




There are many reasons to be excited about generics in Go. In this blog post I’m going to show how, using the generics, we got a 40% performance gain in an already well optimized package, the Google B-Tree implementation.
A B-Tree is a kind of self-balancing tree. For the purpose of this blog post it’s sufficient to say that it is a collection. You can add, remove, get or iterate over its elements. The Google B-Tree is well optimized, measures are taken to make sure memory consumption is correct. There is a benchmark for every exported method. The benchmark results show that there are zero allocations in the B-Tree code for all operations but cloning. Probably it would be hard to further optimize using traditional techniques.
ScyllaDB and the University of Warsaw
We have had a longstanding relationship with the Computer Science department at the University of Warsaw. You may remember some of our original projects, including those integrating Parquet, an async userspace filesystem, or a Kafka client for Seastar. Or more recent ones like a system for linear algebra in ScyllaDB or a design for a new Rust driver.
This work was also part of our ongoing partnership with the University of Warsaw.
Making Faster B-Trees with Generics
While working on a new Scylla Go Driver with students of University of Warsaw, we ported the B-tree code to generics. (If you’re not familiar with generics in Go, check out this tutorial.).
The initial result: the generics code is faster by 20 to 30 percent according to the Google benchmarks (link to issue we opened). Below a full benchmark comparison done with benchstat.
This is great but within those numbers there is a troubling detail. The zero allocations is not something that you would normally see given that the functions accept an interface as a parameter.
For the rest of the blog post we’ll focus on benchmarking the ReplaceOrInsert function responsible for ingesting data. Let’s consider a simplified benchmark.
The results show even greater improvement: 31% vs. 27%, and allocations drop from 1, in case of the interface based implementation, to 0 in the case of generics.
Let’s try to understand what happens here.
The Additional Allocation
The Google benchmarks operate on a B-tree of integers hidden by an Item interface. They use pre-generated random data in a slice. When an Item is passed to the ReplaceOrInsert function the underlying integer is already on the heap, technically we are copying a pointer. This is not the case when a plain integer needs to be converted to an Item interface — the parameter values start “escaping to heap”.
Go has a feature of deciding if a variable you initialized should live in the function’s stack or in the heap. Traditionally the compiler was very “conservative” and when it saw a function like func bind(v interface{}) anything you wanted to pass as v would have to go to heap first. This is referred to as variable escaping to the heap. Over the years the compiler has gotten smarter, and calls to local functions or functions in other packages in your project can be optimized, preventing the variables from escaping. You can check for yourself by running go build -gcflags="-m" . in a Go package.
In the below example Go can figure out that it’s safe to take a pointer to the main functions stack.
As you can see the compiler informs us that variables do not escape to heap.
By changing the ToString implementation to
we see that the variables and literal values do start escaping.
In practical examples, when calling a function that accepts an interface as a parameter, the value almost always escapes to heap. When this happens it not only slows down the function call by the allocation, but also increases the GC pressure. Why is this important? The generics approach enables a truly zero allocation API, with zero GC pressure added as we will learn in the remainder of this blog post.
Why is it faster?
The B-tree, being a tree, consists of nodes. Each node holds a list of items.
When the Item is a pre-generics plain old interface, the value it holds must live separately somewhere on the heap. The compiler is not able to tell what is the size of an Item. From the runtime perspective an interface value is an unsafe pointer to data (word), a pointer to its type definition (typ), a pointer to interface definition (ityp); see definitions in the reflect package. It’s easier to digest than the runtime package. In that case we have items as a slice of int pointers.
On the other hand, with generic interface
and a generic type definition
items are a slice of ints — this reduces the number of small heap objects by a factor of 32.
Enough of theory, let’s try to examine a concrete usage. For the purpose of this blog I wrote a test program that is a scaled up version of my benchmark code.
We are adding 100 million integers, and the degree of the B-tree (number of items in a node) is 1k. There are two versions of this program: one uses generics, the other plain old interface. The difference in code is minimal, it’s literally changing btree.New(degree) to btree.New[btree.Int](degree) in line 13. Let’s compare data gathered by running both versions under `/usr/bin/time -l -p`.
| generics | interface | delta | |
| real | 11.49 | 16.59 | -30.74% |
| user | 11.27 | 18.61 | -39.44% |
| sys | 0.24 | 0.6 | -60.00% |
| maximum resident set size | 2334212096 | 6306217984 | -62.99% |
| average shared memory size | 0 | 0 | |
| average unshared data size | 0 | 0 | |
| average unshared stack size | 0 | 0 | |
| page reclaims | 142624 | 385306 | -62.98% |
| page faults | 0 | 0 | |
| swaps | 0 | 0 | |
| block input operations | 0 | 0 | |
| block output operations | 0 | 0 | |
| messages sent | 0 | 0 | |
| messages received | 0 | 0 | |
| signals received | 600 | 843 | -28.83% |
| voluntary context switches | 25 | 48 | -47.92% |
| involuntary context switches | 1652 | 2943 | -43.87% |
| instructions retired | 204760684966 | 288827272312 | -29.11% |
| cycles elapsed | 37046278867 | 60503503105 | -38.77% |
| peak memory footprint | 2334151872 | 6308147904 | -63.00% |
| HeapObjects | 236884 | 50255826 | -99.53% |
| HeapAlloc | 2226292560 | 6043893088 | -63.16% |
Here using generics solves a version of N+1 problem for slices of interfaces. Instead of one slice and N integers in heap we now can have just the slice of ints. The results are profound, the new code behaves better in every aspect. The wall time duration is down by 40%, context switches are down by 40%, system resources utilization is down by 60% — all thanks to a 99.53% reduction of small heap objects.
I’d like to conclude by taking a look at top CPU utilization.
go tool pprof -top cpu.pprof
| generics | interface |
Type: cpu |
Type: cpu |
You can literally see how messy the interface profile is, how gc starts kicking in killing it… It’s even more evident when we focus on gc.
go tool pprof -focus gc -top cpu.pprof
| generics | interface |
Type: cpu |
Type: cpu |
The generic version spent 0.29s (2.62%) in GC while the interface version spent 6.06s accounting for, hold your breath, 32.49% of the total time!
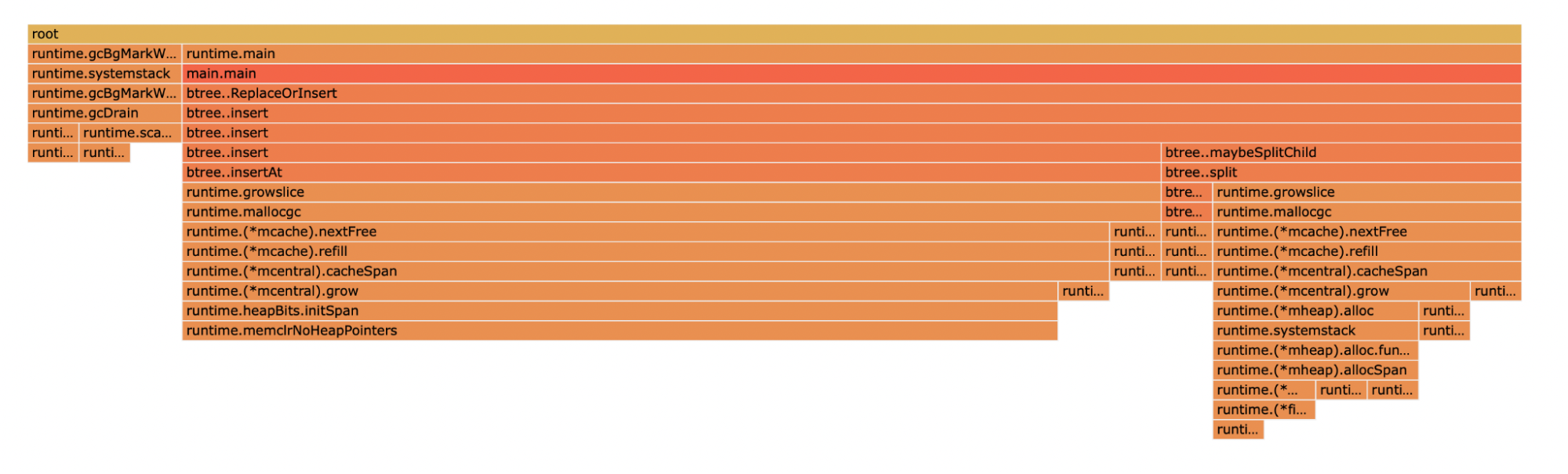 Generics: CPU profile flame focused on GC related function
Generics: CPU profile flame focused on GC related function
 Interface: CPU profile flame focused on GC related functions
Interface: CPU profile flame focused on GC related functions
Conclusion
By shifting the implementation from one using interfaces, to one using generics, we were able to significantly improve performance, minimize garbage collection time, and minimize CPU and other resource utilization, such as heap size. Particularly with heap size, we were able to reduce HeapObjects by 99.53%.
The future of Go generics is bright especially in the domain of slices.
EXPLORE MORE SCYLLADB ENGINEERING CONTENT
Want to be a ScyllaDB Monster?
We’re definitely proud of the work we do with the students at the University of Warsaw. Yet ScyllaDB is a growing company with a talented workforce drawn from all over the world. If you enjoy writing high performance generic Go code, come join us. Or if you specialize in other languages or talents, check out our full list of careers at ScyllaDB:





