This is the second post in a series of four about the different compaction strategies available in ScyllaDB. In the previous post, we introduced the Size-Tiered compaction strategy (STCS) and discussed its most significant drawback – its disk-space waste, a.k.a. space amplification. In this post, we will look at Leveled Compaction Strategy (LCS), the first alternative compaction strategy designed to solve the space amplification problem of STCS, and show that it does solve that problem, but unfortunately introduces a new problem – write amplification. The next post in this series will introduce a new compaction strategy, Hybrid Compaction Strategy, which aims to solve, or at least mitigate both problems.
Although we discuss the ScyllaDB database throughout this post, everything said here also applies to Apache Cassandra, which also has the Leveled Compaction Strategy that works identically to ScyllaDB’s.
This post and the rest of this series are based on a talk that I gave (with Raphael Carvalho) in the last annual ScyllaDB Summit in San Francisco. The video and slides for the talk are available on our Tech Talk page.
Leveled Compaction Strategy
The Leveled Compaction Strategy was the second compaction strategy introduced in Apache Cassandra. It was first introduced in Cassandra 1.0 in 2011, and was based on ideas from Google’s LevelDB. As we will show below, it solves STCS’s space-amplification problem. It also reduces read amplification (the average number of disk reads needed per read request), which we will not further discuss in this post.
The first thing that Leveled Compaction does is to replace large sstables, the staple of STCS, by “runs” of fixed-sized (by default, 160 MB) sstables. A run is a log-structured-merge (LSM) term for a large sorted file split into several smaller files. In other words, a run is a collection of sstables with non-overlapping token ranges. The benefit of using a run of fragments (small sstables) instead of one huge sstable is that with a run, we can compact only parts of the huge sstable instead of all of it. Leveled compaction indeed does this, but its cleverness is how it does it:
Leveled compaction divides the small sstables (“fragments”) into levels:
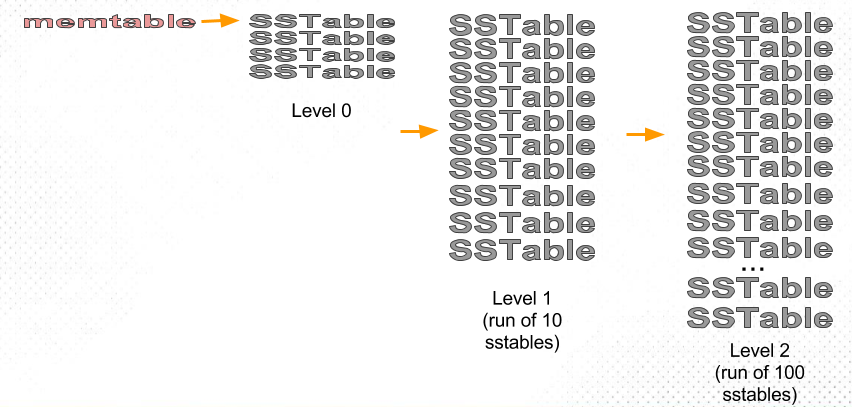
Level 0 (L0) is the new sstables, recently flushed from memtables. As their number grows (and reads slow down), our goal is to move sstables out of this level to the next levels.
Each of the other levels, L1, L2, L3, etc., is a single run of an exponentially increasing size: L1 is a run of 10 sstables, L2 is a run of 100 sstables, L3 is a run of 1000 sstables, and so on. (Factor 10 is the default setting in both ScyllaDB and Apache Cassandra).
The job of Leveled compaction strategy is to maintain this structure while keeping L0 empty:
- When we have enough (e.g., 4) sstables in L0, we compact them into L1.
We do this by compacting all the sstables in L0 together with all the sstables in L1. The result of this compaction is a new run (large sstable split by our chosen size limit, by default 160 MB) which we put in L1, replacing the entire content of L1. - The new run in L1 may have more than the desired 10 sstables. If that happens, we pick one sstable from L1 and compact it into L2:
- A single sstable in L1 is part of a run of 10 files. The whole run covers the entire token range, which means that the single sstable we chose covers roughly 1/10th of the token range. At the same time, each of the L2 sstables covers roughly 1/100th of the token range. So the single L1 sstable we are compacting will overlap around 10 of the L2 sstables.
- So what we do is to take the single L1 sstable and the roughly 10 L2 sstables which overlap its token range, and compact those together – as usual splitting the result into small sstables. We replace the input sstables with the compaction results, putting the results in L2 (note that L2 remains a single run).
- After we compacted a table from L1 into L2, now L2 may have more than the desired number of sstables, so we compact sstables from L2 into L3. Again, this involves compacting one sstable from L2 and about 10 sstables from L3.
- And so on.
Space Amplification in LCS
Let’s explain now why LCS indeed fulfills its ambition to provide low space amplification and therefore indeed solves STCS’s main problem.
In the previous post, we saw that space amplification comes in two varieties: The first is temporary disk space use during compaction, and the second is space wasted by storing different values for the same over-written rows.
LCS does not have the temporary disk space problem which plagued STCS: While STCS may need to do huge compactions and temporarily have both input and output on disk, LCS always does small compaction steps, involving roughly 11 input and output sstables of a fixed size. This means we may need roughly 11*160MB, less than 2 GB, of temporary disk space – not half the disk as in STCS.
LCS also does not have the duplicate data problem. The reason is that most of the data is stored in the biggest level, and since this level is a run – with different sstables having no overlap – we cannot have any duplicates inside this run. Let’s explain this more rigorously.
The best case for LCS is that the last level is filled. For example, if the last level is L3, it has 1000 sstables. In this case, L2 and L1 together have just 110 sstables, compared to 1000 sstables in L3. All sstables have the same size so roughly 90% of all the sstables, and therefore, 90% of all the data, is in L3. L3 is a run and therefore cannot have any duplicate data. So at most, we can have 10% duplicated data (if all the data in L1 and L2 happens to be overwrites to data that we have in L3). So we can have at most 1.11-fold (= 1/0.9) space amplification. This is, of course, a great result – compare it to the almost 8-fold space amplification we saw in the previous post for STCS!
However, in its current implementation (in both ScyllaDB and Cassandra), LCS doesn’t always provide such excellent space amplification. It actually has a worst case where we can get 2-fold space amplification. This happens when the last level is not filled, but rather only filled as much as the previous level. E.g., consider that we have a filled L2 with 100 sstables but L3 also has just 100 sstables (and not 1000). In this case, the last level only has about half of the data, half of the data may be duplicated, so we may see 2-fold space amplification. The paper Optimizing Space Amplification in RocksDB suggests that this can be fixed by changing the level sizes so that instead of insisting that L3 has exactly 1000 sstables, we focus on L3 having 10 times more sstables than L2. Neither ScyllaDB nor Cassandra have this fix yet, so in worst case during massive overwrites, their LCS may still have space amplification of 2. As unfortunate this is, it is of course not nearly as bad as the 8-fold space amplification we saw for STCS.
In the previous post, we looked at two simple examples to demonstrate STCS’s high space amplification. Let’s see how LCS fares in these examples.
The first example was straightforward writing of new data at a constant pace, and we saw high temporary disk space use during compaction – at some points doubling the amount of disk space needed. With LCS, this problem is gone, as we can see in the graph below: compaction does require some temporary space, as evidenced by the green spikes in the graph, but these spikes are much smaller than the purple (STCS) spikes, and not proportional to the amount of data in the database (note that in this test, we lowered the LCS sstables’s size from the default 160 MB to 10 MB, so we can meaningfully demonstrate LCS on this relatively small data set).

The second example we saw in the previous post was an overwrite workload, where the same 1.2 GB data set was written over and over, 15 times. With size-tiered compaction, we saw huge space amplification – as much as 9.3 GB was needed on disk (almost 8-fold space amplification) at several times during the run. With leveled compaction, space amplification was much lower as can be seen in the graph below. We see that the space amplification actually reaches more than the expected 1.1 – 2, because we wait for 4 sstables to collect in L0 before compacting, and in this setup, 4 L0 sstables are around 400 MB of data which is all duplicate data as well.
Write Amplification
So Leveled Compaction Strategy is the best invention since sliced bread, right?
Unfortunately, while solving, or at least significantly improving, the space amplification problem, LCS makes another problem, write amplification, worse.
“Write amplification” is the amount of bytes we had to write to the disk for each one byte of newly flushed sstable data. Write amplification is always higher than 1.0 because we write each piece of data to the commit-log, and then write it again to an sstable, and then each time compaction involves this piece of data and copies it to a new sstable, that’s another write.
Let’s look at an example of write amplification with STCS. in the first experiment we saw above (and in the previous post), we wrote 8.8 GB of new data – this is the sstable size at the end of the test. But if we ask ScyllaDB for the counter of bytes written to disk during this experiment, we get 50 GB. This means we had a write amplification of over 5.
It is easy to understand where this amplification comes from: In that experiment, we saw sstables in four size tiers: 100 MB, 400 MB, 1.6 GB and 6.4 GB. By the end of the run, most of the data was in the largest sstable and for each byte of data to reach there it had to be written four times: once when flushed into an sstable for the first time, and three more times as it is compacted from one tier into the next larger tier. Add to this an additional write for the commit log, and we reach the measured write amplification of 5 (see the following figure for an illustration).

This write amplification can be somewhat reduced by increasing the amount of memory devoted to memtables – so that the size of the smallest sstables is larger and the number of tiers decreases. Note that as the data size grows, the number of tiers, and therefore the write amplification, will grow logarithmically (O(logN)). This is not surprising considering that external sorting has O(N logN) complexity.
But, it turns out that the write amplification for Leveled Compaction Strategy is even worse. Significantly worse. In the above example, we measured 111 GB of writes – that’s 13-fold write amplification, and over twice the write amplification of STCS. And this is actually a “good” case. To understand, let’s look at why write amplification is significantly higher in LCS than in STCS.
At first glance, both compaction strategies have roughly the same number of tiers (in STCS) or levels (in STCS) through which each piece of data needs to be copied until it reaches the highest tier or level – where most of the data lives. But there is a significant difference:
- STCS picks several (e.g., 4) sstables of total size X bytes to compact, and writes the result, roughly X bytes (assuming no overwrites).
- LCS picks one sstable, with size X, to compact. It then finds the roughly 10 sstables in the next higher level which overlap with this sstable, and compacts them against the one input sstable. It writes the result, of size around 11*X, to the next level.
So LCS may, in the worst case, write 11 times more than STCS!
These are worst-case write amplification numbers and do not apply to every workload. For some types of write-heavy workloads, these high write amplification numbers are not reached in practice: One particularly good case for LCS is a write workload with high time locality, where recently-written data has a high probability of being modified again soon, and where the events of adding completely new data or modifying very old data are relatively infrequent. In such a use case, we most frequently compact the low levels (most frequently L0 and L1), and because most of the writes are modifications of data in those low (and recently written!) levels, the low levels do not grow or necessitate cascading compactions into the higher levels. Because it is those cascading compactions which bring the very high write amplification, a workload which rarely has them is immune to this issue, and a good match for LCS.
Also, in small examples, like the one we tried above, there is another reason why we do not reach high write amplification. This is because the amplification for the L0->L1 compaction is lower (we take more than one input sstable), and because the highest tier is not full. In the above example, we measured a write amplification “only” twice that of STCS, but that’s already bad. And of course the worst case – of writing 11 times more than STCS – is terrible.
But why is it terrible? At this point you may be asking yourself: Why does the high write amplification of LCS really matter? For which kinds of workloads does it cause serious problems? Let’s answer this question, then 🙂
Why Does Write Amplification Matter?
For write-only or write-mostly workloads, the importance of not doing 11 times more write I/O is obvious. For such workloads, LCS will have terrible performance, and not be a reasonable choice at all (however, do note that above we saw that some specific types of workloads, those mostly overwriting recently-written data, have low write-amplification in LCS). In the next post, we will look at a different compaction strategy – Hybrid Compaction – which retains STCS’s low write amplification, and which should be considered instead.
The other extreme is a read-only workload or one with very rare updates. For these types of workloads, write amplification does not matter, and LCS is a great choice as it provides low space amplification and read amplification.
But the more interesting – and typical – case is a mixed workload with a combination of reads and writes. Consider a workload with 10% writes, 90% reads – can we say it is “read mostly” and recommend LCS like we did for read-only workloads? Unfortunately, the answer is often no.
10% writes may sound not much, but when you combine the fact that often many reads are satisfied from the cache (reducing the amount of read I/O) and that each write request is amplified 13-fold (in our experiment) or even 50-fold, we can easily reach a situation where a majority of the disk’s bandwidth goes to the writing activity. In this way, write-amplification can nullify all the advantages of LCS:
- As more disk bandwidth is dedicated to writes, read requests are slowed down, which makes LCS’s superior read performance (90% of the read requests need to read from a single sstable) moot.
- If disk bandwidth needed by writes exceeds what we can do, LCS compaction can no longer keep up. This could cause LCS to leave too many sstables in L0, and result in unbounded space and read amplification. For this reason, ScyllaDB (and Cassandra) have an emergency mode, where if we have too many sstables piling up in L0, STCS is done inside L0 (to at least replace the many small files thereby fewer, larger, files). When we fall back to STCS in this manner we lose all advantages that LCS had in space and read amplification over STCS.
Therefore, the write-amplification problem makes LCS unsuitable for many workloads where writes are not negligible – and it is definitely unsuitable for workloads which are write-heavy.
What’s Next?
In this post, we saw that although the Leveled Compaction Strategy solves the serious space-amplification problem of the Size-Tiered Compaction Strategy, it introduces a new problem of write-amplification. We end up writing the same data to disk over-and-over many more times than STCS did, which in many mixed read-write workloads can cause the disk to not be able to keep up, and both write and read performance can suffer.
Therefore, in the next post, we go back to the drawing board, and design a new compaction strategy based on Size-Tiered compaction strategy, sharing its low write amplification, but solving, or at least significantly reducing, STCS’s space amplification problem. This new compaction strategy is called Hybrid Compaction Strategy and is new to the ScyllaDB Enterprise Version.