ScyllaDB X Cloud has landed. Fast scaling, max efficiency, lower cost. Learn more
Close-to-the-metal architecture handles millions of OPS with predictable single-digit millisecond latencies.
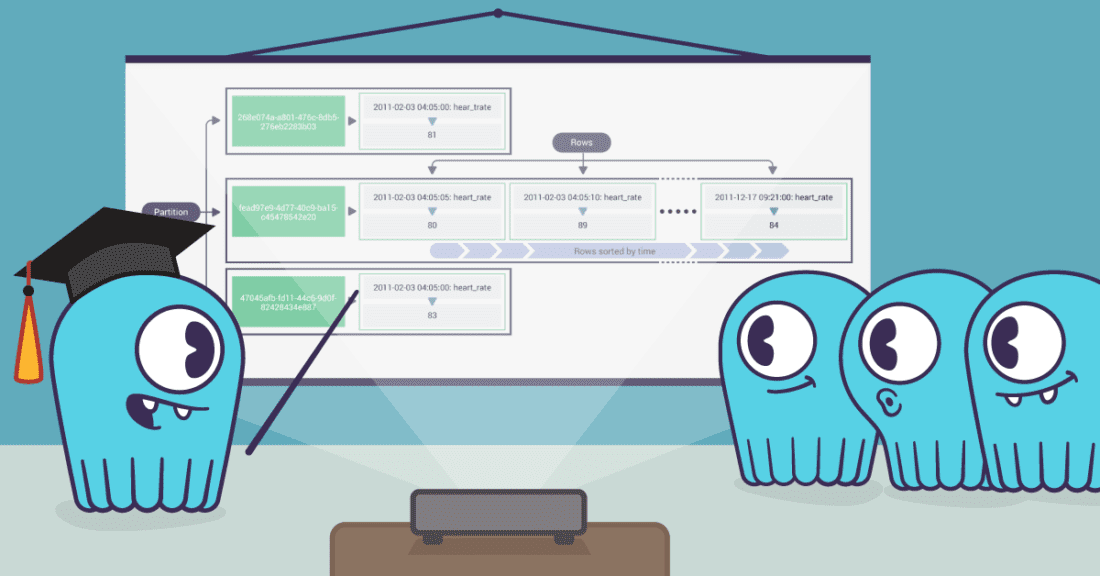
ScyllaDB is purpose-built for data-intensive apps that require high throughput & predictable low latency.
Level up your skills with our free NoSQL database courses.
Our blog keeps you up to date with recent news about the ScyllaDB NoSQL database and related technologies, success stories and developer how-tos.