





Today’s blog post was written by Mourjo Sen, Software Developer at Helpshift.
Introduction
In this post, we look at Helpshift’s journey of moving to a sharded model of data. We will look at the challenges we faced on the way and how ScyllaDB emerged as our choice of database for the scale that Helpshift 2.0 is aiming to serve.
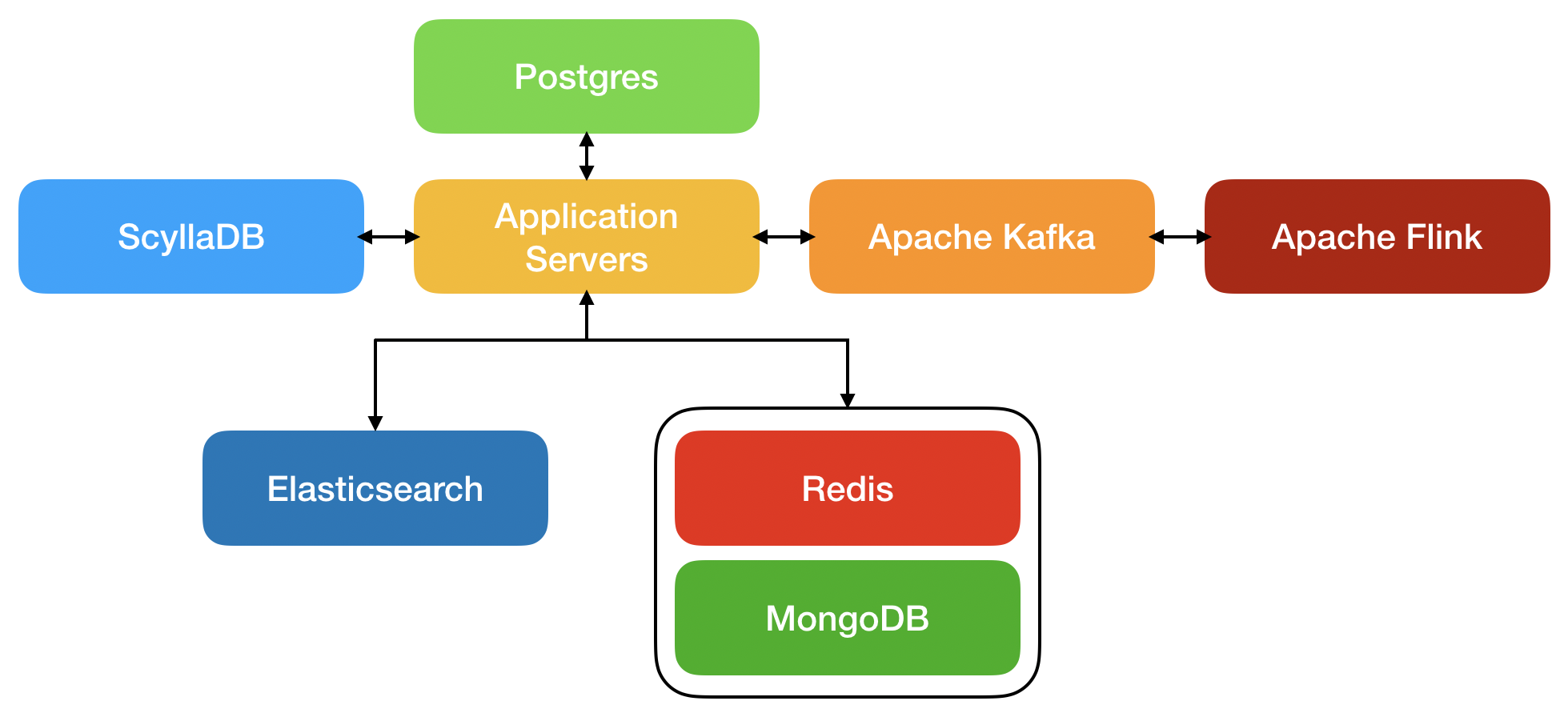
Before we get into the use case for which using ScyllaDB was the answer, here is a simplified overview of the primary elements of our architecture:
- MongoDB is used to store conversations between brands and its customers
- Redis is used as a cache layer in front of mongoDB for faster retrieval of frequently accessed data
- ScyllaDB is used to store user-related data
- PostgreSQL is used to store auxiliary data
- Elasticsearch is used to search through different types of data and as a segmentation engine
- Apache Flink is used as a stream processing engine and for delayed trigger management Apache
- Kafka is used as a messaging system between services
Background
Helpshift is a digital customer service platform that provides a means for users to engage in a conversation with brands. It is comprised of many features which can be applied to incoming conversations. To name a few: automated rule application, segregation by properties, custom bots, auto-detection of topic, SLA management, real time statistics, an extensive search engine among others. Helpshift’s platform handles a scale of 180K requests per second currently and the scale keeps growing day by day. Sometimes, with growing scale, it is required to re-architect systems for facilitating the next phase of the company’s growth. One such area of re-evaluation and re-architecture was the management of user profiles.
Problem statement
Up until 2018, a user was registered on Helpshift when they had started a conversation on the Helpshift platform. At this point, a user ID would be generated for this user by the backend servers. The user ID would be used in all future calls to refer to this user. In this legacy user profile system, there are two important things to note:
- A user was created by starting a conversation only when they interacted with the system
- A user was bound to a device
While this system worked well for us for quite a while, we now wanted the user to be decoupled from the device. This meant that a user should be identified by some identifier outside of the Helpshift system. If someone logs into Helpshift from one device, his/her conversations should now be visible on any other device they logged into. Along with this, we also wanted to change the time at which users were created. This would enable us to provide proactive support to users even when they haven’t started a conversation.
These two requirements meant that we had to re-engineer the user subsystem at Helpshift, mainly because:
- CRUD operations on the user data will be much higher
- User authentication will have to be done via multiple parameters
With this change, we were expecting the number of users to be 150+ million and the number of requests to the users database to be 30K/sec. This was far too much for the current database we were using. Moreover, the nature of the data and access patterns warranted a very robust database. Firstly, the number of users would continue to grow over time. Secondly, the number of requests per second was unpredictable. Thus, we had to look to a model of databases which could scale as per need.
The database needed to support “sharding data” out of the box and adding capacity without skipping a beat in production. To “shard” data, essentially means to horizontally split data into smaller parts. The parts are then stored on dedicated database instances. This divides both the amount of data stored on each instance and the amount of traffic served by one instance.
Available Options
There are many varieties of sharded databases available in the industry today. We evaluated the most promising ones from the standpoint of properties we would like to have in our sharded databases. Our comparison included Cassandra, ScyllaDB, Voldemort, sharded MongoDB, and Google Cloud Spanner.
Our parameters of evaluation were:
- Scalability: How much effort is required to add horizontal capacity to a cluster?
- Data model: Is the data model able to support complex queries with “where” clauses?
- Indexing: Are indexes on fields other than primary keys supported?
- Query language: Is the query language expressive enough for production usage?
- Throughput and latency: Are there benchmarks in the literature that studies the throughput/latency?
- Persistence: If a node suddenly dies, is it able to recover without data loss?
- Upgrading to new versions: Are rolling restart/upgrades supported?
In most of the above categories, ScyllaDB emerged as a winner in the properties we wanted in our sharded database. At the time of this work, we used ScyllaDB 2.0.1 and the following were the reasons for choosing ScyllaDB over the other candidates:
- The throughput was by far the highest (for a generic benchmark)
- Adding a node to a live cluster was fairly easy
- Features like secondary indexes were proposed for release in the near future
- ScyllaDB and Cassandra are fundamentally sharded databases and it is impossible to bypass the sharding (and thereby impossible load the cluster with scan-queries across nodes)
Schema design
Moving to a sharded database requires a change of the data model and access patterns. The main reason for that is that some fields are special in sharded systems. They act as keys to find the instance where this particular bit of data will be present. This means that these shard keys always have to be present as part of the query. It therefore makes it imperative to design the data model with all possible query patterns in mind, as it is possible that some queries are just not serviceable in sharded databases.
For this, we created auxiliary tables to find the shard-key of an entity. For example, if we want the data model to have the ability to find a user both by email and username, then we need to be able to make both the following queries:
SELECT * from users where user_id='1234';SELECT * from users where email='abcd@hotmail.com';
This kind of query is not possible on sharded systems since each table can only have one primary or shard key. For this we introduced an intermediate table which would store the mapping from user_id to id and email to id for every user, where id is the primary key of the actual users table. A simplified version of our schema looks like:
CREATE TABLE users (id text PRIMARY KEY, user_id text, email text, name text)CREATE TABLE mapping_emails (email text PRIMARY KEY, id text)CREATE TABLE (user_id text PRIMARY KEY, id text) mapping_userids
With this, we can find a user by both id and email with a two-hop query, for example, if we want to find the user with id=’1234′:
SELECT id from mapping_userids where user_id='1234';SELECT * from users where id='<id-from-last-query>';
This data model and schema sufficed for all the requirements we have at Helpshift. It is highly important to check the feasibility of the schema with respect to all query requirements.
Journey to production
Having decided on the schema, we had to benchmark ScyllaDB with the amount of data and scale we anticipated in production. The process of benchmarking was as follows:
- 150 million entities
- 30,000 user reads per second (this will exclude the additional reads we have to do via the lookup tables)
- 100 user writes per second (this will exclude the additional writes we have to do on the lookup tables)
- Adding a node to a live loaded cluster
- Removing a node from a live cluster
- 12 hour period for benchmark with sudden bursts of traffic
We benchmarked with the following cluster:
- 10 nodes of size i3.2xlarge
- Replication factor=3
- Leveled compaction strategy
- Quorum consistency
With this setup, we were able to achieve:
- 32,000 user reads/sec (actual number of operations on ScyllaDB were 150K/sec because of lookups and other business logic)
- Average latency of 114 ms
- Seastar reactor utilization 60%
As the benchmark results looked formidable, we therefore went to production with ScyllaDB. It has been a year with ScyllaDB in production and right now the cluster setup is as shown below:
- 15 nodes i3.2xlarge
- 73K user reads/sec at peak (which is 1151 IOPS on average)
- Latency of 13 ms (95th percentile)
- Average reactor load: 50%
- Approximately 2 billion entries (which is 2.8 TB on disk)
Here are some of the metrics from our production ScyllaDB cluster:
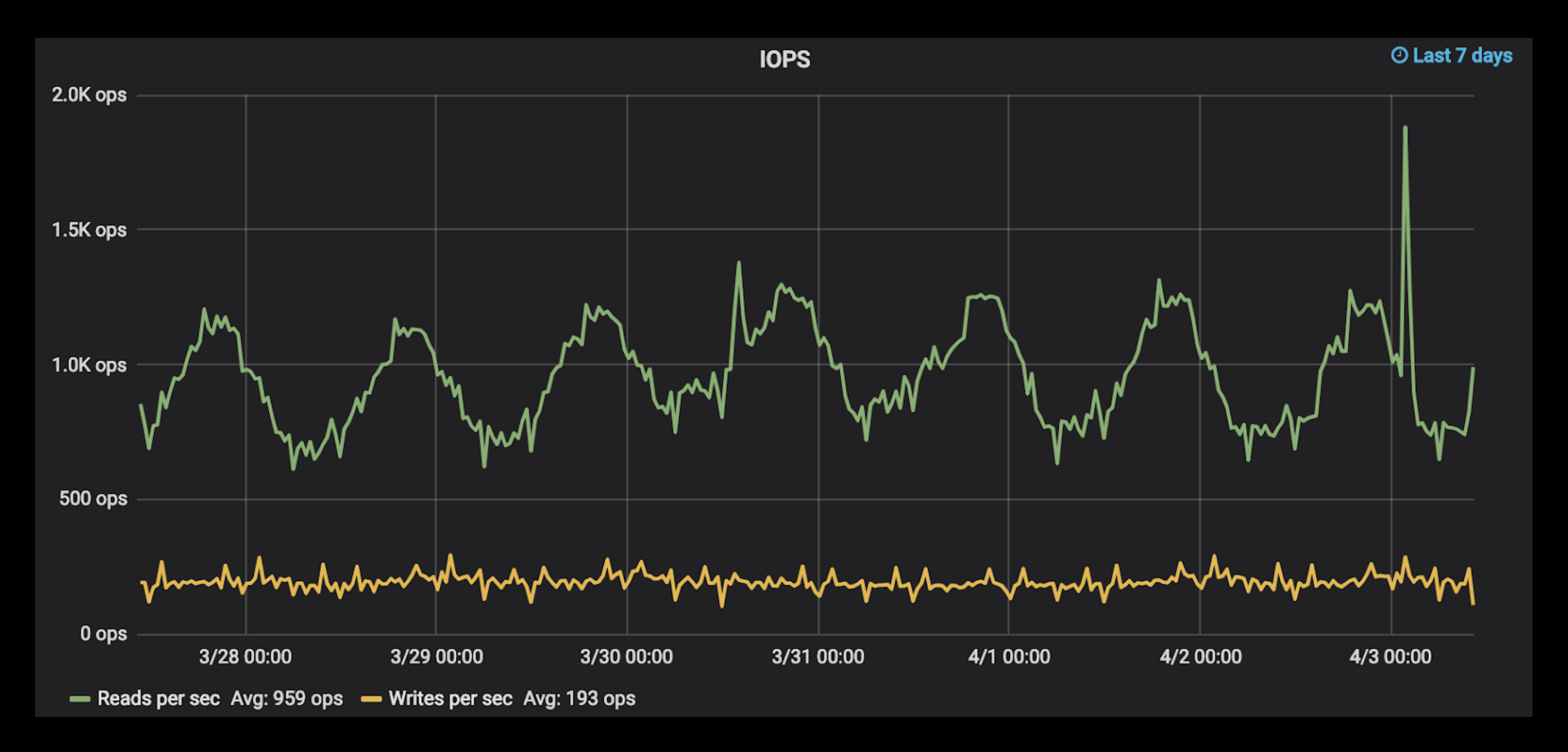
Figure 1: Disk IOPS across the ScyllaDB cluster: 959 reads/sec and 193 writes/sec
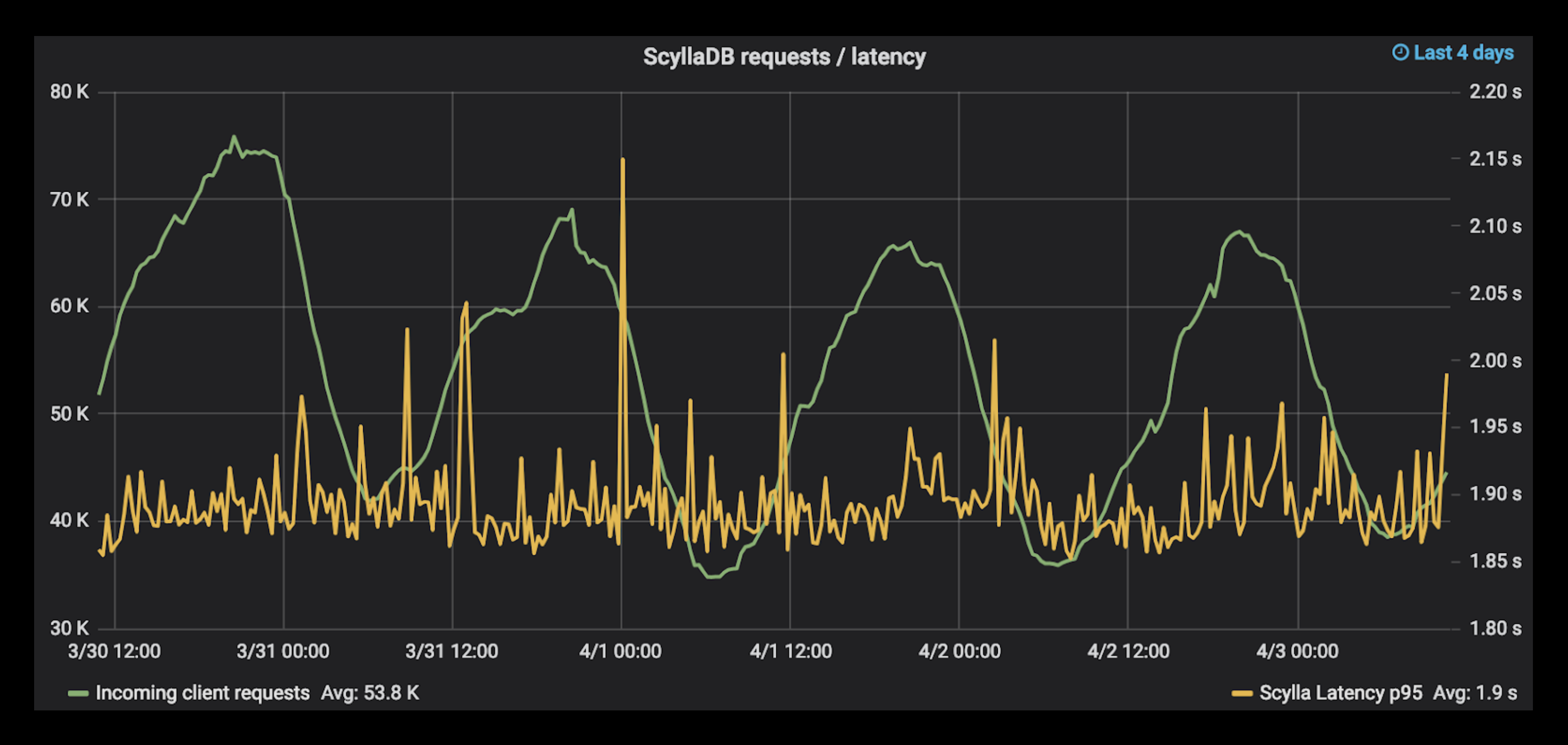
Figure 2: Number of incoming client requests and the ScyllaDB latency for each (note that a client request here is a request coming into the Helpshift infrastructure from outside and can comprise more than one operation on ScyllaDB. The latency is for all ScyllaDB operations combined for one client request.)
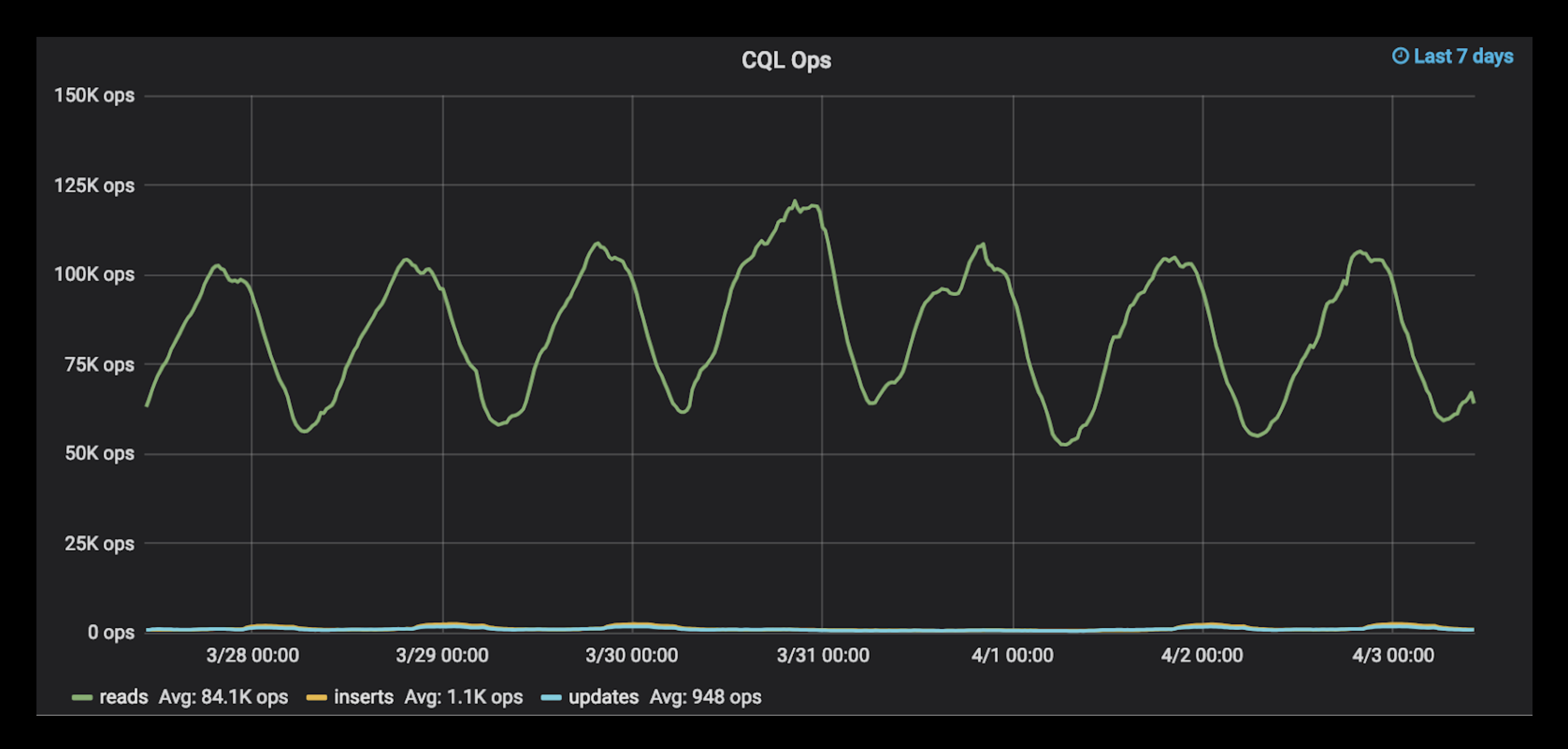
Figure 3: The number of CQL operations on the ScyllaDB cluster grouped into reads, inserts and updates.
Conclusion
The decision to move to a sharded database comes as a natural evolution from the growth of a company but choosing the right database to keep scaling can both be a daunting and rewarding task. In our case, we chose ScyllaDB. If we look at the results closely, the scale we benchmarked for was overcome in production in a course of one year. That is, in just one year, the number of requests we had to serve went from 30K/s to 73K/s. This kind of growth did not get bottlenecked by our backend systems solely because we were able to scale up our ScyllaDB seamlessly as was required. This kind of empowerment is crucial to the growth of an agile startup and in hindsight, it was the perfect database for us.
You can read more about Helpshift’s use of ScyllaDB and other technologies, such as their development of ScyllaDBbackup and Spongeblob, at the Helpshift Engineering blog (engineering.helpshift.com).


