A parallel full table scan is faster!
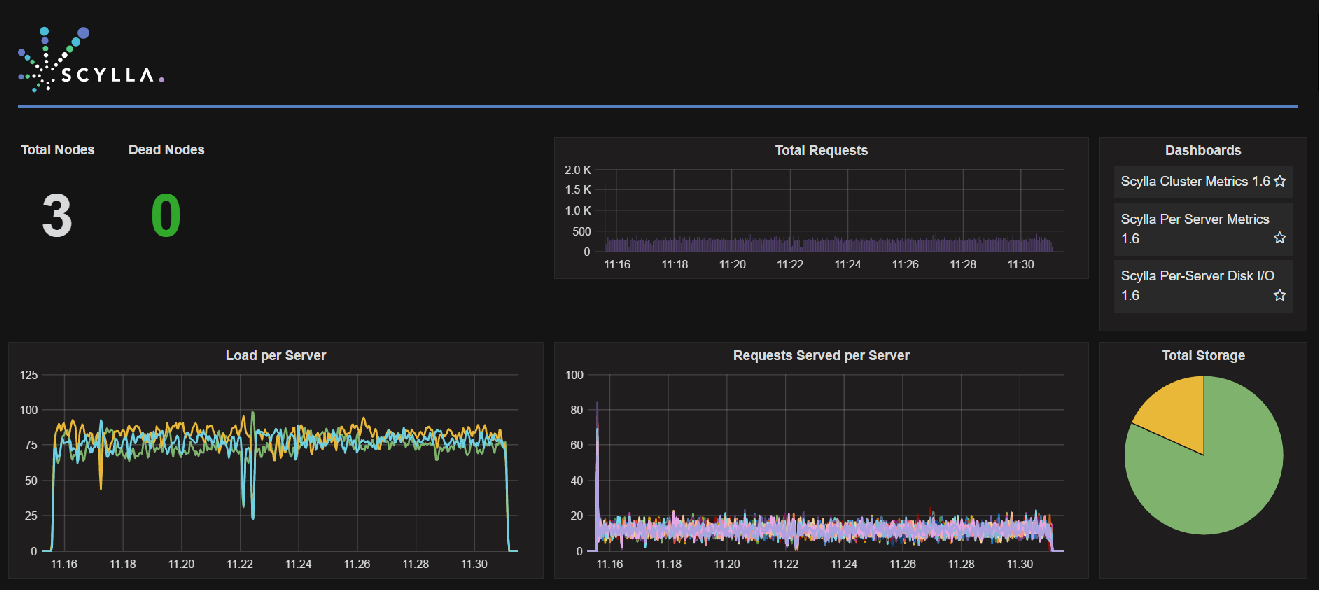
By running a traditional serial full table scan on 475 million partitions (screenshot 1) from one client with a single connection per node, ScyllaDB achieves only 42,110 rows per second. However, by using an efficient, parallel full table scan (screenshot 2), ScyllaDB single client scans 475 million partitions in 510,752 rows per second rate—12x faster!
Screenshot 1: Traditional serial full table scan
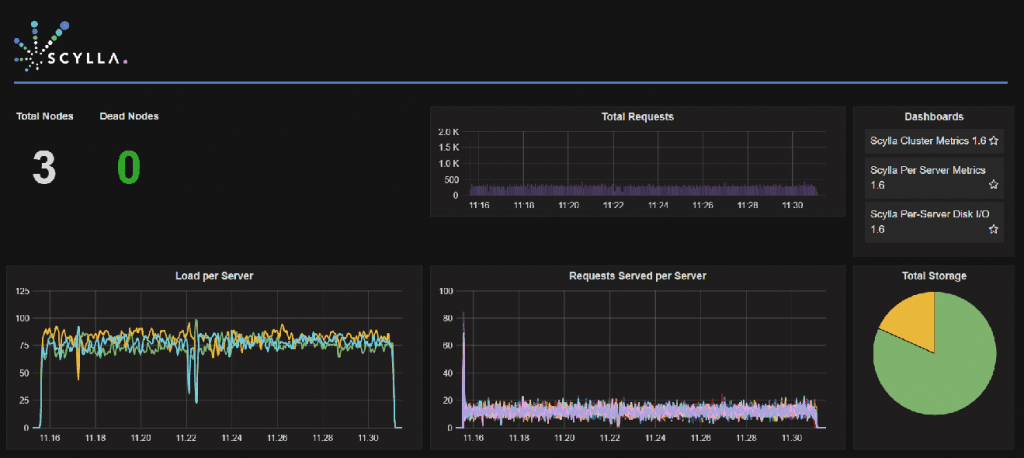
Screenshot 2: Efficient parallel full table scan
Background
Full table scan, often used for data analytics, is a heavy operation on any database. However, there is a way to utilize ScyllaDB architecture to gain server and core parallelism optimization. Simply running multiple queries on a range of the partition keys will not work, as the data is not stored in partition key sort order.
SELECT * FROM keyspace1.standard1 WHERE id >= 0 AND id <= 999 ;
InvalidRequest: code=2200 [Invalid query] message="Only EQ and IN relation are supported on the partition key (unless you use the token() function)"ScyllaDB orders partitions by a function of the partition key (a.k.a token function), hence you can run multiple queries with different ranges by using the partition token within a WHERE clause. The token function has a range of -(2^63-1) to +(2^63-1); this translates to -9223372036854775807 ≤ token(id) ≤ 9223372036854775807.
Note: we recommend selecting only required columns to eliminate unnecessary network traffic and processing.
SELECT id FROM keyspace1.standard1 WHERE token(id) >= -9223372036854775807 LIMIT 3 ;
system.token(id) | id
---------------------+----
-8891365815796773461 | 754
-3611158112396353831 | 251
- 187437814682527445 | 945How many token ranges should I scan in parallel?
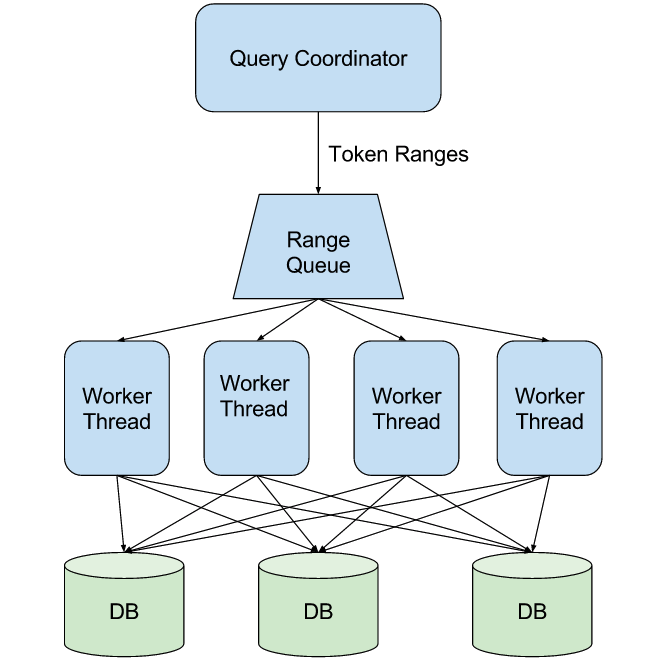
A good rule-of-thumb is to take the number of cores per node, multiply by the number of nodes, and multiply by a further “smudge factor”: N = Parallel queries = (nodes in cluster) ✕ (cores per node) ✕ 3 (smudge factor).
In order to have an ongoing queue and utilize all cores for maximum parallelism, make sure you also do the following:
- Divide the full token range to a larger number: M = N * 100 (each query will cover smaller token range)
- Randomize the execution of the query statements, so all shards will kick-in right from the start
M token ranges will be processed in a randomized queue (making the full table scan), but only N will be done in parallel on all shards; the rest will wait. As a token range query completes, we will pick a new token range query and start processing it, until we have completed M (all token ranges = full table scan).
From theory to action – time for a demo
We will use the following setup for this purpose:
- ScyllaDB cluster: 3 x RHEL7.2 nodes deployed on Google Compute Engine (GCE), each has 8 vCPUs and 30GB memory.
- Storage: each node has 2 x 375GB local SSDs (NVMe) disks
- Client: CentOS 7.2 node deployed on GCE (4 vCPU and 15GB memory) will run our golang code using gocql driver
- Client prerequisites:
- Install Go 1.7
- Install gocql driver: “go get github.com/gocql/gocql”
- Install kingpin pkg: “go get gopkg.in/alecthomas/kingpin.v2”
In this example N = 72 and M = 7200, hence the full range of the tokens will be divided into 7200 token ranges. Every select statement will cover a token range of 2562047788015216 partitions, thus the request per second metric will show only 1 request x the number of shards in the ScyllaDB cluster (in our case 24). The average request size is ~1.48MB.
SELECT token(id), id FROM keyspace1.standard1 WHERE token(id) >= -9223372036854775807 AND
token(id) <= -9220809989066760591 ;After injecting 475 million partitions from multiple loaders, using Cassandra stress, we ran golang code to perform the full table scan.
Note the list of variables to configure in the golang code:
- Your ScyllaDB cluster setup (# of nodes, # of cores per node, smudge factor)
- Adjust the query template to your keyspace.table_name and token(key)
- ScyllaDB cluster IPs
- Consistency level for the gocql (for better results use ‘one’ or ‘localone’ for multi DC)
- Cluster timeout (as these are heavy queries with large result set, I use 15 sec so not to fail on timeouts)
- CQL version (gocql driver will try from v4 downwards to find a match, use v3.0.0 to save time)
- Page size (default = 5000), can be tweaked if needed; average request size is ~1.48MB. Reducing the page size will increase the total requests rate, but this will not necessarily lead to better rows per second rate
To try it yourself, go to our GitHub repo, download the golang code, and let us know your results!