We announced last week that ScyllaDB has closed another round of funding. And while funding on its own hasn’t been a goal of ours, it is a mechanism to implement many of our key goals. For example, our recent round will allow us to sharply grow our development team and double down on the database ecosystem.
Looking back at the year and a half since our last round of funding, it’s gratifying to recognize the progress we’ve made in the past 18 months. We grew the number of paying customers by 5X! We’ve advanced 80 places on db-engines. We’ve launched an impressive set of new features and capabilities to tackle whole new use cases, as we’ve documented in more than 100 blog posts!
Progress in functionality
As I wrote earlier, we’ve added many awesome new features in the last year and a half, most notably Workload Prioritization. I’m really excited about this feature, and not just because no other NoSQL database is even close to offering this capability. Workload Prioritization is the culmination of years of effort we’ve put into our CPU schedulers, I/O schedulers, tagging of every function(!) in our code with a priority-class tag and much more.
In short, Workload Prioritization enables users to consolidate clusters, to isolate workloads, and to protect their production workloads from development workload/explorations. If you use ScyllaDB, it’s an excellent advanced feature that brings demonstrable benefits while being trivial to configure.
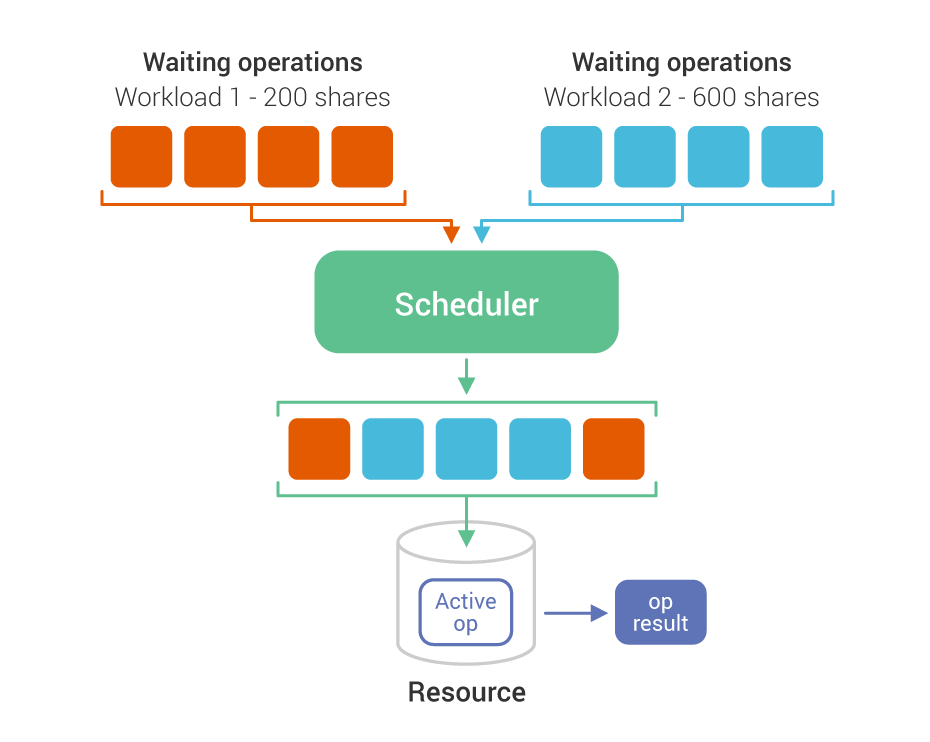
I’ll give an example. As you can see in the graphs below, a single 3-node cluster is running 3 different workloads with throughput of 150k, 110k, 50k ops (together 310k ops) while the latencies of the most important workload are the smallest among the three of them. Workload Prioritization comes into play when ScyllaDB runs at 100% CPU. It’s worth mentioning that below the max CPU utilization point, none of the workloads is capped and all of them have the option to use all of the available resources.
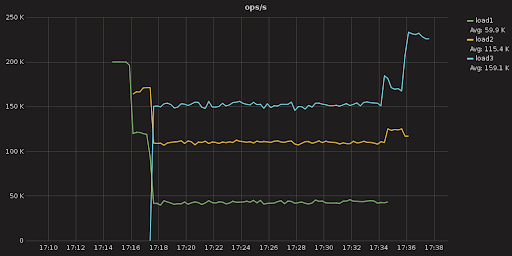
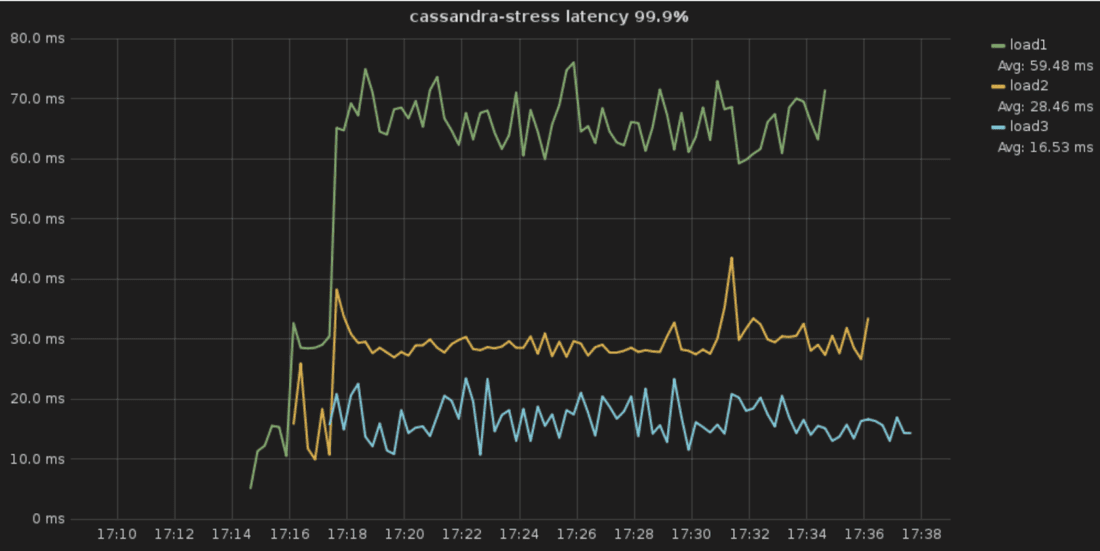
If it looks like I am getting carried away with Workload Prioritization, my apologies. It represents lots of progress for ScyllaDB. Other log-structured merge-tree databases still struggle with compaction while at ScyllaDB it is a solved problem. Repair in ScyllaDB is also a solved problem; we implemented managed repair in ScyllaDB Manager and also improved the merkle tree algorithm with the introduction of row-level repair.
ScyllaDB officially supports materialized views and our secondary indexes are scalable and global and/or local. With the upcoming release of ScyllaDB Manager backup will be fully managed and another checkbox will be marked.
The team has made plenty of progress with auxiliary tools, from migration driven by Spark to much better Grafana monitoring and client enhancement. ScyllaDB modified Cassandra drivers can hint ScyllaDB server to bypass the cache and thus keep the in-memory resident workload in the cache while range scans or rare accesses wouldn’t reach the cache. In addition, the ScyllaDB driver is shard aware, and thus eliminates cpu core hot spots.
Project Alternator, our Amazon DynamoDB-compatible API
Last week we released Project Alternator, an open source project that delivers lots of advantages over the original DynamoDB. Since the launch, we released a new version of our monitor dashboards with support for the DynamoDB API and a Spark-based migration tool. There will be much more to come in the days ahead and more announcements at the ScyllaDB Summit.
ScyllaDB Cloud
In April we released ScyllaDB Cloud, a fully managed service for ScyllaDB on AWS. Today we have many customers who use it in production and we continue to see high demand for it. ScyllaDB Cloud is multi-region and multi-zone with all of the capabilities of ScyllaDB yet with zero maintenance overhead for the user. Our staff are responsible for the uptime, latencies, backups, repairs — everything.
Next month ScyllaDB Cloud will gain the ability to run within a customer’s own AWS account and thus meet the privacy and security requirements of customers who cannot store data outside their premises. We also listen closely to our customers, so you can look forward to us adding Azure and GCP support in the first half of 2020. Thanks for your patience!
Near-term ScyllaDB enhancements
There are several key features to come, some of which have been long anticipated. At the ScyllaDB Summit we will uncover the first beta release of our Lightweight Transactions (LWT). LWT is initially implemented using Paxos and later replaced by a Raft implementation. We will also release a beta of Change Data Capture (CDC) at our Summit. We took a different approach here than Cassandra did — instead of a commitlog-based implementation we create a table of changes. Not only this is an elegant solution that allows users to consume the updates through CQL, the updates themselves are eventually consistent. You can find out more about this feature at the Summit!
Lastly, we have big plans around our User Defined Function (UDF) implementation and have been looking to base a map-reduce capability on top of it. Fundamental new features like CDC, UDF and LWT will allow us to take ScyllaDB to the next level and be much more than just a data store.
Trends
As ScyllaDB improves, we see more use-cases and growing demand from users who come from databases other than Cassandra. Quoting Alexys Jacob from Numberly: “ScyllaDB entered our infrastructure on latency and scale-sensitive use cases. That’s what it does very well in the first place and it has proven to be successful. But as more and more people get their hands on ScyllaDB and understand its capabilities they naturally challenge their usual database of choice and we now have web backends using ScyllaDB as well.”
There are cases where ScyllaDB is almost inevitable, such as replacing a large Cassandra deployment. However, we see growing demand from MySQL users. They do not come to ScyllaDB because we simplify their lives — restructuring a SQL database into a NoSQL data model isn’t trivial — but they make the move either due to requirements for fault tolerance, always-on availability or horizontal scaling to keep up with their pace of growth.
More companies and industries are becoming data driven. For instance, we have several brick-and-mortar companies that have acquired data-driven companies that were customers of ours. There is a hunger for a system to handle their massive data volumes, one that maintains both low latency and high availability, all while packaged in an affordable price. Our goal is to be the best stateful infrastructure that provides for these needs.
Over this past year we’ve added several market-leading features to ScyllaDB and now a growing amount of Fortune 500 companies are getting on board. The next two to three years will be extremely interesting. I invite you to give ScyllaDB a try for the first time or, if you’re already familiar, I’d like to challenge you to expand your ScyllaDB usage and consider it as an alternative to other databases.
To hear more from me on our company and our products or — more importantly — hear directly from our engineers and our customers, please join us at ScyllaDB Summit 2019, November 5 & 6 in San Francisco. I look forward to meeting with you then! And don’t delay! Early bird discounts are about to end on September 30.