ScyllaDB successfully mitigated performance-degrading connection storms by optimizing caching, throttling, and password hashing to achieve a 1000x reduction in tail latency
The story begins with a customer-visible problem: node restarts spiked P99 latency to 5 seconds for a full minute, while typical latency for the cluster was only 4 milliseconds. The cause was a flood of new connections. For ScyllaDB to achieve ultra-low latency, new client connections go directly to each CPU core. For instance, on clusters with 9 nodes and 64 cores (vCPUs), that’s 500+ connections per client. The number of client processes can also range from a few processes to tens of thousands of processes (in large k8s systems). Then, the effective number of connections can range from tens of thousands to millions. This isn’t a problem in a steady state, but – during topology operations or a customer’s application restart – it could trigger massive surges of new connections.
While ScyllaDB can handle millions of operations per second without any problem, we couldn’t do the same with connections. Establishing a new connection requires additional work and triggers code paths that can become problematic at scale, as we’ll discuss later.
Clients could create new connections gradually; this way, no excessive strain would be put on the database. But ScyllaDB needs to handle even cases where clients are not behaving well. Worse, the problem can quickly snowball: a surge bloats the task queues, connections miss their timeouts, and clients retry… which means even more connections and additional pressure on the system. We don’t want to contribute to a cascading failure when graceful startup sequences aren’t implemented or fail for any reason. Moreover, we try to be as fast as possible; deployment changes should not be delayed by the database warming up when it’s not absolutely necessary.
For all the above reasons, we decided to improve efficiency around connection creation. This led us to investigate and optimize the code on multiple fronts.
From TCP SYN to Query-Ready
The flow of establishing a new connection looks like this:
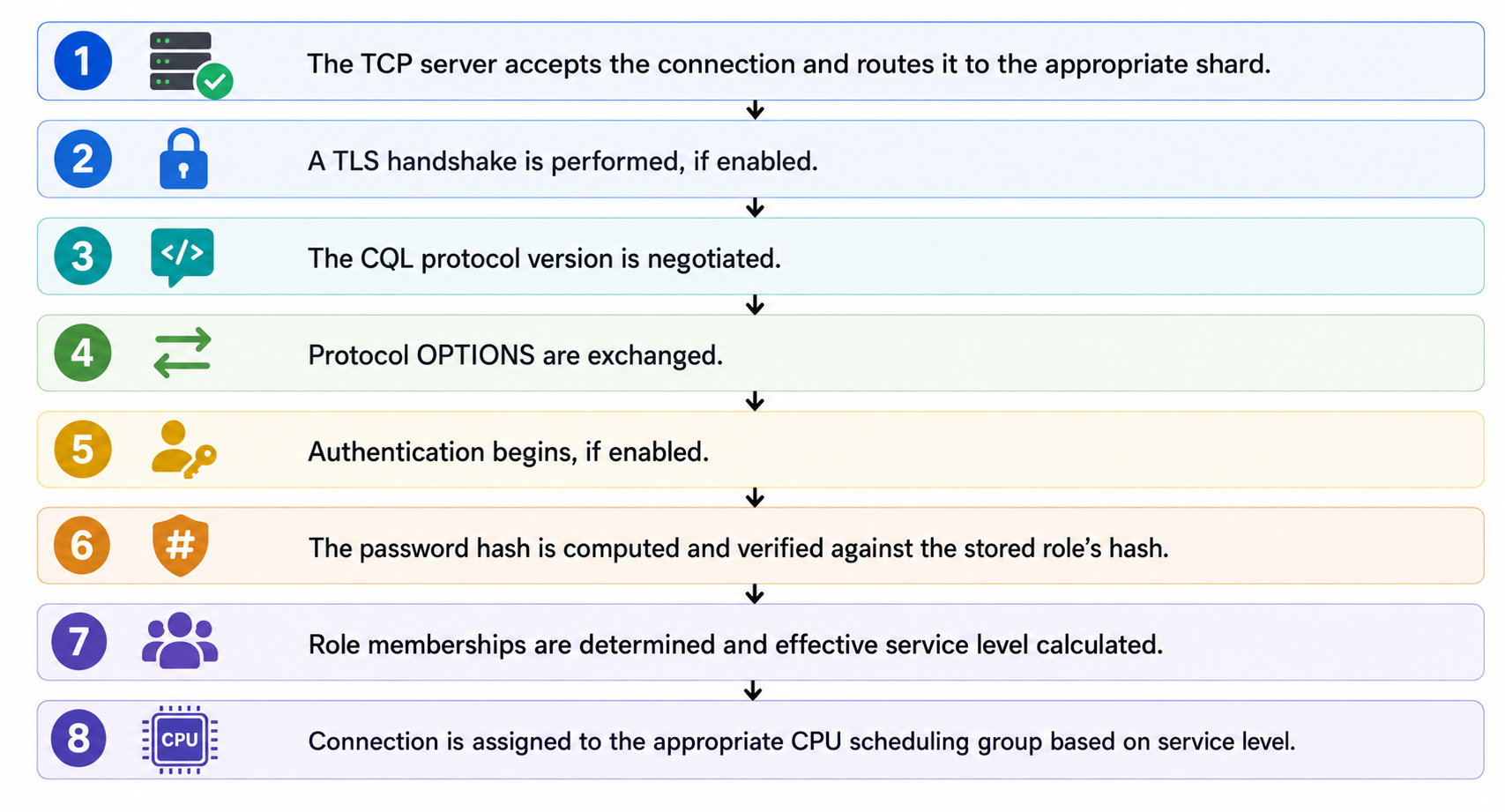
We introduced improvements at nearly every stage of this process. Each tackles connection load differently:
- Throttling limits how many connections work at once
- Caching removes redundant work
- Hashing makes unavoidable CPU work yield
- A dedicated service level isolates background traffic
In the next sections, we’ll walk through this pipeline step by step.
Connection throttling
To fully utilize the CPU, ScyllaDB divides work into tasks, and the CPU scheduler switches between them. Tasks live in queues, from which they are picked for execution. A much more in-depth dive into our CPU scheduler can be found in this P99 CONF talk by our co-founder/CTO Avi Kivity.
When a new connection request arrives, we create a task to handle it. The scheduler gives it some CPU time, then — after it depletes or we need to wait for some I/O – we switch to another task. When many new connections are attempted, units of CPU are sent to the scheduler’s task queue. The scheduler tries to divide the work across time slices, but its task queue is bloated. We strive to fairly progress all connections at once. However, in the end, most of them are not fully established within the timeout. That leads to client retries and even more overload.
As a first line of defense, we added a connection throttling mechanism. We already had request throttling and shedding, but nothing that controlled connection admission. The main design objective was that it should work automatically; we didn’t want the user to benchmark their system and put some rigid number in the configuration.
We split new connection work into two states: “CPU” state and “networking” state. A connection is marked as being in a networking state while sending or receiving packets from the driver. And since our bottleneck is CPU, we look at how many connections are in a CPU state when we’re accepting new connections, and we allow only a small fixed number (the default is 8). Although this limit can be configured via the uninitialized_connections_semaphore_cpu_concurrency option in scylla.yaml, we don’t expect that users will need to adjust it.
In practice, there may be more connections in “CPU” state than this fixed number (because once a connection is admitted, it can switch the states without blocking). Once we spend some CPU on handling the connection, it’s more important to continue with it than to switch focus to some newer connection. This ensures that the system can make progress and we don’t hit timeouts.
When new connections are waiting over 1 minute to be admitted, we start shedding them. In the end, there is a certain number of new connections we can handle.
The result is that the system keeps making progress under a storm instead of thrashing across thousands of half-finished handshakes and timing them all out.
A unified permissions cache
We noticed that, in some cases, the cluster generated ~3k ops/s of internal reads just to refresh the permissions cache. Moreover, role information – which is only needed during connection setup (unlike permissions) – was not cached at all.
We started with low-hanging fruits. The roles table was queried redundantly because permissions form a tree of inherited grants; to populate a single cache entry, we issued several selects on the roles table. By improving the way inherited roles were gathered, we decreased the load for the roles table by 50%.
But there shouldn’t be any load at all; roles and permissions tables are usually very small compared to users’ tables. There is no need to involve the full database query machinery.
We already had a cache for permissions, but it had several drawbacks. The primary one was that it was based on a periodic refresh of entries. This was causing the internal load mentioned above, together with some unpredictable latency. And our cache didn’t cover per-connection authentication, since it didn’t store the roles table.
We decided to create a unified cache. A typical problem to tackle with any cache is cache coherence. Luckily, we already solved this when we changed the replication of auth tables to Raft. Writes to those tables are linearized by the Raft consensus protocol, and they are applied in the same order on all nodes. Tapping into this mechanism allowed us to have a coherent, write-updated cache. It also eliminated the need for periodic refresh.
After the change, the internal load spikes briefly during loading and then disappears completely.

Making hashing yield
For one of our customers, we noticed that node restarts were causing elevated latency for a short period of time.

The P95 latency spiked to 5 seconds for around a minute, while the typical latency for this cluster was only 4 milliseconds. We take latency seriously at ScyllaDB, so we had to fix this.
After investigation, we realized that our next improvement target has to be password hashing. The CQL protocol has this odd property that, during connection authentication, passwords are sent and hashed on the server side. We can’t cache hashing because we don’t want to store raw passwords in memory for security reasons.
The problem wasn’t CPU usage by itself, but rather how it was allocated. ScyllaDB uses futures-based execution with cooperative scheduling. This allows us to write asynchronous code easily. Typically, yield points are triggered by an IO operation. But when CPU-intensive code (such as hashing) runs, we need to manually insert yield points into the code. Otherwise, the scheduler can’t fairly switch CPU execution to other tasks, hence elevated request latency. Unfortunately, we can’t do that easily: we use libcrypt, an external library.
Maintaining our own hashing function in such a security-sensitive context is not something we were keen on doing. Initially, we tried to use something we call an alien thread. It’s a standard OS thread where execution is subject to preemptive scheduling. We decided to have a single thread per instance. Otherwise, we’d proportionally decrease OS time for our own internal scheduler, defeating its purpose. But the cure was worse than the disease. In our tests with just 10 CPUs, we reduced connection-per-shard rates 6X. And on larger nodes, the decline would be even bigger.
Our second solution was to fork hashing code from the musl library and then add yield points. This is a middle ground between writing our own hashing code and an ineffective attempt to use library code without modifications.
Connections per second per shard were measured as follows:
| Configuration | Rate |
|---|---|
| Initially | 244 conns/s |
| Alien thread | 41 conns/s |
| Modified musl | 198 conns/s |
We sacrificed around 20% of the hashing speed, since musl is less efficient than libcrypt. It impacted only our connection rate, not our request throughput. That’s an easy trade to kill a multi-second latency cliff.
Isolating startup traffic
ScyllaDB has a workload prioritization feature where multiple workloads can be isolated so they don’t affect one another’s performance. More information about it can be found here in the documentation. But, as described in the From TCP SYN to Query-Ready section, service level assignment happens quite late during connection establishment. It needs an authenticated role to find an appropriate service level. Any work done before that runs with the main scheduling group and can compete with user workloads.
Moreover, each driver instance keeps a control connection for tracking schema changes, topology, heartbeats, etc. Historically, such work was done in the main scheduling group. With the default setup, it could affect user workloads. That’s why we introduced a new driver service level that has reduced the number of shares. This service level is automatically selected at connection startup and then switched to the appropriate level once it is known.
Our synthetic tests showed that, during heavy connection storms, this change alone reduced the maximum latency of CQL requests from 225 ms to 41 ms.
Benchmarking
We measured the performance gains at two levels: targeted micro-benchmarks that stress individual parts of the implementation, and cluster-wide load tests for the final result.
Here is the impact of just the cache optimizations:
| Metric | BEFORE new cache | AFTER new cache | Delta |
|---|---|---|---|
| Instructions / Conn | 4,226,658 | 3,861,944 | -8.63% |
| Allocs / Conn | ~407.0 | ~182.5 | -55.16% |
| Tasks / Conn | ~139.3 | ~82.0 | -41.13% |
This benchmark runs a single ScyllaDB node and then floods it with connections. For each connection, it performs a CQL startup sequence (including authentication), and then closes the connection.
We see that stress caused by connection storms to the memory subsystem is reduced by half, and stress to task queues was reduced by almost half.
The following charts show the final result of all the improvements to mitigate connection storm impact on the cluster:
Before After

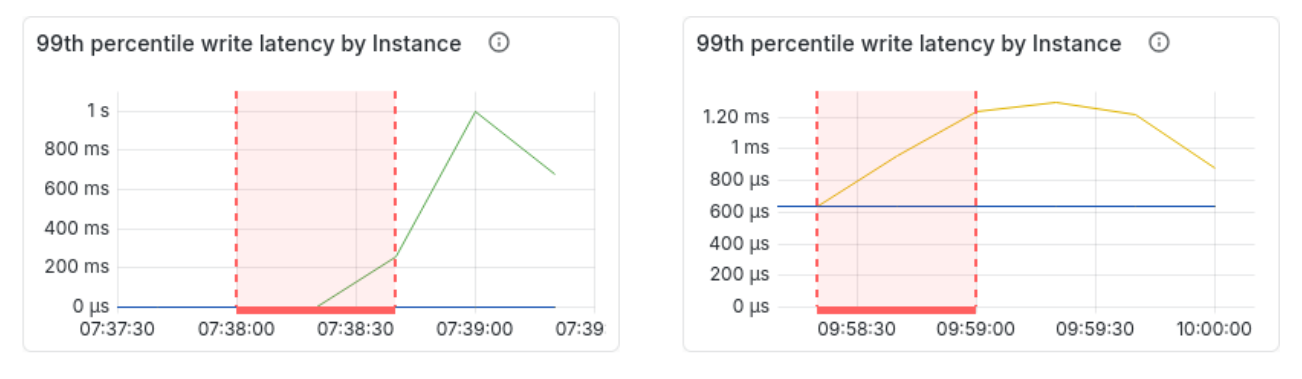
Here, we evaluated ScyllaDB’s ability to maintain availability and performance during a node restart under sustained, production-like load. The benchmark was conducted on a nine-node cluster of i4i.2xlarge instances deployed in a single availability zone and distributed across three racks, with a replication factor of three. To simulate a demanding client workload, 20 c7i.2xlarge loader instances generated approximately 380,000 concurrent connections—around 6,000 per shard. The load was 74,000 read operations per second and 12,000 write operations per second. Client request timeout was set to 10 seconds, connection timeout to 11 seconds, and control connection timeout to 6 seconds.
Prior to the benchmark, the cluster was populated with approximately 65 GB of data. The workload was then executed continuously for 10 minutes, after which one randomly selected node was restarted while the load remained active, allowing us to observe the cluster’s behavior and recovery characteristics during a node restart.
The red lines denote the time the node was restarting; since all the driver instances need to reconnect, this is a common case which causes connection storms. Latency is now 1000x lower than it was before, making the impact of new connections barely visible to the cluster.
Add it to your ScyllaDB deployment
Our goal is simple: you should be able to focus on your application logic, not on babysitting database connection parameters. With these changes, you should be able to deploy and restart with confidence, knowing that your cluster is designed to handle traffic spikes gracefully.
All these improvements are in the new 2026.2 release; we strongly encourage you to upgrade and share how it’s working in your environment.