Apache Kafka is a well-known distributed message queue, used by thousands of companies. Developers love its scalability, performance, fault tolerance, and an entire ecosystem of clients, connectors, and tools built around it. One relevant use case is the ingestion of data from databases to a Kafka cluster, from where it is easily available to other systems.
In this post, I will describe the details of our Kafka client for Seastar and ScyllaDB, which we created as our final year student project, sponsored by ScyllaDB. As a member of the student team, I’ll take you on a journey throughout our graduation year, and show how we developed this client. Finally, you will see how we used it to write a ScyllaDB service to stream Change Data Capture (CDC) events to Kafka.
Intro: Student Projects
In 2019, ScyllaDB sponsored a program for Computer Science students organized by the University of Warsaw. Throughout the whole academic year, 3 teams of undergraduate students collaborated with and learned from ScyllaDB engineers to bring new features to ScyllaDB and its underlying Seastar engine. The projects picked for the 2019 edition were:
- Parquet support for Seastar and ScyllaDB (see Part I)
- SeastarFS: an asynchronous userspace file system for Seastar (see Part II)
- Kafka client for Seastar and ScyllaDB (this post)
This blog post describes the Kafka client project. The students responsible for the project were Wojciech Bączkowski, Piotr Grabowski (the author of this article), Michał Szostek, and Piotr Wojtczak. Our supervisor was Michał Możdżonek, M. Sc. The project was the foundation for the Bachelor’s thesis of the students who took part in it.

Animation 1: Our graduation year journey
Project timeline. In the animation above you can see the timeline of our project. Throughout this blog post, we describe many stages of our development process, share how we planned our work, and implemented many great features. Soon you will learn in great detail about all of the topics that are presented (chronologically) on this timeline.
Apache Kafka: Core Concepts
Apache Kafka is a distributed message queue. You can send and receive messages from Kafka, which consist of a key and value.
Topics. To organize the messages in a Kafka cluster, each message is bound to a particular topic – a distinct and separate message queue. For example, you can have a topic called “notifications” storing push notifications to be sent to your mobile users and a separate “sign-in” topic to persist information about your users logging in to the website.
Brokers and partitions. As Kafka is a highly-scalable system, there has to be a way to scale a topic to many Kafka brokers (nodes). This aspect is achieved through partitions. A single Kafka topic consists of one or more partitions, which can be spread across multiple brokers. Depending on the chosen partitioning strategy, messages will be split across different partitions based on the message key, with each partition belonging to one specific broker.
Clients. There are two main types of Kafka clients – producers and consumers. Producers allow you to send messages, while consumers receive messages from the Kafka cluster. During our student project, we created a producer for ScyllaDB.
Our Goals and Feature Set
At the start of our graduation year of bachelor studies, we sat down with ScyllaDB to discuss the project and outline the common goals. Together, we talked about the necessary features of the Kafka client, the scope of the project, and how it could be used in ScyllaDB. The three core goals for the Kafka client we identified were: performance, correctness, and support for a wide range of features.
Feature set. After an academic year of working on the project, we successfully implemented a Kafka producer, offering:
- Future-based API built on top of Seastar
- High performance
- Proper error handling and resiliency
- Retries, with configurable backoff strategies (exponential backoff with jitter as default)
- Partitioners (multiple implemented out-of-the-box)
- Batching
- ACK (configurable number of acknowledgments to wait to receive after sending a message)
- Compatibility with older Kafka clusters (by supporting many versions of the protocol)
- Support for multi-broker clusters
ScyllaDB also suggested writing an example ScyllaDB feature that leveraged our Kafka client. We settled on implementing a proof-of-concept ScyllaDB service that replicates Change Data Capture (CDC) log to a Kafka topic.
Why Seastar?
There are multiple Kafka clients already available, librdkafka being the most popular library for C++. However, using an existing library would cause a similar problem as in the Parquet project: latency.
Seastar design. ScyllaDB is built on top of Seastar, an asynchronous high-performance C++ framework. Seastar was created following the shared-nothing principle and it has its own non-blocking I/O primitives, schedulers, priority groups, and many other mechanisms designed specifically for ensuring low latency and most optimized hardware utilization.
In the Seastar world, issuing a blocking system call (like read()) is an unforgivable mistake and a performance killer. It also means many libraries that rely on traditional, blocking system calls would create such performance regressions when used in a Seastar-based project — and librdkafka C++ implementation was not an exception in that matter. Therefore we decided to write our client from scratch and use the networking capabilities available in Seastar.
Alternative clients. At first, we also considered modifying some existing libraries to take advantage of Seastar, however, we quickly realized that the design of those libraries was not compatible with Seastar and ScyllaDB philosophy. For example, librdkafka internally creates one thread per broker in the Kafka cluster. This can cause expensive cross-core data transfers (especially on CPUs with multiple NUMA nodes). That’s a stark difference compared to ScyllaDB, which utilizes a single thread per CPU core and runs small sub-millisecond-sized tasks using a custom user-space scheduler.
Animation 2: Difference between librdkafka and our client.
Notice how librdkafka does expensive cross-core data transfers.
Seastar goodies. Moreover, Seastar offered us many useful features, for example, DPDK support – a network backend running in userspace, allowing for lower overhead networking. By designing our API to be based around futures, we could offer the users of our library an intuitive interface, immediately familiar to other ScyllaDB and Seastar developers. By adopting the shared-nothing principle (not sharing the data between cores) there was no need to use locks or other synchronization primitives, which dramatically simplified the development process.
The Kafka protocol
To write a good Kafka client, we knew that we had to learn both the high-level concepts of how the client should work, as well as lower-level intricacies of its communication: the protocol.
Kafka uses a TCP binary protocol. It is based on the request/response paradigm (client sending the request, Kafka broker responding with one response).
Message types. The protocol defines many message types, such as ApiVersions with information about supported message versions by the broker (more on that later); Metadata with the current list of brokers, topics, and partitions in the cluster; Produce which allows for sending a message to some particular topic.
Versioning. As Kafka is actively developed and there are new features added continuously, the protocol must provide a way to be extended with new functionality. Moreover, it has to be done in a way that maintains compatibility with older clients.
The protocol deals with that challenge by using protocol versions. Each message type is individually versioned. The client, after connecting with the broker, sends an ApiVersions request. The broker sends back an ApiVersions response, which contains the information about supported versions for each message type. The client can now use this information about versions, to send requests in versions that both client and broker can support.
Let’s look at a concrete example: the Produce message has 9 versions defined. When transaction support was added to Kafka, there was a need to pass transaction ID alongside Produce request. This additional field was added in version 3 of this message type.
Handling Errors
One of the key features of Kafka is its fault-tolerance and resiliency. While exploring the design of existing Kafka clients, we quickly discovered that achieving this goal is the responsibility of both Kafka brokers and clients.
Error codes. In distributed systems such as Kafka, which can operate on hundreds of nodes, there are a lot of failure scenarios that must be handled correctly. From the client perspective, the protocol informs about those errors by sending the right error code.
It was our job, as Kafka client developers, to implement the correct behavior upon receiving an error code. Those errors can be split into three separate groups.
Non-recoverable errors. The first group of error codes we identified was non-recoverable errors: for example after receiving SASL_AUTHENTICATION_FAILED (authentication error), the correct behavior is to stop the client and throw an exception informing about authentication problems.
Retriable errors. Another group of errors is retriable errors. Most common in this group is NETWORK_EXCEPTION, which can occur in case of a broken connection or a timeout. Using our exponential backoff strategy, we retry those requests, as those network problems might be temporary.
Metadata refresh. The last group of error codes is those that require metadata refresh. The client maintains the local copy of the information about the cluster metadata – what are the addresses of nodes, topics, and their partitions. When producing a new message, Kafka requires sending it to a leader of a partition. To determine the node to dispatch the request to, we use this local metadata.
However, this metadata can get stale and we will send the request to the incorrect node. In such a case, we will get a NOT_LEADER_FOR_PARTITION error code and our client recognizes that metadata needs to be refreshed by sending the Metadata request to the Kafka cluster. Upon receiving updated metadata, we can try sending the message again.
Batching
Batching is a simple technique that improves bandwidth and decreases overhead. By sending many messages in one request (one batch) we don’t have to send the metadata about messages multiple times and the overhead of protocol (Kafka protocol, TCP/IP) is smaller relative to the single message. Kafka protocol supports this feature by allowing to send multiple messages in a single Produce request.
Our implementation. We implemented this feature by adding a separate queue for the messages waiting to be sent. At some point in time, this queue will be flushed, which results in the Produce requests to be sent to the Kafka cluster. There are a few ways to control the message flushing. Firstly you can manually call the flush() method on the producer. Another way to control this behavior is by setting the _buffer_memory option, which controls the maximum cumulative length of messages in the waiting queue. Finally, the client automatically periodically flushes the queue (period controlled by _linger option).
Optimization
One of the initial goals of our project was to write a client that was feature-rich, correct, and performant. By making sure that we designed our code with performance in mind from day one, utilizing the Seastar framework that is the foundation of ScyllaDB’s high performance, we were confident that we were on the right track.
The approach. At first, our client was much slower than a first-party Java Kafka client. To fix the performance of our solution, we have performed multiple profiling cycles, every time identifying issues and fixing them. Some fixes we applied initially were trivial, but to squeeze every last drop of performance we later focused on algorithmic and low-level improvements. As you will see in the benchmark section we more than succeeded in our optimization endeavor.
Profilers. For profiling, we used the perf tool and a great open-source Flamegraph tool. In each profiling cycle, we identified the biggest performance problem based on flame graphs and fixed it.
Data copying. When developing the client, we tried to avoid any unnecessary copying of data. However, we missed a few spots here and there. They were immediately visible on the flame graph and fixing them proved to be very easy – sometimes as easy as changing passing some variable to be by constant reference instead of by value.
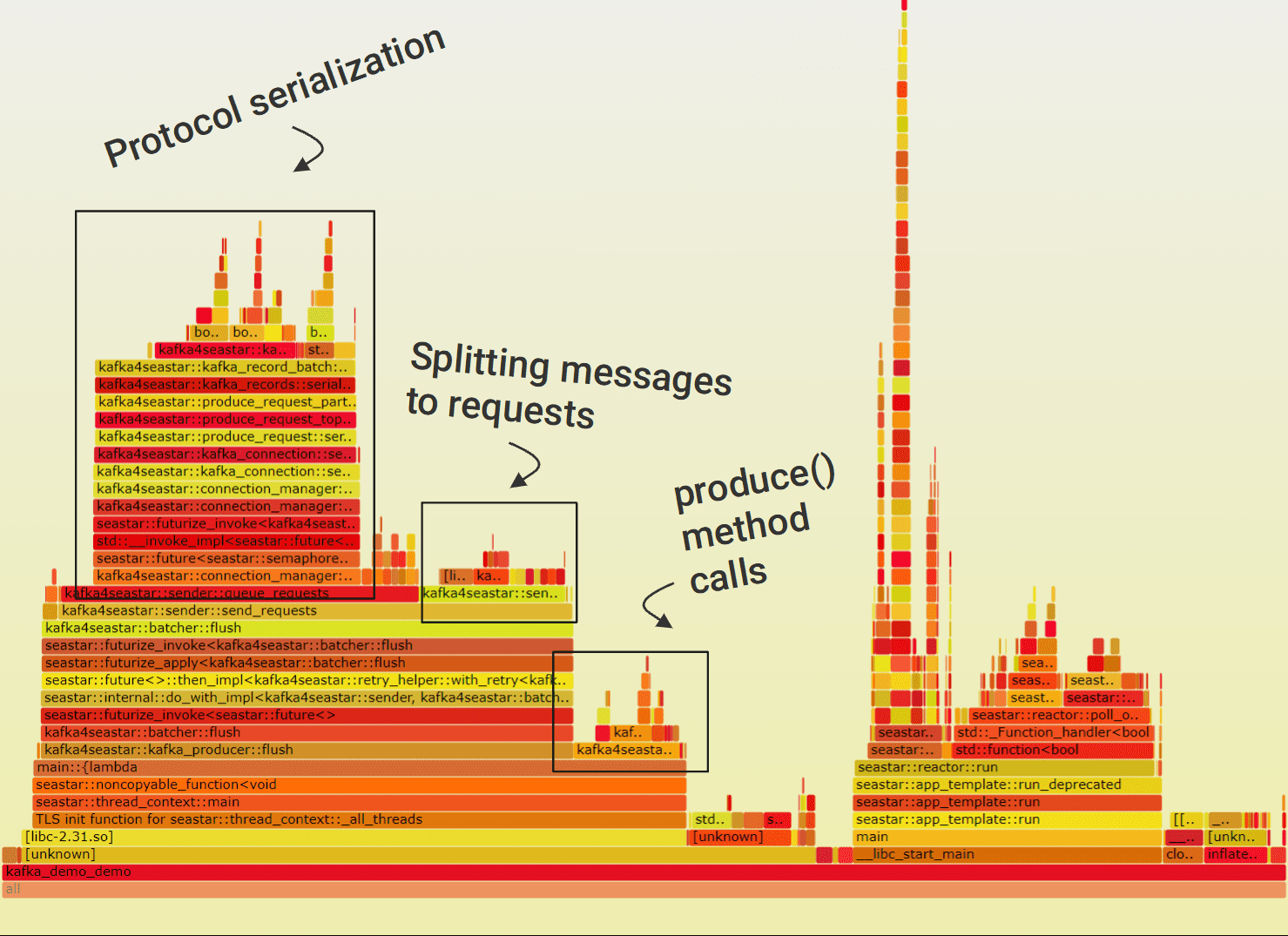
Screenshot 1: Annotated flame graph of our client at some initial optimization stage
In one such case, forgetting about using references resulted in cluster metadata being copied on every message sent. It might not seem like a big issue, but when sending millions of messages per second, this single problem was a big part of the overhead.
Memory allocations. Another memory-related performance issue was memory allocation. While serializing the protocol messages there were a few temporary buffers, some of them allocated for every message sent. By declaring them as (static) thread_local, we saved millions of allocations that were executed in the course of our benchmarks.
Algorithmic improvements. Some of the fixes required looking at the problems from an algorithmic perspective. One of the operations we execute for each message is looking up metadata to determine the address of the broker to dispatch the Produce request to. Initially, this lookup was done linearly (finding the topic in topic metadata, then a partition in partitions metadata). Afterward, we added a pre-processing step to sort the topics and partitions, which allowed us to perform a binary search in the lookup function. Our final approach was to use unordered_map, which proved to be most efficient in our benchmarks.
Profiler – be careful! When using a profiling tool such as flame graphs, you need to be aware of its limitations or quirks. One issue that was not instantly obvious to us, based on just looking at the flame graph (as they show on-CPU activity), was network socket configuration. Because we do manual batching of messages and we wait for the batch to flush, every millisecond in that process counts. Using the NO_DELAY option on the socket, which disables Nagle’s algorithm, made a big difference in our benchmarks as it reduced the latency between issuing the write on the socket and receiving the response from the Kafka cluster.
SIMD. Another issue that we found was inefficient CRC32 calculation. This checksum is a mandatory value to be sent alongside messages. Initially, to get the client running, we used the Boost library implementation, which uses a lookup table that is applied to each byte. As this code was probably inlined, it was not presented on the flame graph as a separate function, hiding its impact on the performance.
We switched to the more efficient implementation, which takes advantage of SSE4.2 crc32 instruction. By using this instruction, we were able to process 8 bytes in 3 cycles (latency, excluding memory access) compared to byte-by-byte lookups of Boost implementation. In ScyllaDB, this approach is even more advanced, as it takes advantage of being able to start executing crc32 instruction every cycle (throughput of 1).
Benchmarks
As the performance of our client was one of our top priorities, we needed to design a benchmark comparing our solution with other Kafka clients. During our optimization process having a reliable benchmark proved to be indispensable.
In the course of the development, we tested the client on our local machines. However, when we started measuring the performance, we realized that we had to run it on much beefier machines and in a multi-broker environment to get more realistic results, closer to real-life deployments.
Benchmark environment. We decided to run our benchmarks on AWS. We used m5n.2xlarge instances, configured in a “cluster” placement group (to reduce the latency). Those instances have 8 logical processors (Xeon Cascade Lake, 3.1GHz sustained boost) and 32GB of RAM. We equipped them with gp2 SSDs and ran them in 1-broker and 3-broker Kafka cluster configuration. The Zookeeper server and instance with tested clients were started on separate nodes of the same type.
Benchmarked clients. We compared our client with two leading libraries: the first-party Java client, maintained by Apache Kafka project, and librdkafka – a popular C++ client.
Test methodology. To test them all uniformly, we implemented a simple benchmark routine. In a given benchmark case, we send some number of messages of a certain size and manually flush the batch when it is full and wait for it to finish processing. We are aware that this methodology might not play to the strengths of some clients, but we tried hard to tune the options of every tested library to achieve the best performance in each one of them.
Let’s get to the results!
1-node cluster, sending 80 million messages (each 10 bytes), batched in groups of 1,000
| Client | Time(s) | Messages per second | Throughput (MB/s) |
| Our client | 53.40 s | 1,498,127 msg/s | 14.20 MB/s |
| Java | 70.83 s | 1,129,464 msg/s | 10.77 MB/s |
| librdkafka (C++) | 79.72 s | 1,003,512 msg/s | 9.57 MB/s |
1-node cluster, sending 80 million messages (each 100 bytes), batched in groups of 1,000
| Client | Time(s) | Messages per second | Throughput (MB/s) |
| Our Client | 81.68 s | 979,431 msg/s | 93.40 MB/s |
| Java | 95.46 s | 838,047 msg/s | 79.92 MB/s |
| librdkafka (C++) | 92.84 s | 861,697 msg/s | 82.17 MB/s |
1-node cluster, sending 8 million messages (each 1,000 bytes), batched in groups of size 100
| Client | Time(s) | Messages per second | Throughput (MB/s) |
| Our client | 38.51 s | 207,738 msg/s | 198.11 MB/s |
| Java | 43.52 s | 183,823 msg/s | 175.30 MB/s |
| librdkafka (C++) | 41.24 s | 193,986 msg/s | 184.99 MB/s |
1-node cluster, sending 80 million messages (each 50 bytes), batched in groups of size 10,000
| Client | Time(s) | Messages per second | Throughput (MB/s) |
| Our client | 60.52 s | 1,321,877 msg/s | 63.03 MB/s |
| Java | 77.01 s | 1,038,826 msg/s | 49.53 MB/s |
| librdkafka (C++) | 61.07 s | 1,309,972 msg/s | 62.46 MB/s |
3-node cluster, sending 78 million messages (each 10 bytes), batched in groups of size 3,000
| Client | Time(s) | Messages per second | Throughput (MB/s) |
| Our client | 38.96 s | 2,002,053 msg/s | 19.09 MB/s |
| Java | 57.68 s | 1,352,288 msg/s | 12.89 MB/s |
| librdkafka (C++) | 81.09 s | 961,894 msg/s | 9.17 MB/s |
3-node cluster, sending 100 million messages (each 100 bytes), batched in groups of size 5,000
| Client | Time(s) | Messages per second | Throughput (MB/s) |
| Our client | 69.59 s | 1,436,988 msg/s | 137.04 MB/s |
| Java | 90.49 s | 1,105,094 msg/s | 105.39 MB/s |
| librdkafka (C++) | 98.67 s | 1,013,479 msg/s | 96.65 MB/s |
3-node cluster, sending 10 million messages (each 1,000 bytes), batched in groups of size 2,000
| Client | Time(s) | Messages per second | Throughput (MB/s) |
| Our client | 29.43 s | 339,789 msg/s | 324.04 MB/s |
| Java | 30.86 s | 324,044 msg/s | 309.03 MB/s |
| librdkafka (C++) | 31.17 s | 320,821 msg/s | 305.95 MB/s |
Results analysis. As you can see from our benchmarks, our client is faster than both the Java client and librdkafka in all cases. When sending 78 million 10-byte messages to a 3-node cluster, our client smashed the two million messages per second barrier, being significantly faster than the competition. On a test with larger messages (1000 bytes large), we were able to get 300+ MB/s throughput, all on a single core!
However, looking at the raw data, it might be a little intimidating to fully grasp it. To make it easier, let’s group it by some aspect and chart the groups. Let’s start by organizing the results by the number of brokers in the cluster:
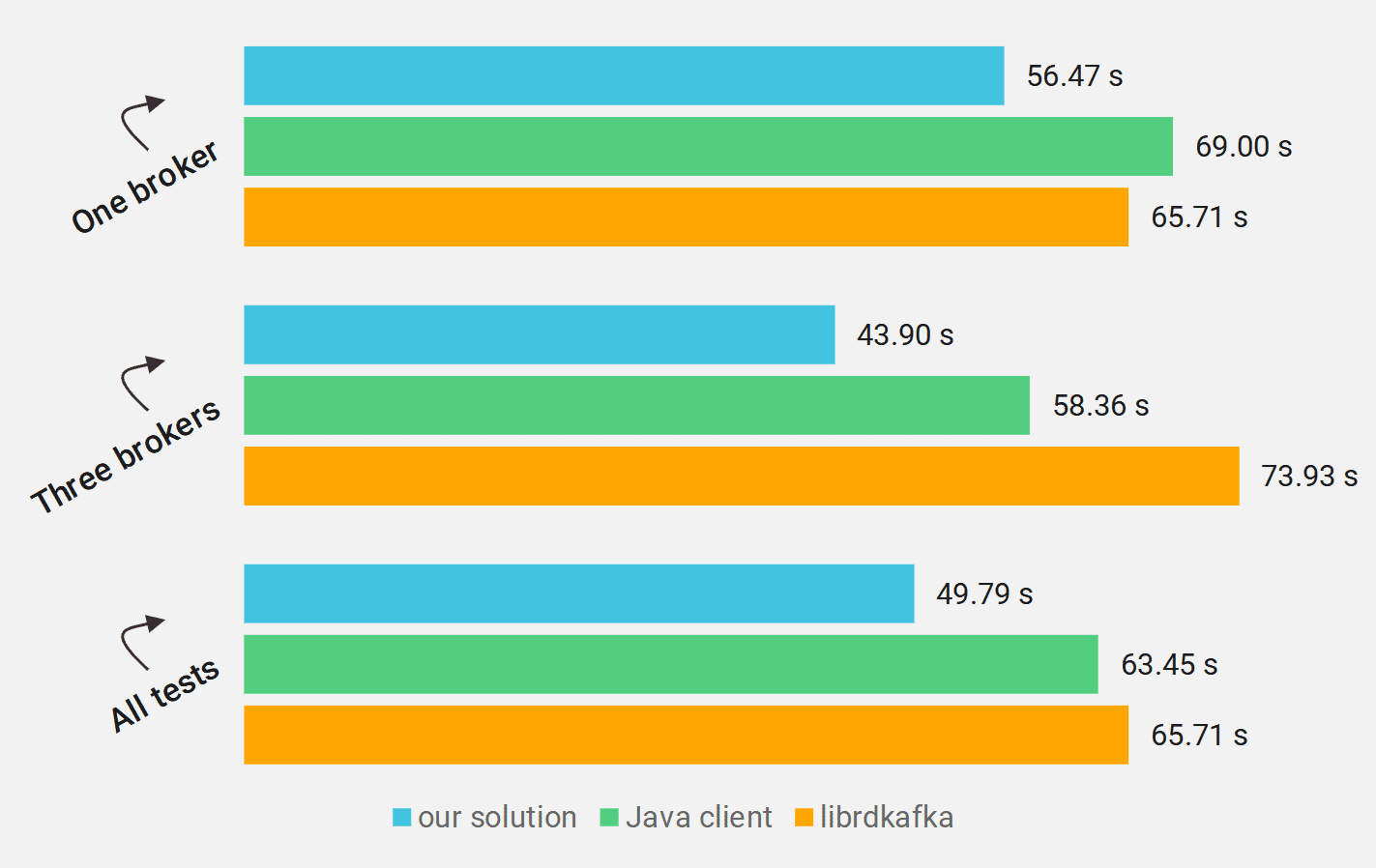
Chart 1: Execution time geometric mean (in seconds; smaller is better), tests grouped by cluster configuration
In our tests, librdkafka was faster than the Java client in a single-broker scenario, while it lagged in the three-broker configuration. Our solution was faster than the others in both one-broker and three-broker configurations.
Our benchmarks measured workloads with very small messages, as well as larger messages (10 bytes, 100 bytes, 1,000 bytes). The results, when grouped by this aspect:
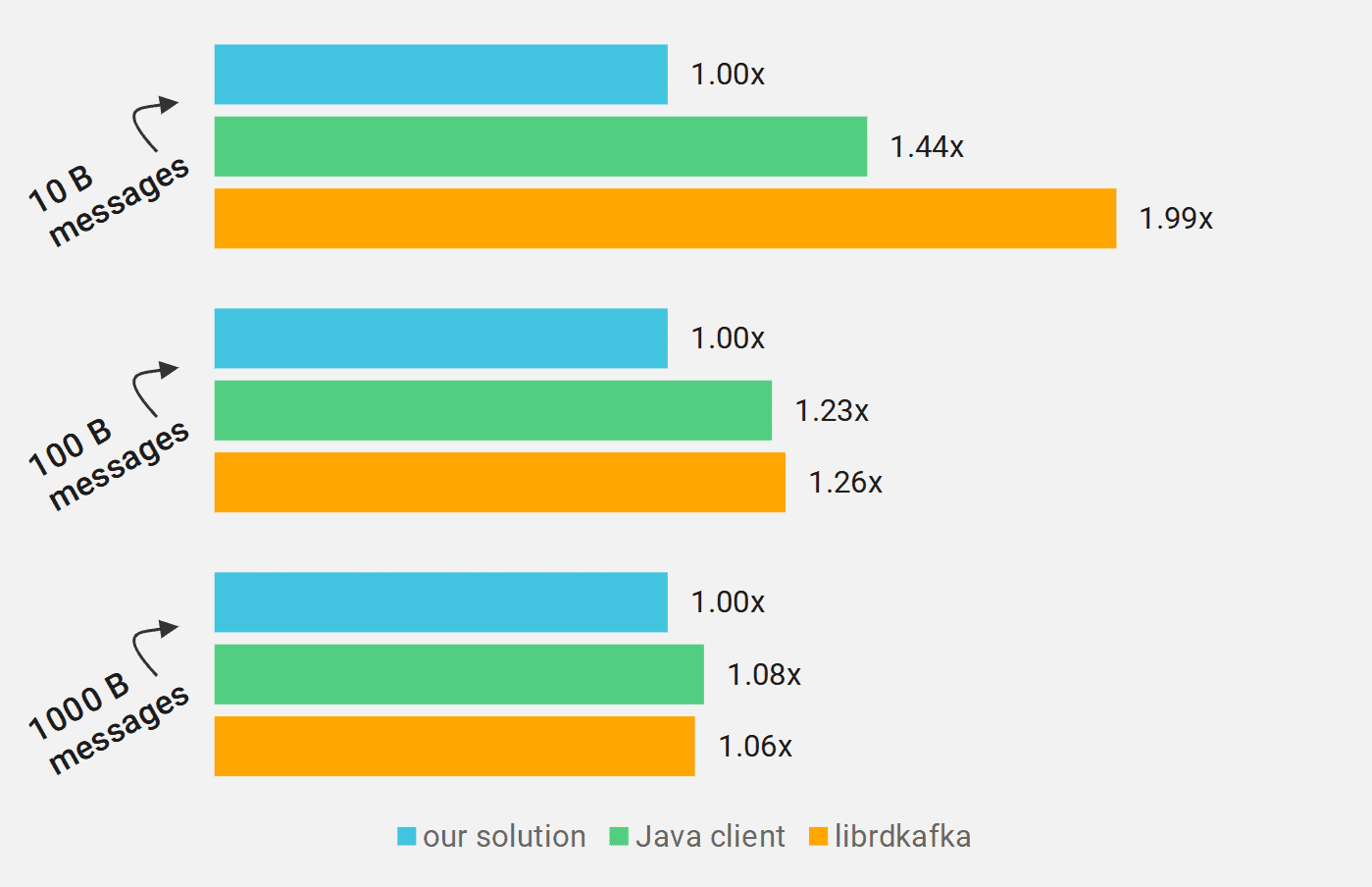
Chart 2: Normalized geometric mean of execution time (smaller is better), tests grouped by message size in bytes
As you can see our client is faster, especially when sending small messages. However, this performance difference quickly shrinks when switching to larger messages (100 B or 1000 B). Even though in the 1000 B case this difference is much smaller, we are still able to achieve 6-8% speedup.
Example Use Case: ScyllaDB CDC Replication Service
We designed our Kafka client to work well with ScyllaDB, so our next step was obvious – implement a new ScyllaDB functionality that used our client. We decided to marry our Kafka client with ScyllaDB’s Change Data Capture (CDC) feature.
Change Data Capture (CDC) is a feature that allows users to track data changes in their ScyllaDB database. When CDC is enabled on a table (base table), a new CDC log table is created. It allows you to query the history of all changes made to the table, not only the current state of the table that is stored in the base table. You can learn more about this feature in our “Using Change Data Capture (CDC) in ScyllaDB” blogpost.
New ScyllaDB service. To showcase how our client could be used with the CDC feature, we created a new ScyllaDB service that streams data changes to Apache Kafka. We use the CDC log table to query the latest changes that happened in the table, which can be queried efficiently thanks to the CDC design. Later, the service serializes those changes to Apache Avro format and sends it to Kafka using our client.
Having the CDC events streamed to Kafka opens up a breadth of possibilities to use this data to easily build more complex systems. One possibility that seemed like a perfect match was using ScyllaDB Sink Connector. It is a Kafka Connect connector, which replicates messages from Kafka topic to some ScyllaDB table. It supports the Avro format that we implemented in our service, which allows us to maintain proper schema information.
New opportunities. By using those systems in conjunction, we have effectively set up an asynchronous ScyllaDB-to-ScyllaDB table replication. This shows how our service and Kafka, which are relatively general-purpose, could enable new and interesting ways to use the data from your ScyllaDB cluster. Moreover, it allowed us to easily test our service by checking if the tables on the source and destination ScyllaDB clusters contain the same data after the replication has finished.
Future plans. Even though our ScyllaDB service was created as a proof-of-concept it showed great potential. ScyllaDB is now hard at work to bring this functionality as a Kafka connector. Stay tuned!
Wrapping it up
All of the source code for the Kafka client and for modified ScyllaDB with our service at https://github.com/haaawk/scylla/tree/cdc_kafka_integration.
The thesis. The project was the foundation for the Bachelor’s thesis of the students who took part in it. The thesis was already reviewed and accepted by the University of Warsaw and is public to read. You can find a detailed description of the design, goals, performed tests, and results in this document, in Polish: bachelor_thesis.
The end of the beginning. So that wraps up our “ScyllaDB Student Projects” series for 2020. ScyllaDB is very proud to have helped the students in their graduation year of Bachelor studies. We’re very pleased to announce that four students, who have collaborated with us, have joined ScyllaDB.
Personally speaking, as a former member of the Kafka student team, working with ScyllaDB was a great experience for me. As avid C++ fans, we were initially drawn by the fact that ScyllaDB stays on the bleeding edge of the C++ standard – using the features from the latest standard that were just implemented in compilers. We also saw this as an opportunity to explore the areas of computer science that very few companies work on. From the first day, we saw how people working at ScyllaDB were passionate and willing to help us with any problems we encountered.
Stay tuned! As the new academic year has just recently started, ScyllaDB is eager to work with new students this year. Stay tuned for a post coming in one year to read how the next projects turned out!
A note to educators: ScyllaDB is committed to helping challenge and guide the next generation of computer scientists. Besides our projects at the University of Warsaw, we recently held a virtual talk at Carnegie Mellon University. If you would like to see something similar conducted at your own institution please contact us directly.