



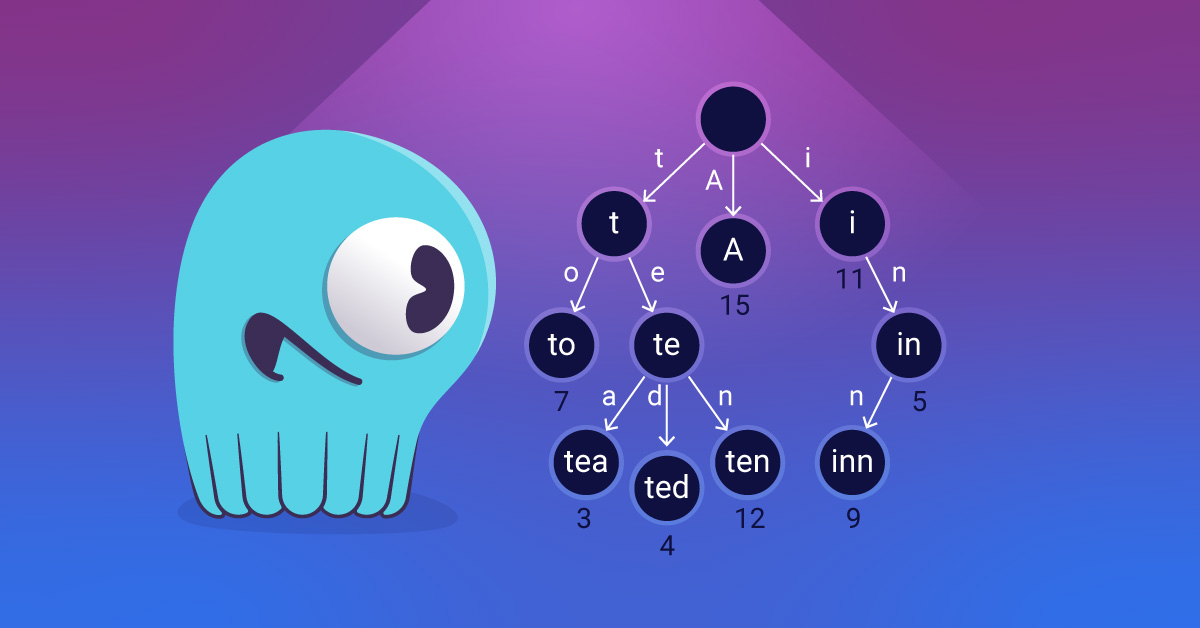
By transitioning from separate summary and index files to a prefix tree, we optimized cache efficiency, reduced disk I/O, and reduced memory overhead
Trie-based SSTable index format was added in ScyllaDB 2025.4. Since then, it has evolved and matured to become the default index format in ScyllaDB 2026.2.
In this post, we deep dive into the format change, present its pros and cons, and show our latest benchmark results of the legacy vs. Trie index formats.
For benchmarking, we chose four different read workloads that would benefit from the Trie index format in different degrees. For all four, Trie indexes demonstrated better performance. They achieved 20% to 230% higher throughput and 31% to 63% lower latency compared to legacy indexes. The impact of Trie index on the write path is negligible.
Note that for use cases with either very low cache usage or 100% row-cache hit rate, the performance gain is expected to be lower. However, these use cases are unlikely in production.
Trie Index Usage in ScyllaDB
Before explaining the new format, we will cover the legacy index format and its challenges.
Legacy Three-Layer Lookup (me/md format)
Until ScyllaDB 2026.2 the default storage format was the SSTable version md and me.
Every SSTable lookup in the me/md format traverses three or four structures:
Summary.db(entirely in RAM)- Binary search in
Index.db - Sequential read in
Data.db
Both the partition index and the clustering-row index are stored in Index.db. The partition index is partially represented in memory by the sampled Summary.db, while the clustering-row index exists as a promoted index for large partitions.
┌──────── MEMORY ──────────────────────────────┐
│ │
│ Summary.db (entirely in RAM) │
│ ───────────────────────────── │
│ Sampled at ~1 byte per ~2000 bytes of │
│ Data.db │
│ │
│ "aardvark" → Index.db byte 0 │
│ "kangaroo" → Index.db byte 1,048,576 │
│ "platypus" → Index.db byte 2,097,152 │
│ "zebra" → Index.db byte 3,145,728 │
│ │
└──────────────────┬───────────────────────────┘
│
binary search → window in Index.db
│
▼
┌──────── DISK ────────────────────────────────┐
│ │
│ Index.db │
│ ───────── │
│ "kangaroo" → Data.db: 4,096,000 │
│ "koala" → Data.db: 4,097,280 │
│ "kookaburra" → Data.db: 4,098,560 │
│ "lemur" → Data.db: 4,099,840 ← found │
│ ... (up to ~800 entries per 1 MB scan) │
│ │
└──────────────────┬───────────────────────────┘
│
1 seek + sequential read
│
▼
┌──────── DISK ────────────────────────────────┐
│ Data.db │
│ <partition data> │
└──────────────────────────────────────────────┘For partitions containing enough clustering rows, a fourth structure is involved:
Index.db entry for a large partition
┌──────────────────────────────────────────┐
│ partition key → Data.db offset │
│ promoted_index (flat list of CK blocks) │
│ block 0: ck_start="aaa", ck_end="azz" │
│ block 1: ck_start="baa", ck_end="bzz" │
│ ... │
│ block N: ck_start=..., ck_end=... │
│ offsets[0..N] ← binary search here │
└──────────────────────────────────────────┘The New Trie Index Format
The Trie index (#25626) replaces Summary.db + Index.db with a single on-disk prefix tree. The storage format is compatible with Apache Cassandra’s BTI (Big Trie Index) format, implemented using ScyllaDB’s Seastar architecture.
Trie indexes are used for both partition indexes and clustering key indexes.
What Is a Trie?
A trie (prefix tree) stores keys character-by-character. Shared prefixes occupy a single path, eliminating redundancy:
Keys: "kangaroo", "koala", "kookaburra", "lemur", "lion"
[root]
/ \
'k' 'l'
| |
[k] [l]
/ \ / \
'a' 'o''e' 'i'
| | | |
'n' [o]'m' 'i'
| / \ | |
'g''a' 'o''u' 'o'
| | | | |
'a''l' 'k''r' 'n'
| | | *
'r''a' 'a' * = leaf node
| * | (payload: Data.db offset)
'o' 'b'
| |
'o' 'u'
* |
'r'
|
'r'
|
'a'
*
"k", "ko", "koo" — shared prefixes stored ONCENew SSTable Files
The ms/mt format replaces Summary.db and Index.db with two purpose-built files:
SSTable (ms format)
├── Data.db
│ unchanged — partition and row data,
│ same binary layout as me/md
│
├── Partitions.db ← NEW
│ Trie index:
│ partition key → Data.db offset
│ (small partitions)
│ partition key → Rows.db offset
│ (large partitions)
│
│ ┌── Page 0 (4,096 bytes) ───────┐
│ │ trie root node [1] │
│ │ + children (fan-out ≤ 256) │
│ │ + their children (packed) │
│ └───────────────────────────────┘
│ ┌── Page 1 (4,096 bytes) ───────┐
│ │ subtree for keys 'a'–'g' │
│ └───────────────────────────────┘
│ ...
│ ┌── Footer ─────────────────────┐
│ │ first_key (raw bytes) │
│ │ last_key (raw bytes) │
│ │ partition_count (uint64) │
│ │ trie_root_pos (uint64) │
│ └───────────────────────────────┘
│
├── Rows.db ← NEW
│ Per-partition clustering-key
│ tries, concatenated.
│ Each sub-trie:
│ clustering key → byte-offset
│ within partition
│ (replaces flat "promoted index"
│ in Index.db)
│
├── Filter.db bloom filter — unchanged
├── Statistics.db statistics — unchanged
└── Scylla.db ScyllaDB metadata — unchanged[1] Parent nodes are always written after their child nodes. Parents point to children, so child positions must be known before parents are written.
How a Partition Lookup Works
Query: SELECT * FROM orders
WHERE order_id = 'ORD-20240611-98765'
┌─────────────────────────────────────────┐
│ Step 1 — Key Translation │
│ │
│ 'ORD-20240611-98765' │
│ ↓ bti_key_translation.cc │
│ comparable byte sequence │
│ (lexicographic order matches │
│ CQL semantic order) │
└──────────────────┬──────────────────────┘
│
┌──────────────────▼──────────────────────┐
│ Step 2 — Trie Traversal │
│ in Partitions.db │
│ │
│ Read root page (4 KB) │
│ ← usually in OS page cache │
│ │
│ [root] ──'O'──> [node] (page 0) │
│ [node] ──'R'──> [node] (page 0) │
│ [node] ──'D'──> [node] (fetch page 1) │
│ [node] ──'-'──> [node] (page 1) │
│ ... │
│ [leaf] payload = Data.db or │
│ Rows.db pos 2,097,152 │
│ │
│ Typical: 2–6 page fetches. │
│ Top pages cached → often 0–1 disk I/Os │
└──────────────────┬──────────────────────┘
│
┌──────────────────▼──────────────────────┐
│ Step 3 — Read Data.db │
│ Seek to offset 2,097,152 │
│ → read partition header │
│ For large partitions: read Rows.db │
└──────────────────┬──────────────────────┘
│ (range/clustering queries only)
┌──────────────────▼──────────────────────┐
│ Step 4 — Read Data.db at position │
│ returned from index │
└─────────────────────────────────────────┘Page Layout: Packing Parent and Children Together
The most critical write-time optimization is ensuring that a node and its children land on the same 4 KB page. This means an entire trie neighborhood is readable in a single I/O, even on the first (cold) access.
┌──────── 4,096-byte page ────────────────┐
│ │
│ [A] ──'p'──> [B] ──'p'──> [C] │
│ │ │ │
│ └──'r'──> [D] ├──'l'──>[E]* │
│ │ │
│ └──'y'──>[F]* │
│ │
│ (* = leaf node with payload) │
│ (padding bytes to align next subtree │
│ to page boundary) │
└─────────────────────────────────────────┘
trie_writer algorithm (trie_writer.hh):
1. Maintain rightmost path root → current
node (_stack)
2. On each new key: branch off rightmost
path, add new nodes
3. Accumulate nodes until a finished
subtree exceeds a page
4. Flush child subtrees with padding so
each subtree fits within one page
ScyllaDB vs. Cassandra reference impl:
Cassandra: one character per node
ScyllaDB: characters grouped into
"chains" (up to 300 bytes)
→ dramatically faster writes for long
keys, same read-side page structureOld vs. New: Side-by-Side Summary
| Legacy me/md | Trie ms/mt | |
|---|---|---|
| On-disk files | Summary.db + Index.db |
Partitions.db + Rows.db |
| In-memory component | Summary (always loaded, never evicted) | None. Trie top-nodes live in OS page cache (evictable) |
| Index structure | Flat sorted list | Prefix tree |
| Partition lookup (cold cache) | Binary search in summary (RAM) + scan of Index.db window | Trie traversal byte-by-byte: O(key_length) page reads |
| Key storage | Full key per entry | Shared prefixes stored once |
| Clustering key lookup | Flat promoted-index list (binary search) | Sub-trie in Rows.db (trie traversal) |
Benchmark Results
The following table shows the key results, measured at client-side P99 ≤ 10 ms on a 3-node AWS production-class cluster. All tests were run on 3 × i8g.2xlarge instances, each on a different zone, with Replication Factor (RF) of 3.
For a full description of the test cases and setup, see the Appendix below.
| Test case | Legacy (me) Throughput | Legacy (me) P99 | Trie (ms) Throughput | Trie (ms) P99 | Throughput gain |
|---|---|---|---|---|---|
| Test 1: Typical (~20% row cache) | 130k ops/s | 5.1 ms | 170k ops/s | 1.9 ms | +31% |
| Test 2: Key / Value | 90k ops/s | 5.2 ms | 300k ops/s | 3.6 ms | +233% |
| Test 3: Large Partitions | 23k ops/s | 7.7 ms | 37k ops/s | 4.6 ms | +61% |
| Test 4: Long shared clustering key prefixes | 22k ops/s | 5.4 ms | 38k ops/s | 3.3 ms | +73% |
Discussion: Why Trie Indexes Improve Performance, and When to Use Them
ScyllaDB CTO Avi Kivity has mentioned three reasons why Trie indexes improve performance:
- Improved cacheability: the index is denser, so it is more likely to fit in cache, requiring no I/O for the index itself.
- Fewer I/O operations after cache miss: if the index is not in cache, fewer I/O operations are required to fetch it since the index is more compact and shallower. This is especially true for large partitions, often seen in materialized view workloads.
- CPU efficiency: less CPU is needed to process the index during reads.
A possible downside is that more CPU is needed to create the index during memtable flush and compaction. However, this is more than offset by the read-side advantages.
For proof of Avi’s first point, see the Disk Read panels from ScyllaDB Monitoring’s OS metric dashboard for legacy vs. Trie index format. Each step represents increasing workload throughput.
For the first load, using the same throughput, Disk Reads for legacy indexes is ~240 MB/s; for Trie indexes, it is ~33 MB/s. The Trie index consumes only ~1/7th of the storage bandwidth.

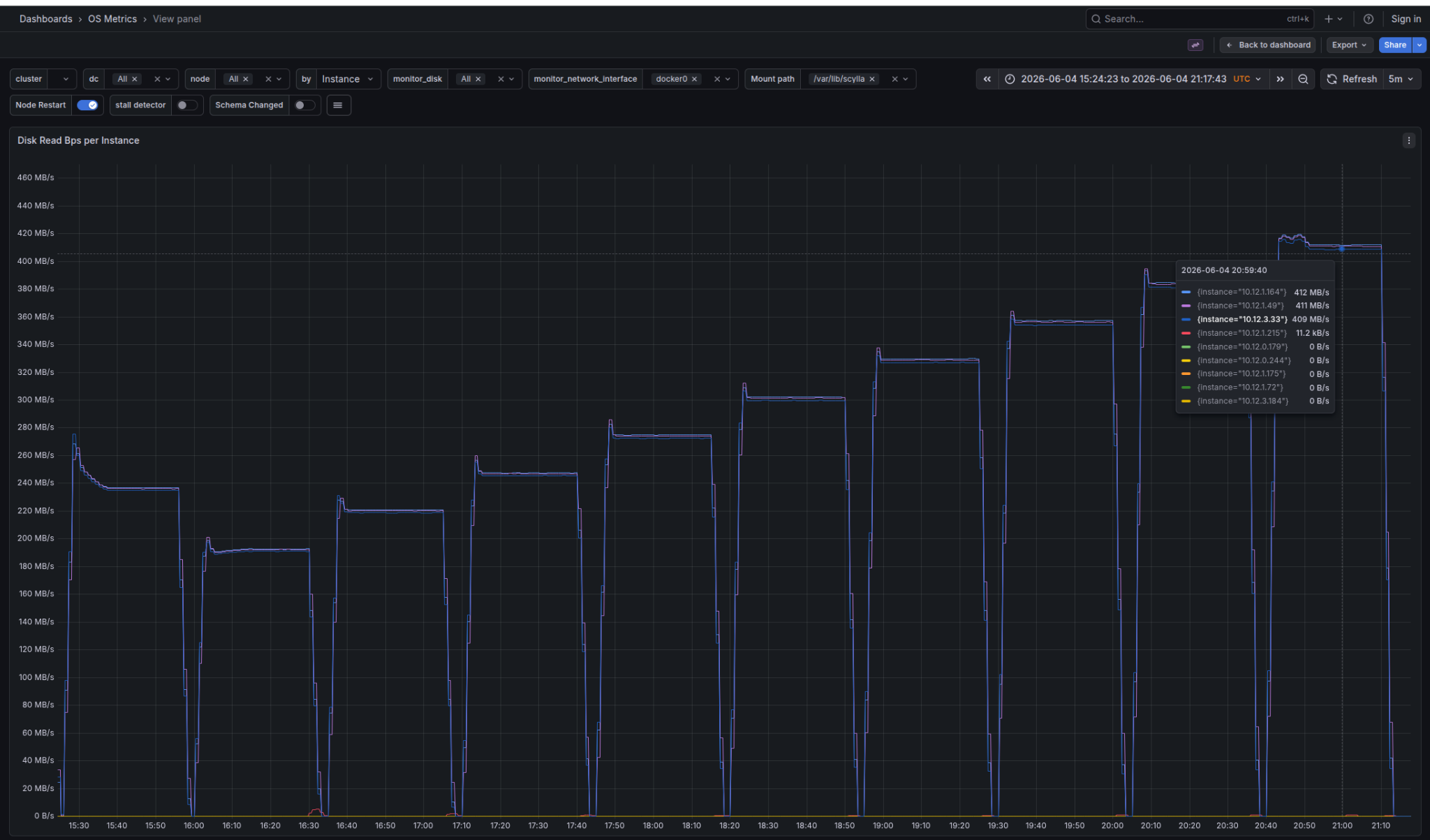
Note that the Trie index has a negligible effect for 100% cache hit rate or 0% cache hit rate workloads. For both, the in-memory index representation is irrelevant. Write workload is also only marginally affected by the index format change.
Summary
ScyllaDB 2026.2 has adopted a Trie-based index format as its new default, replacing the legacy index structure to significantly enhance read path performance. By transitioning from separate summary and index files to a prefix tree, this design optimizes cache efficiency, reduces disk I/O, and reduces memory overhead. Benchmarks indicate that this architectural change delivers throughput improvements ranging up to 3x across various workloads, offering a more scalable and efficient solution than the legacy index format.
As always, actual results depend on your workload. To evaluate the gain of Trie index, we highly recommend testing it yourself with the latest ScyllaDB releases.
Appendix: The Full Test Setup
All tests compare me (legacy) vs. ms (trie) format on identical code, hardware, and dataset. Metric: maximum throughput (ops/s) at which client-side P99 latency stays below 10 ms.
Hardware and Infrastructure
Component Specification
──────────────────────────────────────────
Cloud provider AWS us-east-1
DB nodes i8g.2xlarge × 3, RF=3,
3 racks
Loaders (normal) c7i.4xlarge × 4
(Tests 1, 3)
Loaders (large) c7i.4xlarge × 3
(Tests 2, 4)
Row cache ~20% of dataset
Kernel 7.0.0-1006-aws
SSTable formats me (legacy) vs ms (trie)
──────────────────────────────────────────Software Versions
| Component | Version |
|---|---|
| ScyllaDB | 2026.3.0~dev |
| cassandra-stress | 3.20.6 |
| latte | 0.48.0-scylladb |
| Java driver | 3.11.5.14 |
| Rust driver (latte) | 1.6.0 |
| Python driver | 3.29.10 |
Test 1: Typical (~20% Row Cache)
Description: Standard cassandra-stress read workload with ~20% row cache. Closest analogue to a general production workload.
Schema and dataset:
CREATE TABLE keyspace1.standard1 (
key blob PRIMARY KEY,
C0 blob, C1 blob, C2 blob, C3 blob, C4 blob
);
-- 5 columns × 256 bytes ≈ 1,280 bytes/row
-- 650,000,004 rows
-- (written with CL=ALL across 4 loaders)Workload parameters:
Stress tool: cassandra-stress
Consistency: QUORUM
Access: Sequential on 2 loaders,
Gaussian on 2 loaders
Threads: 620 total
Throttle: 70k–250k ops/s in 10k steps,
30 min per step
SCT config: test-cases/trie/
perf-steps-neutral.yamlBuilds:
| Format | ScyllaDB revision | Build date | Build ID |
|---|---|---|---|
| me | 1fdd379bf99c |
2026-06-03 | 8c9256ba |
| ms | 1fdd379bf99c |
2026-06-03 | 8c9256ba |
Results:
| Legacy me | Trie ms | |
|---|---|---|
| Max Throughput | 130k ops/s | 170k ops/s |
| P99 Latency | 6.28 ms | 3.19 ms |
| Throughput gain | — | +31% |
| Latency at saturation | 6.28 ms | 3.19 ms (−49%) |
Note: Even at the same 130k ops/s, Trie P99 is 3.19 ms vs 6.28 ms — half the latency, with substantial headroom before the 10ms ceiling.
Test 2: Key / Value
Description: Deliberately favorable for the trie. Schema has only a partition key with no clustering columns. Tiny rows (~8 bytes payload) mean extremely high partition density. The trie’s prefix compression yields much higher effective cache density than the legacy flat list.
Schema and dataset:
CREATE TABLE trie_test.fav (
key blob PRIMARY KEY,
col blob -- FIXED(1024) in stress profile
);
-- ~8 bytes/row effective (key-only access)
-- 650,000,004 rowsWorkload parameters:
Stress tool: cassandra-stress
(custom profile)
Throttle: me: 70k–100k ops/s
ms: 230k–350k ops/s
(non-overlapping by design —
me saturates far below ms)
Step duration: 30 minutes
SCT config: test-cases/trie/
perf-steps-fav.yamlBuilds:
| Format | ScyllaDB revision | Build date | Build ID |
|---|---|---|---|
| me | 1fdd379bf99c |
2026-06-03 | 8c9256ba |
| ms | d8de7268e7f4 |
2026-06-05 | b6e8613d |
Results:
| Legacy me | Trie ms | |
|---|---|---|
| Max Throughput | 90k ops/s | >280k ops/s |
| P99 Latency | 6.12 ms | 4.50 ms |
| Throughput gain | — | >+211% |
The trie can serve 3× the request rate at lower latency because the same OS page cache budget covers 3× more trie top-nodes than the equivalent Index.db window.
Test 3: Large Partitions
Description: Each partition holds 460,000 rows with a large clustering key. With only ~100 total partitions, per-shard throughput (not index access) is the bottleneck. Tests the trie row index (Rows.db) rather than the partition index.
Schema and dataset:
CREATE TABLE trie_test.large (
pk blob,
ck blob,
value blob,
PRIMARY KEY (pk, ck)
);
-- 46M total rows
-- 460,000 rows per partition, ~100 partitions
-- Accessed via: latte large-partition.rnWorkload parameters:
Stress tool: latte 0.48.0-scylladb
(large-partition.rn)
Threads: 1
Throttle: 10k–70k ops/s in 10k steps,
30 min per step
SCT config: test-cases/trie/
perf-steps-large.yaml
Loaders: 3 × c7i.4xlargeBuilds:
| Format | ScyllaDB revision | Build date | Build ID |
|---|---|---|---|
| me | e5b4f43ec1c8 |
2026-06-02 | c32c9fc9 |
| ms | e5b4f43ec1c8 |
2026-06-02 | c32c9fc9 |
Results:
| Legacy me | Trie ms | |
|---|---|---|
| Max Throughput | ~19,998 ops/s | ~29,998 ops/s |
| P99 Latency | 2.87 ms | 3.80 ms |
| Saturation point | ~24k (at 30k target) | ~37k (at 40k target) |
| Throughput gain | — | +50% |
Test 4: Long Shared Clustering Key Prefixes
Description: The worst case for the trie. Clustering keys are 2048 bytes long with a long common prefix — only the final bytes differ. This maximizes trie depth, erodes prefix sharing, and inflates node fan-out near the top. Same schema as Large Partitions with 10× fewer rows per partition (46,000 vs 460,000).
Schema and dataset:
CREATE TABLE trie_test.unfav (
pk blob, -- 4 bytes
ck blob, -- 2048 bytes, long shared prefix
value blob, -- 1024 bytes
PRIMARY KEY (pk, ck)
);
-- 46M total rows
-- 46,000 rows per partition, ~1,000 partitions
-- Accessed via: latte unfavorable.rnWorkload parameters:
Stress tool: latte 0.48.0-scylladb
(unfavorable.rn)
Threads: 1
Throttle: 10k–80k ops/s in 10k steps,
30 min per step
SCT config: test-cases/trie/
perf-steps-unfav.yaml
Loaders: 3 × c7i.4xlargeBuilds:
| Format | ScyllaDB revision | Build date | Build ID |
|---|---|---|---|
| me | a0e160db8a7d |
2026-06-04 | f1e189b2 |
| ms | a0e160db8a7d |
2026-06-04 | f1e189b2 |


