





NoSQL data modeling initially appears quite simple. Unlike with the traditional relational model, there is no longer a need to reason around relationships across different entities, and the focus shifts to satisfy the required application queries and their access patterns more efficiently. However, the seeming simplicity of NoSQL data modeling can often lead to several hiccups that may inflict pain immediately or later on come back to haunt you.
With NoSQL data modeling, it’s essential to consider edge cases and to understand and know your access patterns very well. Otherwise, you could end up with performance issues stemming from imbalances across your cluster.
This blog explores general data modeling guidelines that have helped many teams optimize the performance of their distributed databases. It introduces what imbalances are, and covers some well-known imbalance types – such as uneven data distribution and uneven access patterns. For a more detailed explanation of these guidelines, a look at data modeling mistakes in action, and tips for diagnosing problems in your own deployment, see our free NoSQL data modeling masterclass.
Access the Data Modeling Masterclass On-Demand (It’s Free)
Exploring Imbalances
An imbalance is defined as an uneven and abnormal access pattern that introduces heavier pressure in some specific replicas on your distributed database. An imbalance causes some of your replicas to receive more traffic than others. These replicas are overutilized while the remaining cluster members serve less traffic and are underutilized. If the imbalance is not corrected, the busier replicas will inevitably become slower over time, up to a point where latencies will rise to a level that impacts user experience. Eventually, you could reach a point where data cannot be read – or your database stops working altogether.
What exactly do imbalances look like and how do you find them? Let’s take a look at two examples: uneven access patterns and uneven data distribution.
Uneven Access Patterns
The following image shows how reads are balanced across the replicas on a 3 node cluster. 2 nodes are seemingly balanced, except for the green one.
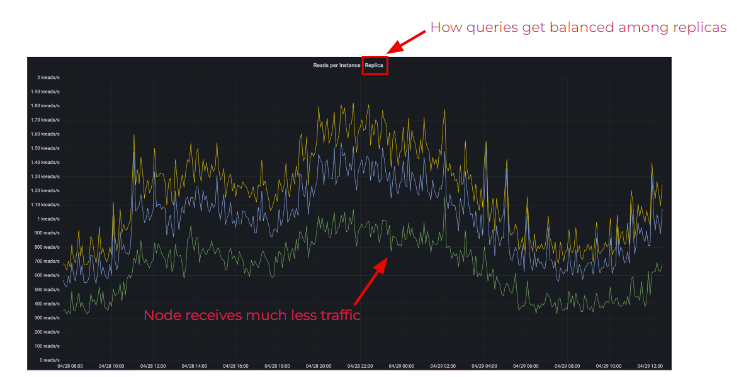
Uneven Access Patterns
Writes will always be replicated to the number of nodes as specified with your replication factor, but reads will be replicated to the number of replicas as specified within your Consistency Level. Here, one node is receiving less traffic than the others. That typically means that there is a problem with the access patterns from an application’s perspective.
For some use cases, it may be hard or nearly impossible to achieve perfectly balanced traffic, but that’s what you should ideally be striving for. Here’s an example of what the ideal state looks like from the perspective of a monitoring dashboard.
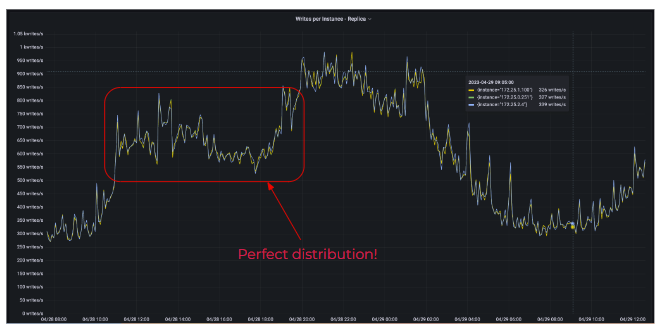
A Perfect Distribution
Here, queries are evenly balanced and distributed across all nodes in a cluster, ensuring that the cluster is functioning smoothly.
Uneven Data Distribution
Here’s another example of a dashboard showing an imbalance:
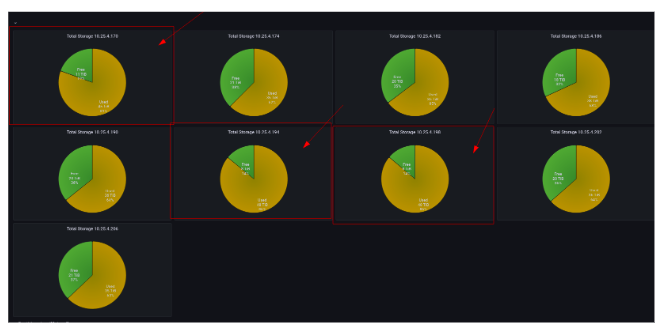
Uneven Data Distribution
Here, the imbalance is related to data distribution. The dashboard shows a 9-node cluster, where 3 of the nodes have a much higher data utilization than the others. This is a very high indication that the cluster in question has large partitions. Given that the data imbalance precisely affects 3 nodes, and that it equals our user’s replication factor, this is yet another indicator for large partitions.
5 Guidelines for Avoiding Imbalances and Other Performance Issues
So how do you avoid such imbalances? Here are 5 guidelines, along with resources that will help you put them into action:
- Follow a query-driven design approach
- Select an appropriate primary key
- Use high cardinality for even data distribution
- Avoid bad access patterns
- Don’t overlook monitoring
Follow a query-driven design approach
With NoSQL data modeling, you’ll always want to follow a query-driven design approach, rather than follow the traditional entity-relationship model commonly seen in relational databases. Think about the queries you need to run first, then switch over to the schema.
Recommended resources:
- ScyllaDB Essentials – Overview of ScyllaDB and NoSQL Basics
- NoSQL Data Modelling Masterclass, Foundations — Introducing Concepts & Principles
- NoSQL Data Modelling Masterclass, NoSQL Data Modeling 101
Select an appropriate primary key for your application’s access patterns
Assuming that you’ve successfully mapped your queries (per the previous guideline), you should end up with a logical primary key selection. The primary key determines how your data will be distributed across the cluster, and it will dictate which queries your clients will be allowed to execute.
Carefully select partition keys to avoid imbalances and therefore ensure that you fully utilize your cluster, rather than end up introducing performance bottlenecks to a few replicas. With any distributed database, the overall cluster performance is always tied to the speed of its slowest replica.
Recommended resources:
- ScyllaDB University – Data Modeling and Application Development
- ScyllaDB Ring Architecture
- Killercoda Data Modeling Lab
Use high cardinality for even data distribution
Select a primary key – specifically a partition key – with high enough cardinality to ensure that 1) your data gets distributed as evenly as possible 2) the load and processing are spread across all members in your cluster.
Recommended resources:
- Best Practices for ScyllaDB Applications
- Why ScyllaDB is Moving to a New Replication Algorithm: Tablets
- Replica Imbalance – ScyllaDB University
- Avoiding Data Hotspots at Scale
Avoid bad access patterns
Avoid hot access patterns, such as hot partitions, which similarly cause an imbalance to how data gets accessed into your cluster. Here, it is worth noting that few access imbalances are normal, and databases like ScyllaDB often come with a specialized cache to ensure that “hot items” are always served efficiently. Still, you should watch for the “hot partitions” effect as it may undermine your latencies in the long run.
Recommended resources:
- Time-Based Anti-Patterns for Caching Time-Series Data
- 5 Tips to Optimize Queries
- Indexes, Filters, and Other Animals
Don’t overlook monitoring
Your database monitoring solution is your main ally for identifying erratic access patterns, troubleshooting imbalances, identifying bottlenecks, predicting pattern changes, and alerting you when things go wrong. Ensure that you install and configure monitoring your database vendor’s monitoring, as well as any other monitoring, observability, or APM tools you generally rely on.
Recommended resources:
- Performance Engineering Masterclass – Part 3
- ScyllaDB Monitoring – ScyllaDB University
- ScyllaDB Monitoring – Optimization Dashboard
Learn More – On-Demand NoSQL Data Modeling Masterclass
Want to learn more about NoSQL data modeling best practices for performance? Catch our NoSQL data modeling masterclass – 3 hours of expert instruction, now on-demand (and free).
Designed for organizations migrating from SQL to NoSQL or optimizing any NoSQL data model, this masterclass will assist practitioners looking to advance their understanding of NoSQL data modeling. Pascal Desmarets (Hackolade), Tzach Livyatan (ScyllaDB) and I team up to cover a range of topics, from building a solid foundation on NoSQL to correcting your course if you’re heading down a dangerous path.
You will learn how to:
- Analyze your application’s data usage patterns and determine what data modeling approach will be most performant for your specific usage patterns.
- Select the appropriate data modeling options to address a broad range of technical challenges, including benefits and tradeoffs of each option
- Apply common NoSQL data modeling strategies in the context of a sample application
- Identify signs that indicate your data modeling is at risk of causing hot spots, timeouts, and performance degradation – and how to recover
- Avoid the data modeling mistakes that have troubled some of the world’s top engineering teams in production


