ScyllaDB is a highly performant, scalable, distributable and reliable database. Yet even the most reliable of databases can suffer from catastrophic unplanned outages (such as in the underlying infrastructure). That’s why it is vital to keep backups. Those backups can be non-trivial because ScyllaDB is a distributed system comprising any number of terabytes of data. ScyllaDB Manager was created to automate those mundane, but necessary tasks of maintaining your ScyllaDB clusters.
ScyllaDB Manager automates the backup process and allows you to configure how and when backup occurs. The advantages of using ScyllaDB Manager for backup operations are:
- Data selection – backup a single table or an entire cluster, the choice is up to you
- Data deduplication – prevents multiple uploads of the same SSTable
- Data retention – purge old data automatically when all goes right, or failover when something goes wrong
- Data throttling – control how fast you upload or Pause/resume the backup
- Lower disruption to workflow of the ScyllaDB Manager Agent due to cgroups and/or CPU pinning
- No cross-region traffic – configurable upload destination per datacenter
To implement backups we introduced the ScyllaDB Manager Agent, a helper process that runs on cluster nodes alongside ScyllaDB. ScyllaDB Manager Agent was first made available in ScyllaDB Manager 2.0.
After its initial availability, we worked with both customers and our own ScyllaDB Cloud engineering team to enhance this feature to meet the needs of the most demanding user environments under production workloads, which we now share with you in ScyllaDB Manager 2.1.
Benchmarks showed great improvements between ScyllaDB Manager 2.0 and 2.1. Backup time was reduced by half in some instances. Listing of backups and files were reduced from minutes to seconds. Memory consumption stabilized and dropped to minimal required levels. We are planning a separate blog post which will discuss all the obstacles and technical details of how we overcome them. For now let’s see how backups with ScyllaDB Manager work.
Setting up a cluster
Let’s first setup the cluster and ScyllaDB Manager before going into backup tasks. This section can be skipped if you are familiar with the ScyllaDB Manager setup.
In our example we will use a cluster provided on AWS. We will go with i3.large instance for this example because we intend to create a cluster with 150GB of data. Cluster consists of three nodes with replication factor of three.
ScyllaDB Manager requires a single separate machine because it’s a centralized system for managing ScyllaDB clusters. This machine needs access to the ports 9042 and 10001 of the ScyllaDB nodes. Please follow official documentation for more details about installing ScyllaDB Manager and ScyllaDB Manager Agent. Once the system is up we can proceed with adding a cluster to it.:
> sctool cluster add --host 35.157.92.173 --name cluster1 --without-repair
7313fda0-6ebd-4513-8af0-67ac8e30077b
__
/ \ Cluster added! You can set it as default, by exporting its name or ID as env variable:
@ @ $ export SCYLLA_MANAGER_CLUSTER=7313fda0-6ebd-4513-8af0-67ac8e30077b
| | $ export SCYLLA_MANAGER_CLUSTER=clust
|| |/
|| || Now run:
|\_/| $ sctool status -c clust
\___/ $ sctool task list -c clustOnly the IP of one node is provided; ScyllaDB Manager discovers all other nodes. We are adding it with the --without-repair parameter because we don’t need a repair task that is created by default on creation. Cluster is registered and it has a UUID (5627109e-9a19-43d5-aa04-fbc555d0546b) and a name (cluster1):
> sctool cluster list
╭──────────────────────────────────────┬──────────╮
│ ID │ Name. │
├──────────────────────────────────────┼──────────┤
│ 5627109e-9a19-43d5-aa04-fbc555d0546b │ cluster1 │
╰──────────────────────────────────────┴──────────╯By checking the status of the cluster (“sctool status”) we can see it’s healthy:
> sctool status
Cluster: cluster1 (7313fda0-6ebd-4513-8af0-67ac8e30077b)
Datacenter: AWS_EU_CENTRAL_1
╭────┬──────────┬──────────┬───────────────┬──────────────────────────────────────╮
│ │ CQL │ REST │ Host │ Host ID │
├────┼──────────┼──────────┼───────────────┼──────────────────────────────────────┤
│ UN │ UP (2ms) │ UP (1ms) │ 18.157.57.255 │ a2e9eb2d-354b-47aa-8d4e-b61cdb56e548 │
│ UN │ UP (3ms) │ UP (1ms) │ 3.124.120.59 │ ab33203f-dd2e-4137-b279-7262edcbfdd1 │
│ UN │ UP (0ms) │ UP (1ms) │ 35.157.92.173 │ 92de78b1-6c77-4788-b513-2fff5a178fe5 │
╰────┴──────────┴──────────┴───────────────┴──────────────────────────────────────╯There are three nodes in this cluster. In version 2.1 we added an additional column at the beginning of the table. This column shows the status of the node using the same syntax and data as nodetool (in this case, “UN” means “Up” and “Normal” state).
Let’s add some sample data to the cluster. We will first create a keyspace and tables using CQL:
CREATE KEYSPACE user_data WITH replication = { 'class': 'SimpleStrategy', 'replication_factor': '3' };We will use script to create one hundred tables and populate them with ~148GB of data:
CREATE TABLE IF NOT EXISTS data_0 (id uuid PRIMARY KEY, data blob)
CREATE TABLE IF NOT EXISTS data_1 (id uuid PRIMARY KEY, data blob)
CREATE TABLE IF NOT EXISTS data_2 (id uuid PRIMARY KEY, data blob)
...We will now use ScyllaDB Manager to backup this data.
Creating backup tasks
One of the central concepts of the ScyllaDB Manager are tasks. A task is an operation, like repair or backup, that can be scheduled to run at any given time or in regular intervals.
Let’s add a new backup task. This task will take a snapshot of your cluster and back it up to an S3 bucket. It will run every day and will preserve the last seven backups.
> sctool backup -c cluster1 -L s3:backup-bucket --retention 7 --interval "24h" --rate-limit 50
backup/001ce624-9ac2-4076-a502-ec99d01effe4This will create a new backup task with id “backup/001ce624-9ac2-4076-a502-ec99d01effe4”. If you just want to experiment with parameters before actually creating the backup you can use the --dry-run parameter which will do an analysis of the cluster without any actions and print information about the backup.
We specify the S3 bucket to which backups will be saved (s3:backup-bucket), and some additional properties (--retention 7 --interval "24h" --rate-limit 50) to retain the last seven backups, that will be run intervals of 24 hours with bandwidth limit of the backup process set to 50 MB/s. This backup task doesn’t filter any keyspaces or tables so it will backup all it can find in the cluster including system keyspaces. Filtering by data center is also possible. For the complete reference of all the parameters available to this command please refer to the documentation for sctool backup command.
We can start the task by its ID and then verify that it has a RUNNING status:
In the background ScyllaDB Manager is running the backup procedure in parallel on all nodes. Parallelism levels are configurable with --snapshot-parallel and --upload-parallel commands. Manager sequentially takes the snapshots of the data, does stats calculation and indexing of files, uploads data to the target location along with the metadata, and then it purges outdated data if your retention policy threshold is reached.
ScyllaDB Monitoring is the recommended way for monitoring ScyllaDB clusters. It provides a wide range of dashboards to examine all aspects of your cluster. It contains dashboards for some ScyllaDB Manager metrics too. ScyllaDB Manager provides an additional way of monitoring running tasks, via the sctool task progress command:
> sctool task progress -c cluster1 backup/001ce624-9ac2-4076-a502-ec99d01effe4
Arguments: -L s3:backup-bucket --retention 7 --rate-limit 50
Status: RUNNING (taking snapshot)
Start time: 12 May 20 13:14:58 UTC
Duration: 5s
Progress: -
Snapshot Tag: sm_20200512131458UTC
Datacenters:
- AWS_EU_CENTRAL_1We can observe that the task is in the stage of taking a snapshot and it’s tagged with “sm_20200512131458UTC”. Snapshot tags contain a UTC based timestamp in YYYYMMDDHHMMSS format. This piece of information could become useful in case ScyllaDB Manager metadata is lost. We can continue monitoring progress with calls to sctool task progress:
> sctool task progress -c cluster1 backup/001ce624-9ac2-4076-a502-ec99d01effe4
Arguments: -L s3:backup-bucket --retention 7 --rate-limit 50
Status: RUNNING (uploading data)
Start time: 12 May 20 13:14:58 UTC
Duration: 2m30s
Progress: 1%
Snapshot Tag: sm_20200512131458UTC
Datacenters:
- AWS_EU_CENTRAL_1
╭───────────────┬──────────┬───────────┬─────────┬──────────────┬────────╮
│ Host │ Progress │ Size │ Success │ Deduplicated │ Failed │
├───────────────┼──────────┼───────────┼─────────┼──────────────┼────────┤
│ 18.157.57.255 │ 1% │ 148.24GiB │ 2.82GiB │ 0B │ 0B │
│ 3.124.120.59 │ 2% │ 148.22GiB │ 3.04GiB │ 0B │ 0B │
│ 35.157.92.173 │ 1% │ 148.22GiB │ 2.93GiB │ 0B │ 0B │
╰───────────────┴──────────┴───────────┴─────────┴──────────────┴────────╯Stopping and resuming a backup
Running backup can take a while. If a task needs to be stopped it can be done with the sctool task stop command:
Stopped backup tasks can be resumed. Let’s start it again. Notice it will check the files again but it will resume upload only for the files that are not yet uploaded:
> sctool task start -c cluster1 backup/001ce624-9ac2-4076-a502-ec99d01effe4
We are waiting for the DONE status:
> sctool task progress -c cluster1 backup/001ce624-9ac2-4076-a502-ec99d01effe4
Arguments: -L s3:backup-bucket --retention 7 --rate-limit 50
Status: DONE
Start time: 12 May 20 13:24:58 UTC
End time: 12 May 20 14:21:52 UTC
Duration: 56m54s
Progress: 100%
Snapshot Tag: sm_20200512131458UTC
Datacenters:
- AWS_EU_CENTRAL_1
╭───────────────┬──────────┬───────────┬───────────┬──────────────┬────────╮
│ Host │ Progress │ Size │ Success │ Deduplicated │ Failed │
├───────────────┼──────────┼───────────┼───────────┼──────────────┼────────┤
│ 18.157.57.255 │ 100% │ 148.24GiB │ 148.24GiB │ 2.23GiB │ 0B │
│ 3.124.120.59 │ 100% │ 148.22GiB │ 148.22GiB │ 3MiB │ 0B │
│ 35.157.92.173 │ 100% │ 148.22GiB │ 148.22GiB │ 2.97GiB │ 0B │
╰───────────────┴──────────┴───────────┴───────────┴──────────────┴────────╯Efficient transfer and storage of backups
Task of backing up ~148.24GiB of backup data per node was done in ~57m. Let’s see what is stored in the bucket by issuing “sctool backup list” command:
> sctool backup list -L s3:backup-bucket -c clust
Snapshots:
- sm_20200512131458UTC (444.68GiB)
Keyspaces:
- system_auth (4 tables)
- system_distributed (2 tables)
- system_schema (12 tables)
- system_traces (5 tables)
- user_data (100 tables)By now you might have noticed a column called “Deduplicated”. Deduplication is the feature of ScyllaDB Manager which prevents multiple uploads of the same SSTable files for the entire cluster. This reduces both storage size and bandwidth usage of backups. In the example above we avoided transfer of some files that were already transferred before we stopped the task.
Let’s run the backup task again without adding any new data:
> sctool task start -c cluster1 backup/001ce624-9ac2-4076-a502-ec99d01effe4
> sctool task progress -c cluster1 backup/001ce624-9ac2-4076-a502-ec99d01effe4
Arguments: -L s3:backup-bucket --retention 7 --rate-limit 50
Status: DONE
Start time: 12 May 20 20:09:08 UTC
End time: 12 May 20 20:32:14 UTC
Duration: 23m6s
Progress: 100%
Snapshot Tag: sm_20200512200908UTC
Datacenters:
- AWS_EU_CENTRAL_1
╭───────────────┬──────────┬───────────┬───────────┬──────────────┬────────╮
│ Host │ Progress │ Size │ Success │ Deduplicated │ Failed │
├───────────────┼──────────┼───────────┼───────────┼──────────────┼────────┤
│ 18.157.57.255 │ 100% │ 148.17GiB │ 148.17GiB │ 94.49GiB │ 0B │
│ 3.124.120.59 │ 100% │ 148.17GiB │ 148.17GiB │ 96.77GiB │ 0B │
│ 35.157.92.173 │ 100% │ 148.17GiB │ 148.17GiB │ 98.72GiB │ 0B │
╰───────────────┴──────────┴───────────┴───────────┴──────────────┴────────╯It completed in ~23m. But now the Deduplicated column is showing ~96GiB. That means Manager detected that needed files were already backed up and it skipped any costly operations. But the strange thing is that we didn’t add any new data but upload was still performed partially. This is because of the ScyllaDB compaction process. The compaction process changes the SSTable file structure which means there are new files which have to be uploaded. So the amount of deduplication will vary based on the specifics of how you use your ScyllaDB database and savings will be improved the less your SSTable files change.
Let’s start the task again without adding any data to see how it behaves after compaction is completed:
> sctool task start -c cluster1 backup/001ce624-9ac2-4076-a502-ec99d01effe4
> sctool task progress -c cluster1 backup/001ce624-9ac2-4076-a502-ec99d01effe4
Arguments: -L s3:backup-bucket --retention 7 --rate-limit 50
Status: DONE
Start time: 13 May 20 04:42:22 UTC
End time: 13 May 20 04:42:36 UTC
Duration: 14s
Progress: 100%
Snapshot Tag: sm_20200513044222UTC
Datacenters:
- AWS_EU_CENTRAL_1
╭───────────────┬──────────┬───────────┬───────────┬──────────────┬────────╮
│ Host │ Progress │ Size │ Success │ Deduplicated │ Failed │
├───────────────┼──────────┼───────────┼───────────┼──────────────┼────────┤
│ 18.157.57.255 │ 100% │ 148.17GiB │ 148.17GiB │ 148.17GiB │ 0B │
│ 3.124.120.59 │ 100% │ 148.17GiB │ 148.17GiB │ 148.17GiB │ 0B │
│ 35.157.92.173 │ 100% │ 148.17GiB │ 148.17GiB │ 148.17GiB │ 0B │
╰───────────────┴──────────┴───────────┴───────────┴──────────────┴────────╯Just 14s! And all of the data is deduplicated (skipped).
Let’s use `sctool backup list` command to see what is stored in the S3 bucket after three backup runs:
> sctool backup list -L s3:backup-bucket -c clust
Snapshots:
- sm_20200513044222UTC (444.52GiB)
- sm_20200512200908UTC (444.52GiB)
- sm_20200512131458UTC (444.68GiB)
Keyspaces:
- system_auth (4 tables)
- system_distributed (2 tables)
- system_schema (12 tables)
- system_traces (5 tables)
- user_data (100 tables)The bucket contains three snapshots tagged `sm_20200513044222UTC`, `sm_20200512200908UTC` and `sm_20200512131458UTC` and each of those is referencing ~444GiB of data. Snapshot tags encode the date and time they were taken in UTC time zone. For example, `sm_20200512131458UTC` was taken on 12/05/2020 at 13:14 and 58 seconds UTC.
Let’s simulate daily backups for a week by running a backup task four more times and adding ~10G of data in between runs. We should end up with this kind of backup list:
> sctool backup list -L s3:backup-bucket -c clust
Snapshots:
- sm_20200513063046UTC (563.16GiB)
- sm_20200513060818UTC (534.00GiB)
- sm_20200513053823UTC (503.85GiB)
- sm_20200513051139UTC (474.19GiB)
- sm_20200513044222UTC (444.52GiB)
- sm_20200512200908UTC (444.52GiB)
- sm_20200512131458UTC (444.68GiB)
Keyspaces:
- system_auth (4 tables)
- system_distributed (2 tables)
- system_schema (12 tables)
- system_traces (5 tables)
- user_data (100 tables)There are seven snapshots, but how much space are these seven snapshots taking in the cloud?
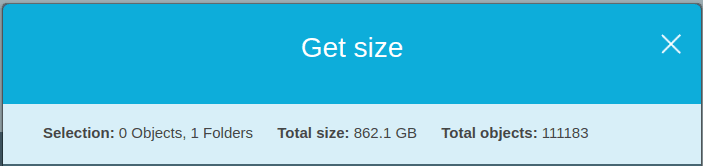
S3 reports just ~862GB for seven snapshots of ~500GiB each. ScyllaDB Manager makes sure only needed data between backups is stored.
If you need to know what keyspaces are contained in the snapshot those can be seen below snapshot tags in the backup list output. Use --show-tables to list table names too.
Let’s create another backup that will be run weekly with retention of four and only backup “user_data” keyspace:
> sctool backup -c cluster1 -L s3:backup-bucket --retention 4 --interval "7d" --rate-limit 50 --keyspace "user_data"
backup/44527f05-c49e-404d-82fa-7fcaae246252
> sctool task progress -c cluster1 backup/44527f05-c49e-404d-82fa-7fcaae246252
Arguments: -L s3:backup-bucket --retention 4 --rate-limit 50
Status: DONE
Start time: 13 May 20 07:09:07 UTC
End time: 13 May 20 07:09:36 UTC
Duration: 28s
Progress: 100%
Snapshot Tag: sm_20200513070907UTC
Datacenters:
- AWS_EU_CENTRAL_1
╭───────────────┬──────────┬───────────┬───────────┬──────────────┬────────╮
│ Host │ Progress │ Size │ Success │ Deduplicated │ Failed │
├───────────────┼──────────┼───────────┼───────────┼──────────────┼────────┤
│ 18.157.57.255 │ 100% │ 187.69GiB │ 187.69GiB │ 187.69GiB │ 0B │
│ 3.124.120.59 │ 100% │ 187.69GiB │ 187.69GiB │ 187.69GiB │ 0B │
│ 35.157.92.173 │ 100% │ 187.69GiB │ 187.69GiB │ 187.69GiB │ 0B │
╰───────────────┴──────────┴───────────┴───────────┴──────────────┴────────╯Even though this is a separate backup task deduplication kicked in because “user_data” keyspace was already backed up the first task we took. Let’s list available backups now:
> sctool backup list -c cluster1 -L s3:backup-bucket
Snapshots:
- sm_20200513070907UTC (563.07GiB)
Keyspaces:
- user_data (100 tables)
Snapshots:
- sm_20200513063046UTC (563.16GiB)
- sm_20200513060818UTC (534.00GiB)
- sm_20200513053823UTC (503.85GiB)
- sm_20200513051139UTC (474.19GiB)
- sm_20200513044222UTC (444.52GiB)
- sm_20200512200908UTC (444.52GiB)
- sm_20200512131458UTC (444.68GiB)
Keyspaces:
- system_auth (4 tables)
- system_distributed (2 tables)
- system_schema (12 tables)
- system_traces (5 tables)
- user_data (100 tables)We can observe that there are now eight snapshots available with different sets of keyspaces/tables. Because of our contrived example all three are referencing similar data and ScyllaDB Manager ensured that storage space usage is optimal.
This feature gives you freedom to schedule backups according to your policies without suffering unnecessary costs. For example you can have one backup task that will run daily, and then another one that will run each week with retention of four to cover an entire month of weekly backups. That’s eleven snapshots in total. But with ScyllaDB Manager you don’t have to store (or transfer) eleven times the same data. Depending on your exact circumstances storage and bandwidth costs can be greatly reduced.
sctool backup list can be used to list backups regardless of the cluster they were created with. First you would need to register your new cluster with ScyllaDB Manager and then list all backups from the location using --all-clusters parameter like so:
> sctool backup list -c my-new-cluster --all-clusters -L s3:backup-bucket --snapshot-tag sm_20200512131458UTCThis is especially useful if you happen to lose all ScyllaDB Manager data and you need access to previous backups.
Restoring from the backups
So, ScyllaDB Manager schedules backups, prepares, transfers and stores the backup files efficiently, but how can we restore it in the time of need?
Unfortunately the restore procedure is not fully automatic yet. For now ScyllaDB Manager only provides tooling for inspecting completed backups and users would have to fill in the gaps manually.
In order to restore the backups to their destination we would need a list of tuples (filepath, destination). We can get that with the command “sctool backup files”:
This command lists all of the files belonging to the snapshot tag along with their matching keyspace/table. Output is generated in TSV (tab separated values) format. As such it’s ready for piping to AWS CLI. The first column is the absolute path to the file in the bucket and the second column is the name of the table that file belongs to (<keyspace/table>).
A list of SSTable files can be downloaded to the nodes with the command “aws s3 cp”. For example:
> cd /var/lib/scylla/data/
> cat /tmp/backup_files.tsv | xargs -n2 aws s3 cpThese commands download all the SSTable files of the snapshot to the keyspace/table directory structure expected by ScyllaDB. You can even include table versions in the backup files output by using the --with-versions parameter with “sctool backup files” command. But downloading files to their destination is just part of the procedure. Covering all aspects of restoring a backup is beyond the scope for this article. For more details please refer to the official documentation on how to restore ScyllaDB Manager backup. You will find that restore requires more manual work and more attention. This is sometimes prone to errors which is never a good thing and we are well aware of it. Automating restores is one of our goals and will be added in a future release.
Of course, backups are not the only thing ScyllaDB Manager can help you with. There are repairs, health checks, and some other cool features. We are constantly improving it and we are preparing a technical article on how we made ScyllaDB Manager more efficient, leaner but at the same time more powerful.
Next Steps
If you would like more information on ScyllaDB or ScyllaDB Manager, feel free to ask in our Slack channel, via our mailing list, or contact us via our website.
If you are already a ScyllaDB Enterprise customer or ScyllaDB Open Source NoSQL Database user yet haven’t tried ScyllaDB Manager, the next step is up to you. Download it now!
Though if you are a ScyllaDB Cloud (NoSQL DBaaS) customer, there’s no need for action on your part. Just know that we incorporate ScyllaDB Manager backups as part of our managed Database-as-a-Service. Enjoy your evening!