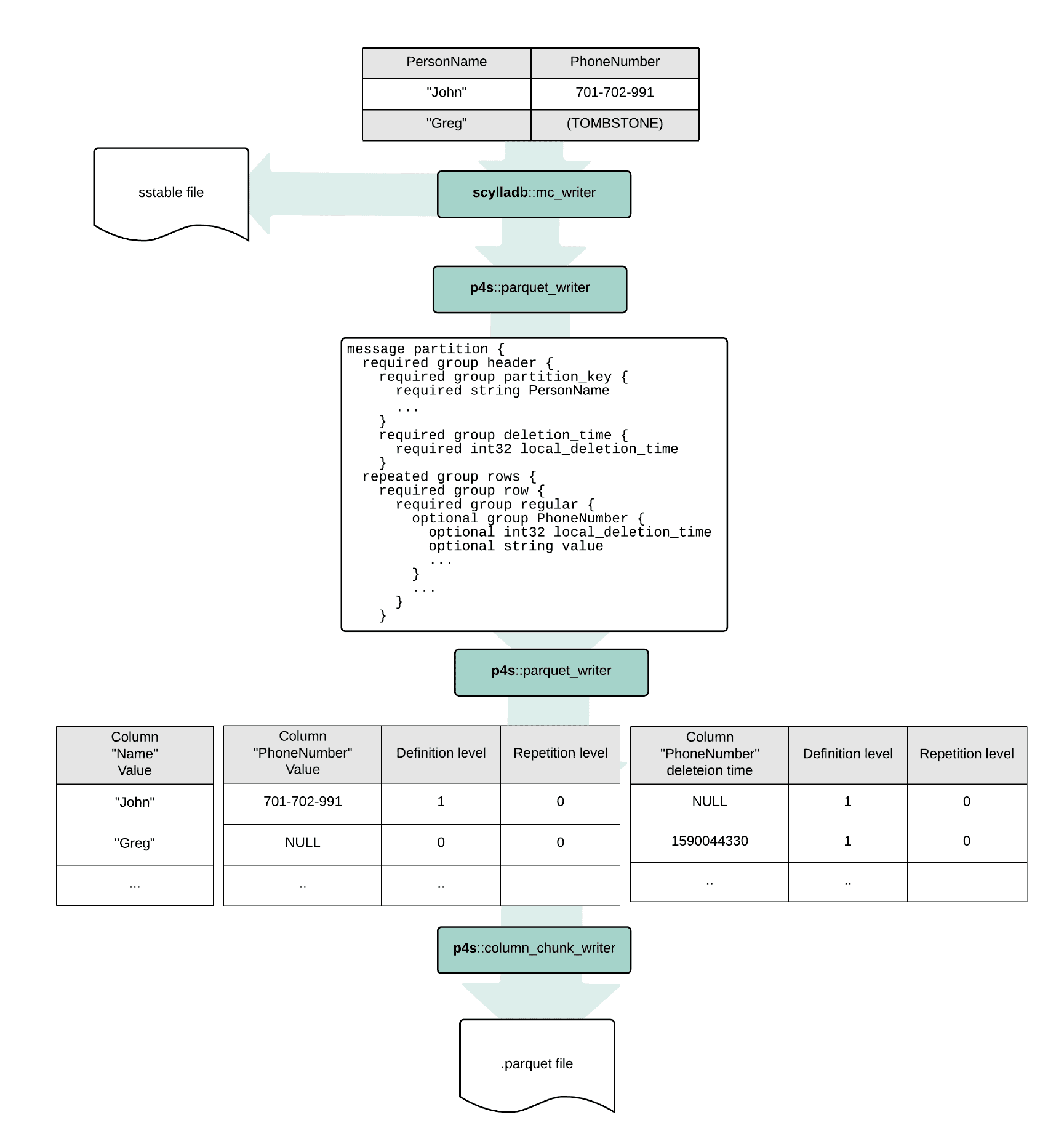
Results
The project was not only about coding – a vast part of it was running various correctness and performance tests and comparisons. One of the tests checked whether parquet4seastar library is faster than its older brother from Apache Arrow. Here are the sample results:
![]()
Reading time of parquet4seastar relative to Apache Arrow (less means that parquet4seastar was faster).
The results indicate that parquet4seastar is generally similar to Apache Arrow in terms of time of execution (with an exception of the short strings scenario, which is a result of a design decision, please find more details in the paper below). The results are promising, because they mean that providing much better latency guarantees by using nonblocking I/O and the future/promise model did not result in any execution time overhead. Aside from comparing the library against Apache Arrow, many more test scenarios were run – measuring reactor stalls, comparing the sizes of SSTables stored in native MC format vs in Parquet, etc.
Here we have a comparison of the disk usage between Parquet and SSTables. The chart above shows the results of the first test conducted where the students inserted a million rows with random strings each time, but some values were duplicated. The horizontal axis shows the number of duplicates for each value and the vertical axis shows the total size of the files. You can see that in this test Parquet is more efficient.
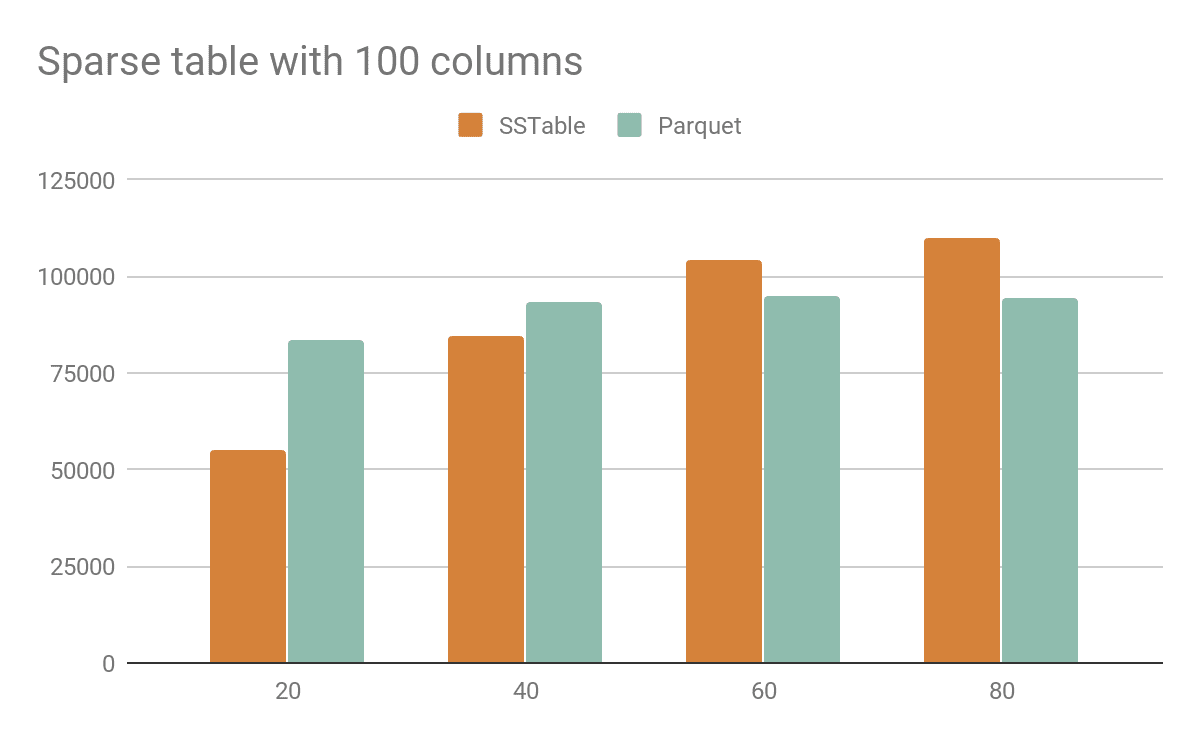
In this example the students tested a table with multiple NULL values, typical of a sparse data set. The horizontal axis shows the number of randomly selected columns that are not NULL and instead have a random value. In this case you can see that SSTables are a better format when most of the columns are NULL.
From these tests it can be concluded that with Parquet you can achieve significant disk space savings when the data is not null, but the number of unique values is not very large.
The Paper
Now, the coolest part. Each project was also a foundation for the Bachelor’s thesis of the students who took part in it. The thesis was already reviewed and accepted by the University of Warsaw and is public to read.You can find a detailed description of the design, goals, performed tests and results in this document: zpp_parquet.pdf. We’re very proud of contributing to the creation of this academic paper – congrats to all brand new BSc degree holders! We are definitely looking forward to continuing our cooperation with the students and the faculty of the University of Warsaw in the future. Happy reading!
READ THIS: APACHE PARQUET SUPPORT FOR SCYLLA
CHECK OUT PART II: IMPLEMENTING AN ASYNC USERSPACE FILESYSTEM








