How ScyllaDB is using per-tablet Raft groups to bring strong consistency to data, without sacrificing the parallelism that makes it fast
Distributed systems do not give us simple guarantees for free
Distributed databases live in a world where failure is normal. Nodes fail. Networks could have partitions. Clocks might be different in each area that you’re working in. Messages can be delayed or never arrive because of the network itself. A request that looks simple from the application side may cross replicas, shards, data centers, coordinators, and recovery paths before the database can safely answer it.
Consistency is one of the most important contracts between the database and the application…and it’s hard. When the database says a write succeeded, what exactly does that mean? When a second client reads the same key, what state should it see? When two updates race, who wins, and can the application reason about the result?
For many workloads, eventual consistency is the right approach. It gives a distributed database room to stay highly available and fast, even when part of the system is under stress. For now, these workloads are where ScyllaDB shines.
But for other workloads, “eventually correct” creates too much ambiguity. Those workloads need a stronger contract.
Eventual consistency was the right foundation for ScyllaDB
ScyllaDB started as a high-performance, Cassandra-compatible, eventually consistent database. That model is powerful: the system is leaderless, work is distributed across shards, and applications choose consistency levels such as ONE, QUORUM, or ALL (depending on their needs).
In this model, a client sends a write to a coordinator, the coordinator forwards it to replicas, and the operation is acknowledged according to the selected consistency level. Reads follow a similar pattern: replicas respond, and the coordinator waits for enough responses to satisfy the requested consistency level.

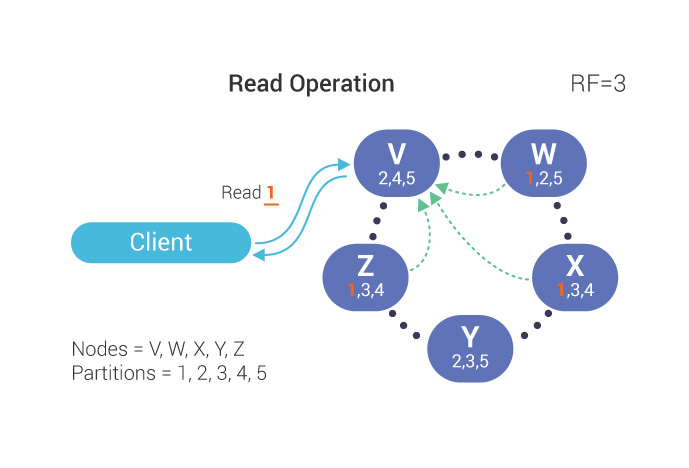
Figure 1: Write and read patterns
This design gives applications a flexible tradeoff between latency, availability, and consistency. It remains valuable, especially for high-scale workloads that prioritize availability and throughput.
But some parts of a database should not be “eventual”
Eventual consistency becomes harder when the data being changed is not naturally commutative, when different observers must agree on one order of events, or when a wrong answer is expensive. Metadata is the clearest example. Schema, topology, tablet placement, and cluster state describe the database’s internal operations. If nodes disagree about this information, the system becomes harder to operate safely.
The same pattern appears in application data. Counters, account balances, inventory reservations, entitlement checks, idempotency records, and conditional updates all become simpler when the database can provide a clear, strongly ordered answer. Without that guarantee, application developers often compensate by adding retries, custom conflict resolution, reconciliation jobs, or application-side locks.
Figure 2: Gossip-based topology spreads membership information without a single global source of truth, which is powerful for availability but eventually consistent by design.
For example, “last-write-wins” sounds simple: keep the newest update.
But if two clients update the same value at the same time, one update can disappear.
Initial value: {}
Client 1 writes: {A}
Client 2 writes: {B}
Final value: {B}Both writes may have been accepted, but only one survives. The problem is that last-write-wins avoids coordination, but it does not merge intent. For mutable data, this can mean lost updates.
To learn more: https://aphyr.com/posts/294-jepsen-cassandra
Strong consistency gives the system one accepted order
An alternative approach is strong consistency. Instead of allowing independent updates to happen concurrently and converge later, the system establishes one accepted order for operations. In practical terms, this means that once an operation is committed, later operations observe that committed state according to the consistency model.
This provides correctness as well as simplicity. Developers can reason about the database as if there is one clear sequence of operations. Operators can reason about topology and schema changes as deterministic state transitions. And the database can remove entire classes of ambiguity because it no longer needs to guess which version of the world is the right one. Strong consistency is an all-around simpler programming model for the parts of the application where correctness, ordering, and predictability matter more than the lowest possible write latency.
Why Raft is the right building block
Raft provides the foundation for this stronger consistency model.
At a high level, a Raft group chooses one node to be the leader. The leader receives the request, records it, and makes sure most of the group has the same record. Only then does the group treat the request as accepted.
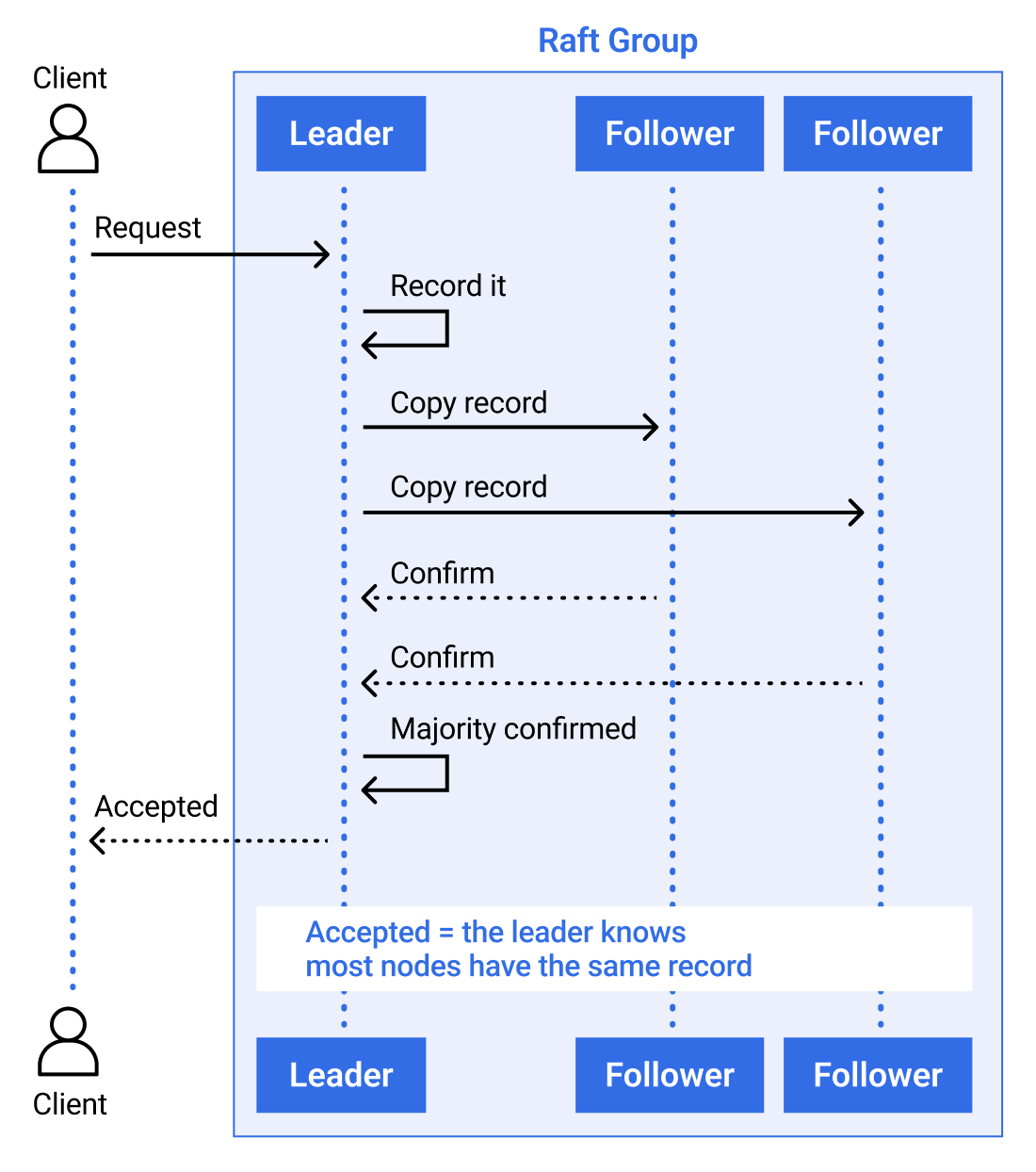
Figure 3: Raft request access by majority process
Because all nodes follow the same ordered list of accepted requests, they all reach the same result in a clear and predictable way.
This model is especially useful in a distributed database because it gives the system a clear answer to a hard question:
Who is allowed to decide what happens next?
In Raft, the leader proposes the order and the majority confirms it.
ScyllaDB adopted Raft because some database operations are too important to be left to eventually converging metadata. Schema changes, topology changes, and strongly consistent data operations all need a clear, agreed-upon order. Without that, two nodes may observe changes in different orders, or the system may need complex recovery logic to repair disagreement after the fact.

Figure 4: Raft turns a distributed decision into an ordered log: leader election, append, replicate to a majority, commit, and apply.
This is also important for elasticity. ScyllaDB’s tablet architecture is designed for flexible data distribution across the cluster, and Raft-managed topology allows operations such as adding nodes and moving data to be coordinated safely. ScyllaDB uses tablets, together with consistent topology updates, as a foundation for faster and more flexible scaling.
In other words, ScyllaDB adopted Raft not just because Raft is a well-known consensus algorithm, but because it gives the database a reliable coordination layer. It replaces “every node eventually figures it out” with “the group agrees on the order first, then applies the result.”
That is the foundation needed for strong consistency; there’s just one:
- Agreed order.
- Committed history.
- Deterministic path from request to replicated state.
At ScyllaDB, the first step in adopting Raft was to use it for topology and metadata changes. This gave those critical operations strong consistency guarantees while also reducing complexity across the system.
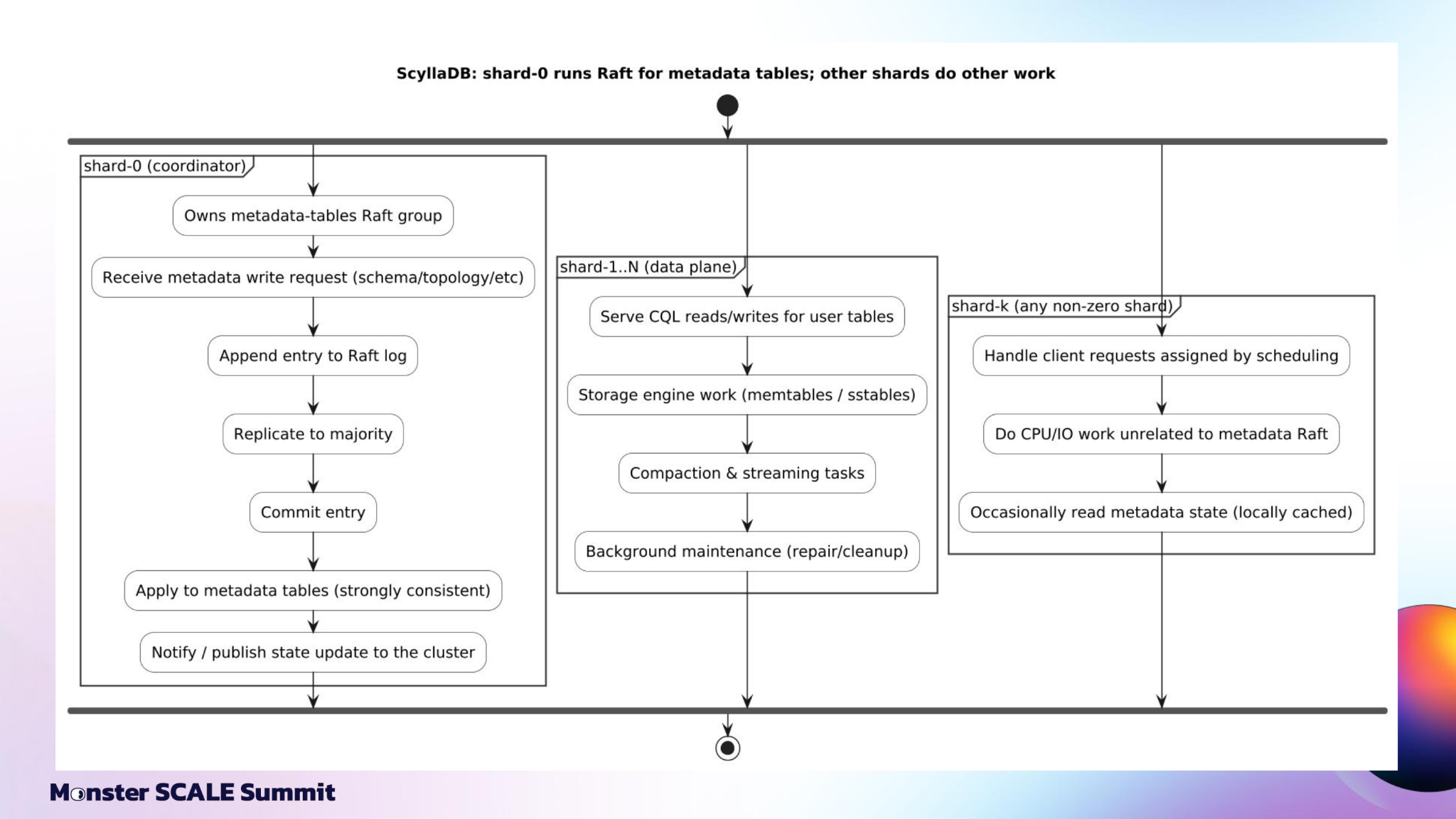
Figure 5: In ScyllaDB, shard 0 runs Raft for metadata tables while the other shards continue doing user-data and storage-engine work.
The next milestone for ScyllaDB: strongly consistent tables
Our next step is bringing the same idea to user data through strongly consistent tables. A strongly consistent table is built on top of the Raft log. A write is routed to the Raft leader for the relevant tablet group, appended to that group’s log, replicated to a majority, committed, and applied to the storage engine.
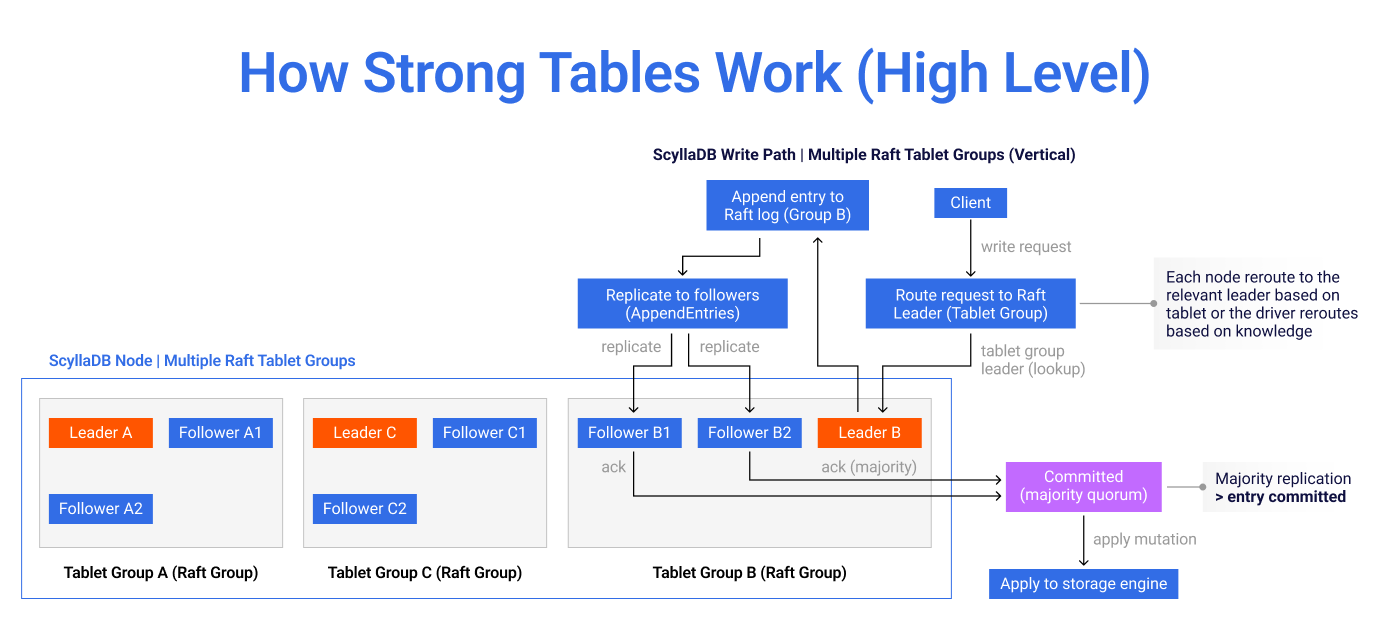
Figure 6: High-level strongly consistent write path: route to the tablet group leader, append to the Raft log, replicate to a majority, commit, and apply to storage.
This is a major shift in how users can model correctness in ScyllaDB. Instead of treating strong guarantees as a special case workaround, users can choose a consistency model at the data-modeling level. Tables that need the classic high throughput eventual consistency behavior can keep it. Tables that need stronger ordering can use the strong path.
It’s important to note: ScyllaDB is not replacing eventual consistency. We are offering multi-consistency. Our users will be able to choose the right consistency model for each workload. And we will deliver strong performance in both cases.
Why a Raft Group for each tablet?
In ScyllaDB, we already use Raft for important system-level coordination. For example, Raft is used to safely sequence topology and schema metadata changes. That makes cluster operations consistent and reliable.
So a natural question is:
If we already have Group 0, why not use it as the single synchronization point for all strongly consistent data operations?
At first glance, that sounds simpler. We already have one Raft group in the system. We could use it as the “master sync point” for every read, write, and data-related operation. But, unfortunately, it’s not that simple.
ScyllaDB clusters can contain many tablets. Tablets are the basic units of data distribution: each tablet owns a portion of a table’s data and can be independently managed and moved across the cluster.
To understand the issue, imagine a busy system with many tablets, heavy reads, heavy writes, topology activity, background work, maintenance operations, and user traffic all happening at the same time. If all of these operations had to pass through a single Raft group, that group would become a global synchronization bottleneck. Because Raft is a consensus protocol, operations must be ordered and committed consistently. (That’s what gives us correctness). But if one global group is responsible for ordering everything, then unrelated operations are forced into the same queue. A write to one tablet may have to wait behind work for another tablet. A read or write on one part of the dataset may be delayed by background activity somewhere else in the cluster. All this hurts both latency and throughput.
A better option is to “divide and conquer.”
Since the tablet is already the natural unit of data ownership, we can also make it the natural unit of synchronization. Instead of forcing all strongly consistent operations through one global Raft group, each tablet gets its own Raft group.
This means each tablet handles its own coordination, replication, and bookkeeping. Operations on one tablet do not need to block unrelated operations on another tablet. The system can make progress in parallel, across many independent Raft groups, instead of serializing everything through a single global queue.
The result is a much more scalable architecture with:
- Lower contention: Each Raft group handles only the operations for its own tablet.
- Better parallelism: Many tablets can process strongly consistent operations at the same time.
- Improved throughput: The system is no longer limited by one global synchronization point.
- Lower latency: Unrelated operations do not wait behind each other as often.
- Better user experience: Strong consistency becomes practical without turning the entire database into a single serialized pipeline.
This is the same basic reason ScyllaDB’s tablet architecture exists in the first place: splitting data into smaller independent units allows the system to scale, rebalance, and operate in parallel. Tablets were designed to support faster, more flexible scaling by separating data ownership from fixed server ownership.
A single global Raft group is nice because it is easier to reason about. However, ScyllaDB is built for high-throughput, low-latency workloads. A single global queue for all of them would immediately become the bottleneck. By assigning a Raft group to each tablet, we keep the correctness properties of Raft while preserving the parallelism that makes ScyllaDB fast. Each tablet becomes an independent unit of consistency. The cluster as a whole can continue to behave like a distributed, parallel database rather than a single synchronized queue.
In short:
Group 0 is great for global metadata.
Per-tablet Raft groups are what make strong consistency scalable for user data.

Raft leaders and followers: one voice for the group
Raft is a consensus protocol designed around a simple idea: instead of allowing every replica to independently decide what should happen next, the group elects one replica to act as the leader. The other replicas become followers. This leader-based model makes the system easier to reason about because all changes flow through a single authority for that Raft group. The original Raft paper describes this as one of Raft’s main design choices: decomposing consensus into understandable pieces, especially leader election and log replication.
In normal operation, the leader is responsible for accepting new operations, appending them to its log, and replicating those log entries to the followers. A follower does not independently decide the order of operations. Instead, it follows the leader’s log and acknowledges replicated entries. Once an entry is safely replicated to a majority of the group, it can be considered committed and applied to the replicated state machine. This is the core mechanism that allows multiple machines to behave as if they agreed on one ordered history of changes.
The important point is that the leader is not “more correct” than the followers. It is simply the replica currently elected to coordinate the group. Followers still store the replicated state, validate the leader’s messages according to the Raft rules, and participate in making progress by acknowledging replicated entries. The leader can only commit entries when it has agreement from a quorum. This is why Raft depends on a majority of replicas being available; without a quorum, the group cannot safely make new decisions. ScyllaDB’s Raft documentation also highlights this quorum requirement for Raft-managed operations.
A useful way to think about it is this:
The leader proposes the order. The followers confirm and persist that order. The majority makes it durable.
Raft leaders also send periodic heartbeat messages to followers. These heartbeats tell the followers that the leader is still alive and still responsible for the current term. As long as followers keep receiving valid communication from the leader, they remain followers. If a follower stops hearing from the leader for long enough, it assumes the leader may have failed and starts an election by becoming a candidate. If that candidate receives votes from a majority, it becomes the new leader. This election mechanism allows the group to recover automatically when the current leader crashes or becomes unreachable.
This distinction between leader and follower is especially important in distributed databases. A database cluster is not running on one machine. It is running across many machines, and those machines can fail, restart, disconnect, or see events in different orders. Without a clear coordination model, two replicas could make conflicting decisions at the same time. Raft avoids that by ensuring that, for a given term and Raft group, there is one leader responsible for sequencing new changes.
In ScyllaDB, Raft has already been used to make important metadata operations safer and more consistent, including schema and topology changes. ScyllaDB’s work on Raft-managed topology means topology operations are internally sequenced consistently, rather than relying on each node to independently converge on the same result. ScyllaDB also has one place that coordinates topology changes together with the Raft leader. If that leader goes down, another leader can take over and continue from the same shared information, instead of guessing or starting from a different view.
For strongly consistent data, the same basic idea applies: the leader of the relevant Raft group is the place where the ordered history of that group is created. A write is not just “sent somewhere and eventually copied.” It is placed into a replicated log, agreed on by a majority, and then applied in the same order by the replicas. Followers are not passive backups in the weak sense; they are active participants in preserving the agreed history.
This model gives us a clean mental picture:
Without Raft: replicas may need to reconcile different views after the fact.
With Raft: replicas agree on the order first, then apply the result.
That is the key difference. Raft does not remove the complexity of distributed systems; failures, latency, partitions, and recovery still exist. But it gives the system a disciplined way to handle that complexity. The leader gives each Raft group a single coordination point, the followers provide durable replicated state, and the quorum rule ensures that progress is made only when enough replicas agree.
In other words, Raft leader/follower replication is not about creating one “special” node forever. It is about creating a temporary, elected coordinator that gives the group one consistent voice. If that voice disappears, the group elects another one. The result is a system that can keep a strongly ordered history of changes even while individual machines come and go.
Leader awareness: sending requests to the right place
Now that we’ve seen how every Raft group has a leader, let’s look at the next important question:
How does the client know where to send the request?
In a Raft-based system, the leader is the replica that coordinates the work for the group. It decides the order of operations, appends new entries to the replicated log, and drives replication to the followers. For ScyllaDB Strong Consistency, where every tablet has its own Raft group, this means that every tablet also has a current Raft leader.
That creates an important difference from eventual consistency. With eventual consistency, a client request can usually be sent to one of the replicas, and that replica can act as the coordinator for the operation. The driver does not necessarily need to know which replica is “special,” because there is no Raft leader that must order the operation first.
With strong consistency, the situation is different. If a request reaches a follower, that follower cannot independently decide the order of the operation. The leader must coordinate the operation. The follower may have the data, and it may be part of the Raft group, but it is not the replica currently responsible for sequencing new writes or strongly consistent operations.
So the request has to reach the leader.
Request forwarding
To make this work, ScyllaDB implements request forwarding.
It works like this:
- The client sends a request to one of the replicas.
- If that replica is the Raft leader for the tablet, it handles the request directly.
- If that replica is a follower, it acts as a proxy for the request.
- The leader processes the request through Raft.
- The result is returned back through the forwarding replica to the client.
This gives us an important correctness property:
Even if the client reaches the wrong replica, the operation is still coordinated by the Raft leader.
That is exactly what we want. The leader remains the single place where the ordered history of the tablet is created. Followers can help route the request, but they do not bypass the leader or make independent decisions.
This forwarding mechanism is especially useful because leadership can change. A leader may fail, restart, become unreachable, or step down. When that happens, the Raft group elects a new leader. Request forwarding gives the system a way to continue operating even when the client does not yet know about the new leadership state.
The cost of forwarding
However, request forwarding has a cost. If the client sends the request to a follower, the request has to make an extra network hop:
client → follower → leader → follower → client
Instead of the simpler path:
client → leader → client
That extra communication adds latency. It also increases the number of messages inside the cluster. For occasional requests, this may be acceptable. But for a high-performance database, especially under heavy read and write workloads, unnecessary network hops matter.
This is where leader awareness becomes important.

Leader-aware drivers
A leader-aware driver allows the client driver itself to learn which replica is the leader for a given tablet. Instead of blindly sending requests to any replica and relying on forwarding, the driver can send future requests directly to the leader.
The first request may still go to any replica. If it reaches a follower, the follower can forward it to the leader. But when the response comes back, the driver can also learn:
“For this tablet, this replica is currently the leader.”
From that point on, the driver can route requests directly to the leader.
So the flow becomes:
- The driver sends an initial request.
- If needed, ScyllaDB forwards the request to the current leader.
- The response includes updated leader information.
- The driver remembers the leader for that tablet.
- Future requests go directly to the leader.
This keeps the correctness benefit of forwarding, while reducing its performance cost.
Forwarding is still needed
Leader-aware drivers do not remove the need for request forwarding completely.
Leadership is not permanent. A Raft leader can change at any time due to failures, restarts, topology changes, or elections. When that happens, the driver may temporarily have stale information.
In that case, forwarding is still the safety net:
If the driver sends a request to the old leader or to a follower, ScyllaDB can forward the request to the new leader and update the driver again.
So forwarding remains important, but it becomes the exception rather than the normal path.
Instead of paying the forwarding cost on every request, we mainly pay it at the beginning of communication, after the leader has changed, or when the driver’s leader information is stale.
That is a much better model for performance.
Balancing correctness and performance
Leader awareness gives us the best of both worlds.
Request forwarding gives us correctness and simplicity: requests always reach the Raft leader, even if the client does not know who the leader is.
Leader-aware drivers give us performance: once the driver learns the leader, it can avoid unnecessary hops and send requests directly to the right replica.
For strongly consistent workloads, this is a major optimization. Strong consistency already requires coordination, replication, and quorum agreement. We do not want to add avoidable network hops on top of that. By making the driver aware of tablet leadership, ScyllaDB can preserve the Raft correctness model while reducing latency and improving throughput.
In short:
Request forwarding makes strong consistency work.
Leader-aware drivers make it fast.
The leader-aware driver is planned for the 2026.3 release. In 2026.2 we release forwarding.
The strongly consistent read path: reading from the leader and using a barrier
After understanding that every Raft group has a leader, and that writes must be coordinated by that leader, the next natural question is:
What about reads?
At first glance, reads may look simpler than writes. A read does not change the data, so it may seem safe to read from any replica. But with strong consistency, this is not always enough.
The problem is that replicas may not all be at exactly the same point in the Raft log at the same time. A follower can be slightly behind the leader. It may still be catching up on committed entries. If we read from that follower without any additional coordination, we may accidentally read an older version of the data.
For eventual consistency, this may be acceptable depending on the chosen consistency level and workload. For strong consistency, we need a stronger guarantee:
A read must observe the latest state that was safely committed before the read. That means the read path also needs to respect the Raft ordering model.
Reading from the leader
The simplest way to make a strongly consistent read is to send the read to the Raft leader.
The leader is the replica that coordinates the Raft group. It receives operations, orders them, replicates them, and knows the current progress of the group. Because the leader is the place where the group’s ordered history is created, reading through the leader gives us a natural consistency point.
The basic read path looks like this:
- The client sends a read request.
- The request is routed to the Raft leader for the tablet.
- The leader makes sure it is still allowed to act as leader.
- The leader reads from the state that reflects the committed Raft log.
- The result is returned to the client.
This keeps the read aligned with the same ordering model used by writes.
In other words:
Writes go through the leader to enter the log.
Reads go through the leader to observe the committed result of that log.
This gives the system a clean and understandable consistency model. The leader is not only the place where changes are ordered; it is also the safest place to observe the latest committed state.
Why reading from a follower is not always enough
A follower is still a valid replica. It participates in the Raft group, stores the replicated log, and applies committed entries. But a follower can temporarily lag behind the leader.
For example:
- A write is committed by the leader and a majority of replicas.
- One follower has not applied for that committed entry yet.
- A client reads from that follower.
- The client may see the old value.
From the point of view of that follower, nothing “wrong” happened. It simply has not caught up yet. But from the point of view of strong consistency, the reading may be stale.
This is why strongly consistent reads cannot blindly read from any replica without additional coordination.
If we want reads to be strongly consistent, the system must prove that the replica serving the read is up to date enough for that read.
What is implemented today
Today, before serving a strongly consistent read, ScyllaDB runs read_barrier().
This currently requires network communication with a quorum and also waits for the Raft state machine on the leader to apply any previously written commitlog entries to memtables. In other words, the read must first make sure the leader has caught up with all committed changes before returning a result.
In the near future, we plan to implement Raft leases, which will allow the leader to serve reads locally without additional network hops.
Because of this, we expect strong consistency performance to eventually be on par with eventual consistency, and in some read-heavy cases, it may even be better.
How the leader keeps followers updated
The Raft leader is also responsible for keeping the followers up to date.
When a new operation is accepted by the leader, the leader appends it to its local Raft log and then sends it to the followers. The followers append the same entry to their own logs and acknowledge it back to the leader. Once the leader receives acknowledgments from a majority of replicas, the entry is considered committed.
After that, the committed entry can be applied to the actual database state.
The flow looks like this:
Client request
↓
Raft leader appends entry to its log
↓
Leader sends the entry to followers
↓
Followers append the entry and acknowledge
↓
Majority confirms
↓
Entry is committed
↓
Replicas apply the committed change
The leader has two jobs:
- It orders new operations.
- It continuously brings followers to the same ordered state.
This is important for reads as well. A follower may temporarily be behind the leader, even if it is healthy. That is why strongly consistent reads usually go through the leader, or require an additional synchronization step such as a barrier before the system can safely answer from a known up-to-date state.
How this impacts application developers
Strongly consistent tables simplify application logic. Most developers building a payment flow, quota system, inventory reservation, account state machine, or idempotency layer don’t want to reason about replica divergence. They just want the database to protect the invariant.
Strong consistency also improves predictability. Predictability is not only about latency. It is about knowing what the system will do when two clients race, when a node restarts, or when an operation is retried. A deterministic ordering layer makes these cases easier to explain, test, and debug.
Users should also find that strong consistency makes LWT and transaction workflows much better, cleaner, and faster.

Figure 7: Application-level benefits: fewer eventual consistency anomalies, better counters, better predictability, simpler logic, and a path to better LWT behavior.
How to use strongly consistent tables
This feature is still experimental so please use it with caution.

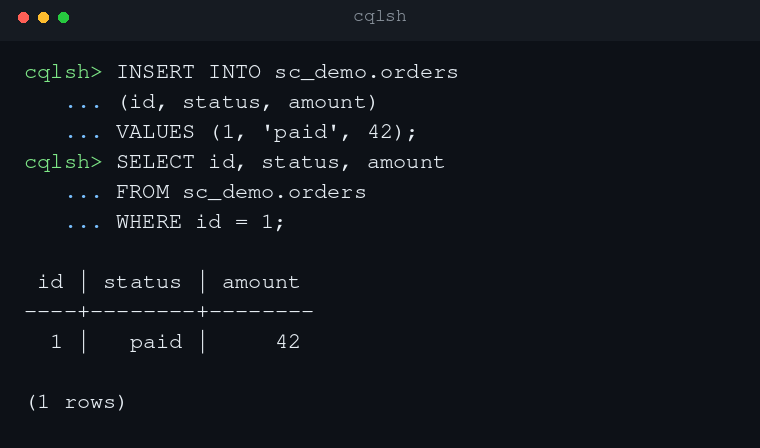
Strong consistency is selected at the keyspace level. With the strongly-consistent-tables experimental feature enabled, create a tablets-based keyspace with consistency = 'global'. Tables created in that keyspace use the strongly consistent path automatically, so applications continue to use ordinary CQL reads and writes. There is no separate per-statement switch for “strong consistency” in the query itself.
CREATE KEYSPACE sc_demo
WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor': 3}
AND tablets = {'enabled': true}
AND consistency = 'global';
CREATE TABLE sc_demo.orders (
id int PRIMARY KEY,
status text,
amount int
);
INSERT INTO sc_demo.orders (id, status, amount) VALUES (1, 'paid', 100);
SELECT * FROM sc_demo.orders WHERE id = 1;This keeps the usage model simple: choose strong consistency when creating the keyspace, then use ordinary CQL on the tables inside it. A fundamental difference from eventual consistency is that strongly consistent writes do not support user-provided timestamps, so applications must let ScyllaDB assign them automatically.

More about LWT
Lightweight transactions are one of the places where users already ask the database for stronger semantics. In eventually consistent architectures, LWT is commonly implemented through Paxos, which requires multiple phases such as prepare, accept, and commit. That can add latency and complexity.
A Raft-backed architecture gives ScyllaDB a path toward a more unified model: LWT-style behavior on top of a shared replicated log. This should give you fewer duplicated mechanisms, fewer voting rounds, and a simpler execution path. The long-term direction is not “add another special protocol,” but “converge on one ordering and replication layer where it makes sense.”

Figure 8: LWT can move from a separate Paxos-based path toward a Raft-backed path with fewer voting rounds and a shared replication layer.
Performance
Strong consistency is not free. A Raft-based write requires a majority, and write latency can increase compared with the fastest eventually consistent path. That is the nature of asking the system to commit to one order before acknowledging the operation.
But the right comparison is not only per-write latency. Strong consistency can also remove repair overhead, conflict-resolution ambiguity, reconciliation logic, and application-side complexity. For correctness-sensitive workloads, paying a predictable coordination cost inside the database can be far better than paying an unpredictable correctness cost across the entire application stack.

Figure 9: Architecture convergence: Raft becomes the unified ordering layer for topology, strongly consistent tables, and LWT.
We don’t expect our users to make every table strongly consistent; this won’t be the default. Our goal is to give you a choice so you don’t have to choose between a high-performance database and a stronger correctness model.
What’s available now and what’s next
The backbone implementation for strongly consistent tables is in ScyllaDB 2026.2. Users can create a keyspace configured for strong consistency, create strongly consistent tables, and read and write to them. This is the foundation: the core path proving that ScyllaDB can execute user-data operations through a Raft-backed strong-consistency model.
But there’s still more to do. We’re still working on details like tablet migration, tablet split and merge support, recovery behavior, and leader-aware driver support. We’re expecting to release these features in 2026.3.
That makes 2026.2 an important milestone: not the end of the journey, but the point where the architecture becomes visible and usable. ScyllaDB is evolving from a high-performance eventually consistent database into a high-performance multi-consistency distributed database.
Conclusion: strong consistency is about removing ambiguity
Distributed systems are already hard enough. The database should remove ambiguity where ambiguity is dangerous.
With Raft-backed strong consistency, ScyllaDB gives users a clearer model for workloads that need correctness, ordering, and predictability. Eventual consistency remains the right choice for many high-scale workloads. Strong consistency becomes the right choice when the application needs one answer, one order, and one source of truth.
We’re excited to share this with you and look forward to your feedback!