



KairosDB, a time-series database, provides a simple and reliable tooling to ingest and retrieve chronologically created data, such as sensors’ information or metrics. ScyllaDB provides a large-scale, highly reliable and available backend to store large quantities of time-series data. Together, KairosDB and ScyllaDB provide a highly available time-series solution with an efficiently tailored front-end framework and a backend database with a fast ingestion rate.
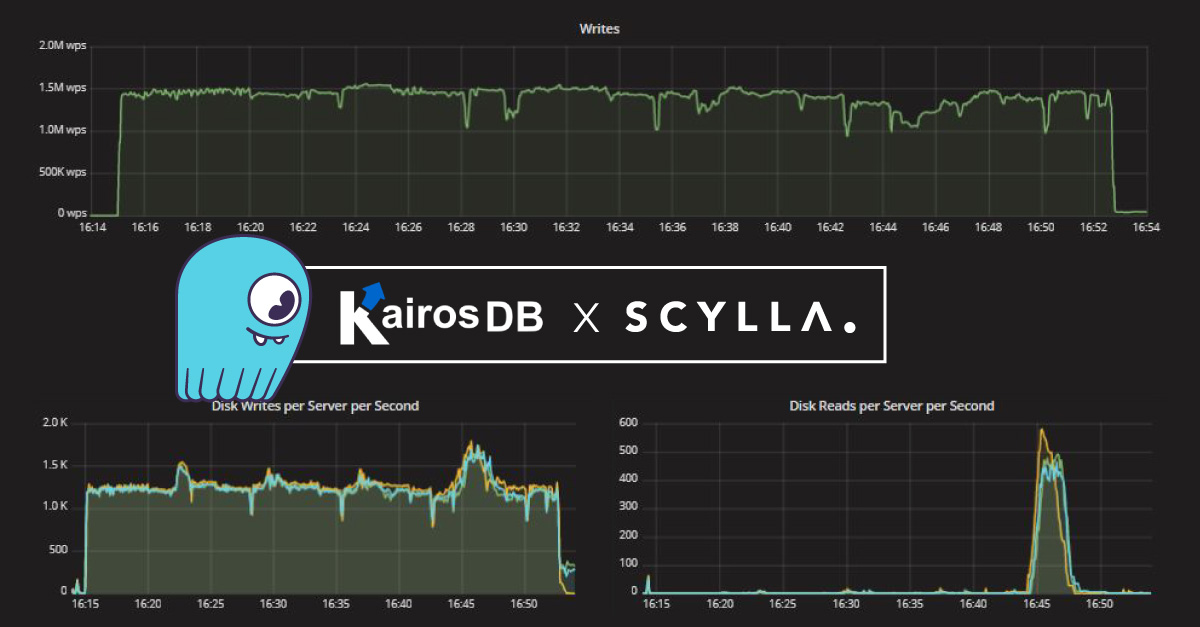
KairosDB v1.2.0 introduced native CQL support and we tasked KairosDB and ScyllaDB for a performance test. We conducted two tests of KairosDB consisting of single and multiple nodes to demonstrate the performance and scalability of this solution.
What is KairosDB?
KairosDB is a fast distributed scalable time-series database. Initially a rewrite of the original OpenTSDB project, it evolved to a different system where data management, data processing, and visualization are fully separated. To learn how to build a highly available time-series solution with KairosDB, watch our on-demand webinar. More information about the ScyllaDB integration with KairosDB can be found in the ScyllaDB docs. For more information about KairosDB, please visit their website.
Why KairosDB and ScyllaDB?
The usage of ScyllaDB as a highly available, distributed data store for KairosDB allows users to store a large number of metrics while easing the concern of data loss. ScyllaDB provides high throughput, low-latency write characteristics to support millions of data point ingestions per second. KairosDB provides users with a simple API to ingest data create aggregations and rollups for fast and reliable metering and reporting. With the KairosDB 1.2 release using the native CQL language, integration of ScyllaDB and KarioDB becomes an easy task. Compared to other solutions, the integration provides unlimited scalability, high availability, and performance. ScyllaDB’s open-source version and KairosDB can scale to an unlimited number of instances.
Testing conf and Setups
- ScyllaDB v2.1 – 3 nodes cluster running on AWS EC2 i3.8xlarge instances
- KairosDB (v1.2.0-0.3beta) and Loaders run on AWS EC2 m5.2xlarge instances
- A dedicated Python code is used to emulate 60K / 180K sensors. Each sensor is emitting 2000 data points at a rate of one data point per second. In other words, 60K / 180K sensors are sending their data to KairosDB every second.
- In the multiple KairosDB nodes test, we shard the clients and distribute the ingesting clients among the KairosDB nodes
- Latency measurements were taken by $ nodetool proxyhistograms before and at the end of each run.
- The KairosDB schema and configuration are available in Appendix-A at the end of this post.
KairosDB Single Instance | 60K Sensors
- Single KairosDB node with a 200GB disk for KairosDB data files queue | KairosDB batch size = 50
- Load: 1 loader (2 python scripts) emulating 60K sensors.
- Runtime: ~40 min
- Total of 120M partitions (data_points) | Total used storage (RF=3): ~12GB
KairosDB Cluster of Instances | 180K Sensors
- 3 KairosDB nodes with 200GB disk for KairosDB data files queue | KairosDB batch size = 15
- In /etc/sysconfig/scylla-server set
SCYLLA_ARGS --background-writer-scheduling-quota = 0.3 - Load: 3 loaders (6 python scripts) emulating 180K sensors. 2 Python scripts per loader.
- Runtime: ~40 min
- Total of 360M partitions (data_points) | Total used storage (RF=3): ~36GB
Batch Usage Notes:
- Batching helps on data aggregation transfers and atomicity of multi-table insertions. For more about batches, read here.
- See Appendix-A below for more details on the values we used
Results

ScyllaDB Avg. CPU-reactor Load
- Single KairosDB Instance: ~30%
- KairosDB Cluster: ~85%
KairosDB Single Instance – nodetool proxyhistogram



KairosDB Cluster of Instances – Screenshots

The “humps” we see in the cpu-reactor load are memtables flush to disk and/or cash merges.


Conclusion
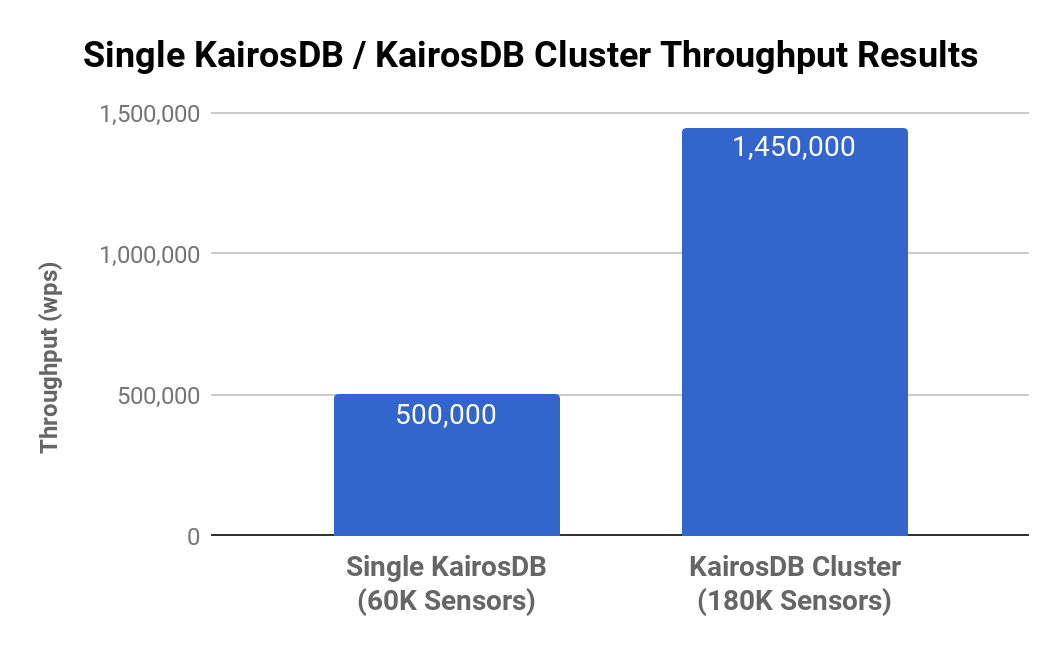
In this post, we demonstrated the performance of ScyllaDB as Backend datastore for KairosDB. ScyllaDB provides low-tail latencies and in this experiment it was no different, keeping both the 95% and 99% latencies at single digits, even when handling writes from 180K sensors per second
We also proved that ScyllaDB’s throughput scales linearly when more KairosDB nodes are added and with little impact on tail latencies. This is all done without making any changes to either the size or available resources of the ScyllaDB Cluster.
ScyllaDB is a great choice for time-series workload.
Next Steps
- Learn more about ScyllaDB from our product page.
- See what our users are saying about ScyllaDB.
- Download ScyllaDB. Check out our download page to run ScyllaDB on AWS, install it locally in a Virtual Machine, or run it in Docker.
Appendix A
KairosDB conf changes:
kairosdb.datastore.cassandra.read_consistency_level=QUORUM
kairosdb.datastore.cassandra.write_consistency_level=ONE (assuming CL=ONE is sufficient for time series writes)
kairosdb.datastore.cassandra.connections_per_host.local.core=30 (number of cores/shards)
kairosdb.datastore.cassandra.connections_per_host.local.max=30 (same)
kairosdb.datastore.cassandra.connections_per_host.remote.core=30 (same)
kairosdb.datastore.cassandra.connections_per_host.remote.max=30 (same)
kairosdb.datastore.cassandra.max_requests_per_connection.local=8 (default=128, Brian H. recommended using a lower value) kairosdb.datastore.cassandra.max_requests_per_connection.remote=8
kairosdb.ingest_executor.thread_count=20 (default was 10)
kairosdb.queue_processor.batch_size=50 (single KairosDB node) / 15 (three KairosDB nodes) (default: 200)
kairosdb.queue_processor.min_batch_size=50 / 15 (default: 100)
Notes:
- ScyllaDB is using 30 CPU threads (out of 32) as 1 physical core is dedicated for interrupts handling
- Testing found that it is necessary to use a smaller value than the default setting. This was because one of ScyllaDB’s shard handling batches can spike to 100% CPU when handling a heavy load from KairosDB. This leads to write timeouts and poor latency results. In the example, we found the best performance when set to 50. If you are using 3 nodes, you need to divide the batch size evenly (20 per node for example) per node.
KairosDB default schema (RF = 3)



