July 6, 2018 New Benchmark: ScyllaDB 2.2 (i3.Metal x 4-nodes) vs Cassandra 3.11 (i3.4xlarge x 40-nodes) Performance
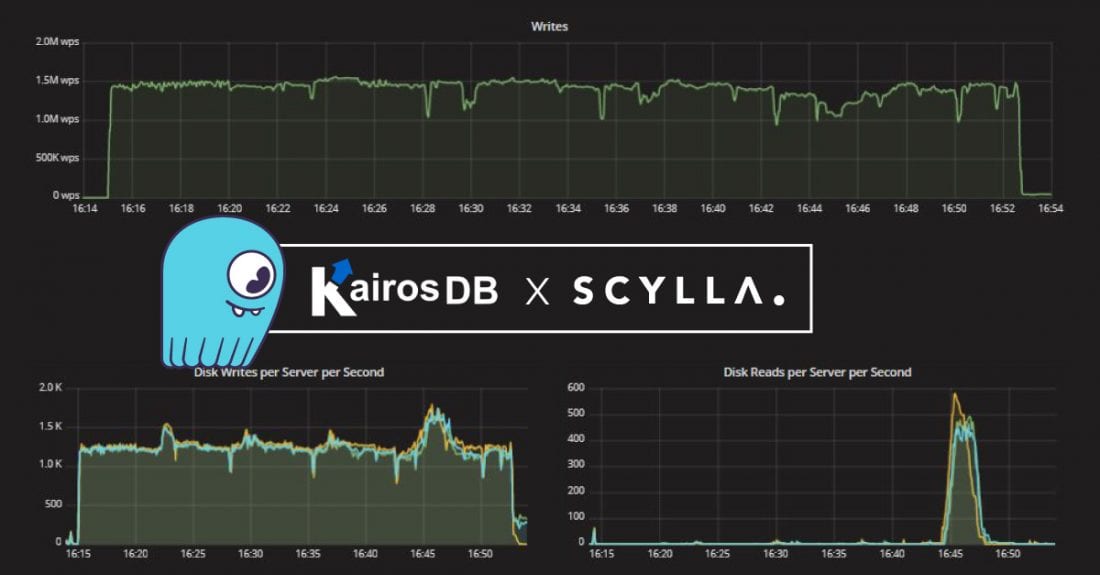
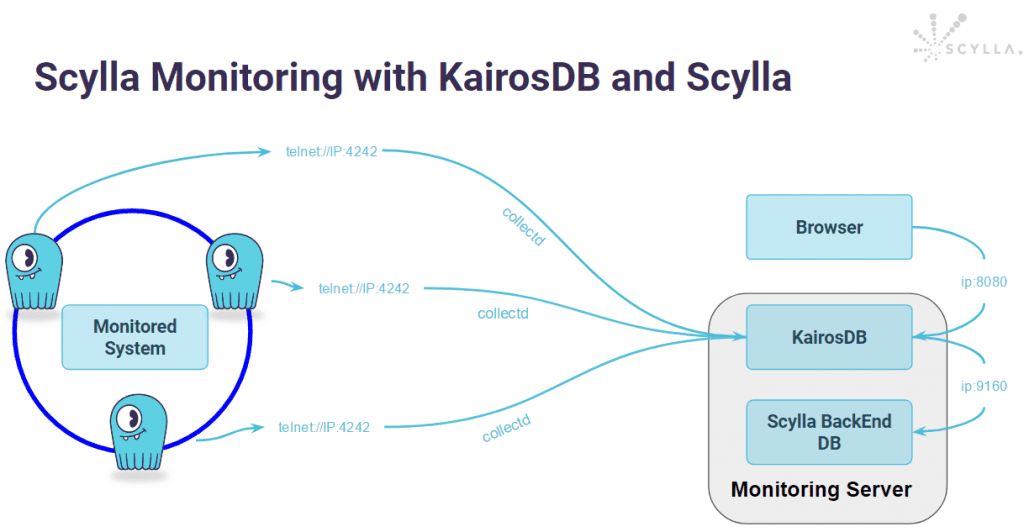
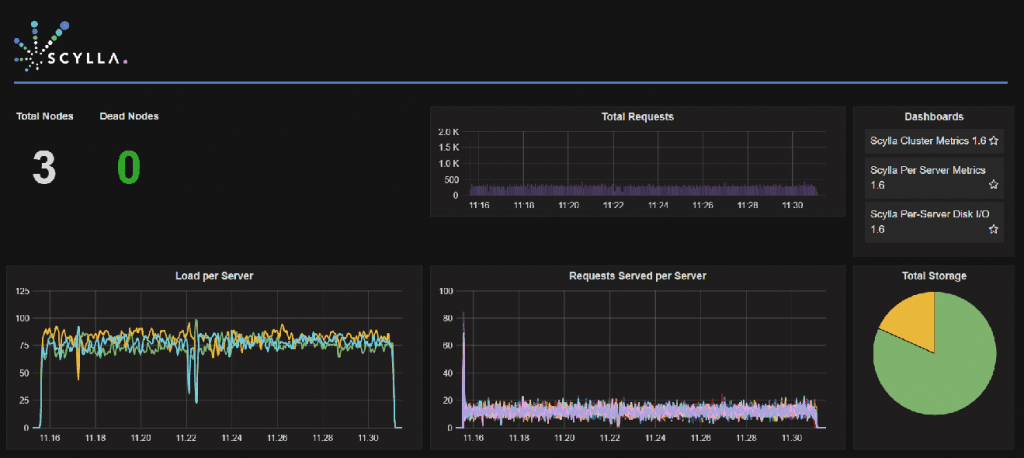
March 20, 2018 KairosDB and ScyllaDB: A Time Series Solution for Performance and Scalability ScyllaDB Open Source, Tutorials, Performance, Integrations
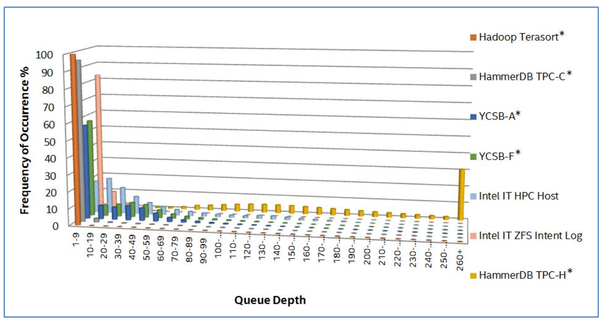
September 27, 2017 Intel Optane and ScyllaDB: Providing the Speed of an In-memory Database with Persistency Tutorials, Integrations, ScyllaDB Open Source
May 24, 2017 9 Steps for Building a Highly Available Time-Series Solution with ScyllaDB and KairosDB Featured, Tutorials
March 28, 2017 How to scan 475 million partitions 12x faster using efficient full table scan with ScyllaDB 1.6 Tutorials, Featured
February 15, 2017 ScyllaDB vs Apache Cassandra – Performance Benchmark by Samsung ScyllaDB Open Source, Performance, Tutorials, Featured