





The engineering challenges and design decisions that led to the 1.0 release of ScyllaDB Rust Driver
ScyllaDB Rust driver is a client-side, shard-aware driver written in pure Rust with a fully async API using Tokio. The Rust Driver project was born back in 2021 during ScyllaDB’s internal developer hackathon. Our initial goal was to provide a native implementation of a CQL driver that’s compatible with Apache Cassandra and also contains a variety of ScyllaDB-specific optimizations. Later that year, we released ScyllaDB Rust Driver 0.2.0 on the Rust community’s package registry, crates.io.
Comparative benchmarks for that early release confirmed that this driver was (more than) satisfactory in terms of performance. So we continued working on it, with the goal of an official release – and also an ambitious plan to unify other ScyllaDB-specific drivers by converting them into bindings for our Rust driver.
Now that we’ve reached a major milestone for the Rust Driver project (officially releasing ScyllaDB Rust Driver 1.0), it’s time to share the challenges and design decisions that led to this 1.0 release.
Learn about our versioning rationale
What’s New in ScyllaDB Rust Driver 1.0?
Along with stability, this new release brings powerful new features, better performance, and smarter design choices. Here’s a look at what we worked on and why.
Refactored Error Types
Our original error types met ad hoc needs, but weren’t ideal for long-term production use. They weren’t very type-safe, some of them stringified other errors, and they did not provide sufficient information to diagnose the error’s root cause. Some of them were severely abused – most notably ParseError. There was a One-To-Rule-Them-All error type: the ubiquitous QueryError, which many user-facing APIs used to return.
Before
Back in 0.13 of the driver, QueryError looked like this:
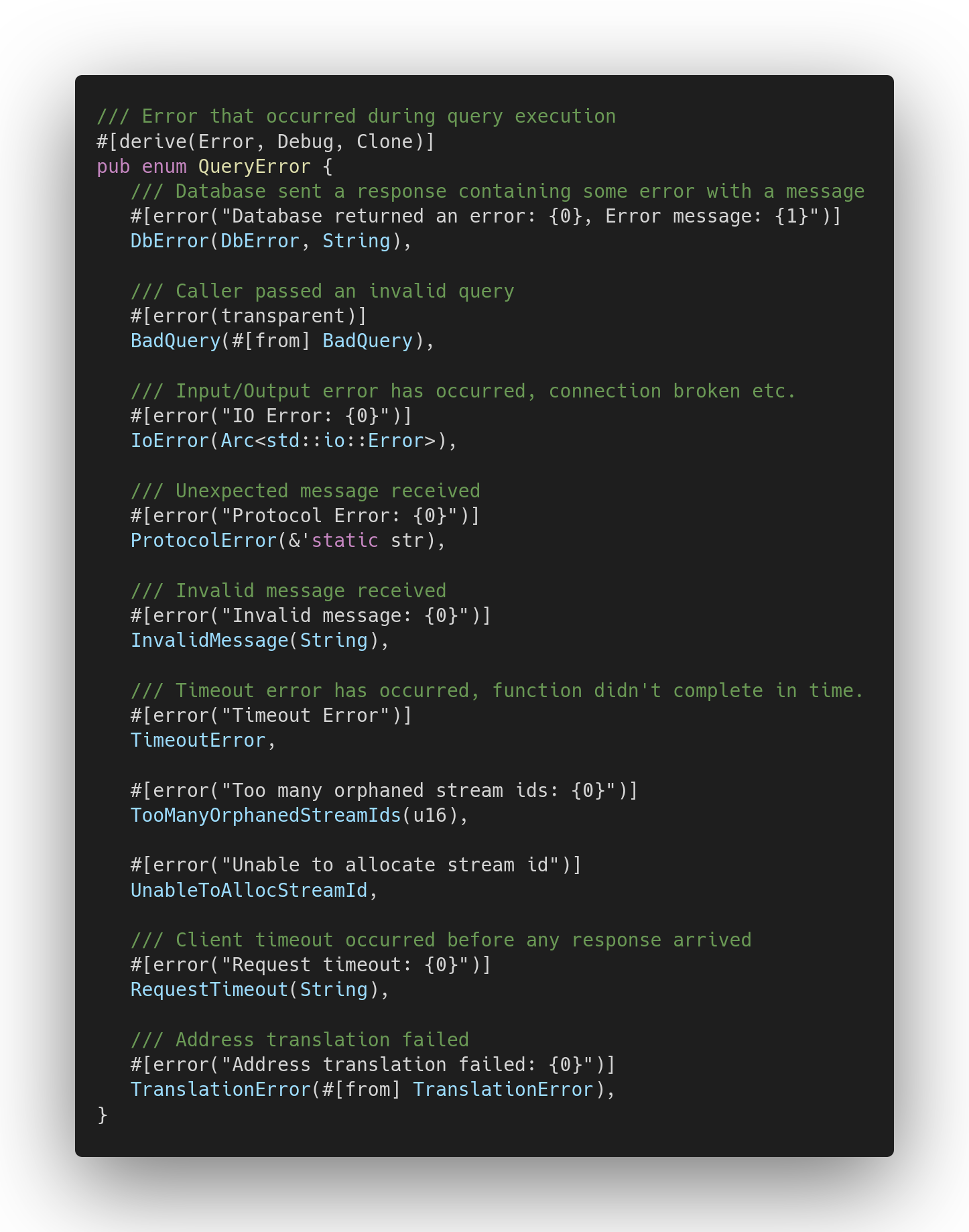 Note that:
Note that:
- The structure was painfully flat, with extremely niche errors (such as
UnableToAllocStreamId) being just inline variants of this enum. - Many variants contained just strings. The worst offender was
Invalid Message, which just jammed all sorts of different error types into a single string. Many errors were buried insideIoError, too. This stringification broke the clear code path to the underlying errors, affecting readability and causing chaos. - Due to the above omnipresent stringification, matching on error kinds was virtually impossible.
- The error types were public and, at the same time, were not decorated with the
#[non_exhaustive]attribute. Due to this, adding any new error variant required breaking the API! It was unacceptable for a driver that was aspiring to bear the name of an API-stable library.
In version 1.0.0, the new error types are clearer and more helpful. The error hierarchy now reflects the code flow. Error conversions are explicit, so no undesired confusing conversion takes place. The one-to-fit-them-all error type has been replaced. Instead, APIs return various error types that exhaustively cover the possible errors, without any need to match on error variants that can’t occur when executing a given function.
The QueryError’s new counterpart, ExecutionError, looks like this:
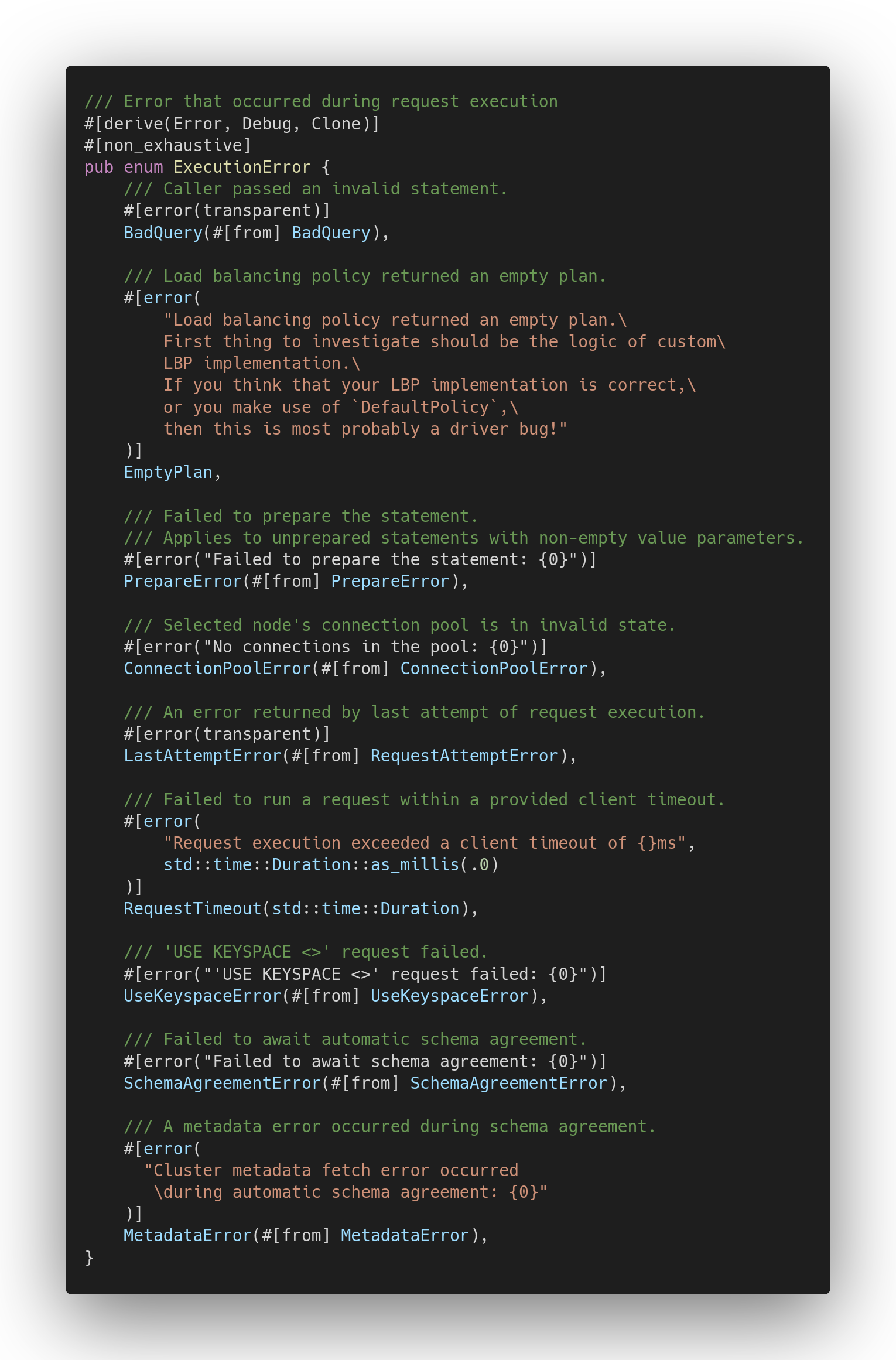
Note that:
- There is much more nesting, reflecting the driver’s modules and abstraction layers.
- The stringification is gone!
- Error types are decorated with the
#[non_exhaustive]attribute, which requires downstream crates to always have the “else” case (like_ => { … }) when matching on them. This way, we prevent breaking downstream crates’ code when adding a new error variant.
Refactored Module Structure
The module structure also stemmed from various ad-hoc decisions. Users familiar with older releases of our driver may recall, for example, the ubiquitous transport module. It used to contain a bit of absolutely everything: essentially, it was a flat bag with no real deeper structure.
Back in 0.15.1, the module structure looked like this (omitting the modules that were not later restructured):
- transport
- load_balancing
- default.rs
- mod.rs
- plan.rs
- locator
- (submodules)
- caching_session.rs
- cluster.rs
- connection_pool.rs
- connection.rs
- downgrading_consistency_retry_policy.rs
- errors.rs
- execution_profile.rs
- host_filter.rs
- iterator.rs
- metrics.rs
- node.rs
- partitioner.rs
- query_result.rs
- retry_policy.rs
- session_builder.rs
- session_test.rs
- session.rs
- speculative_execution.rs
- topology.rs
- load_balancing
- history.rs
- routing.rs
The new module structure clarifies the driver’s separate abstraction layers. Each higher-level module is documented with descriptions of what abstractions it should hold. We also refined our item export policy. Before, there could be multiple paths to import items from. Now items can be imported from just one path: either their original paths (i.e., where they are defined), or from their re-export paths (i.e., where they are imported, and then re-exported from).
In 1.0.0, the module structure is the following (again, omitting the unchanged modules):
- client
- caching_session.rs
- execution_profile.rs
- pager.rs
- self_identity.rs
- session_builder.rs
- session.rs
- session_test.rs
- cluster
- metadata.rs
- node.rs
- state.rs
- worker.rs
- network
- connection.rs
- connection_pool.rs
- errors.rs (top-level module)
- policies
- address_translator.rs
- host_filter.rs
- load_balancing
- default.rs
- plan.rs
- retry
- default.rs
- downgrading_consistency.rs
- fallthrough.rs
- retry_policy.rs
- speculative_execution.rs
- observability
- driver_tracing.rs
- history.rs
- metrics.rs
- tracing.rs
- response
- query_result.rs
- request_response.rs
- routing
- locator
- (unchanged contents)
- partitioner.rs
- sharding.rs
- locator
Removed Unstable Dependencies From the Public API
With the ScyllaDB Rust Driver 1.0 release, we wanted to fully eliminate unstable (pre-1.0) dependencies from the public API. Instead, we now expose these dependencies through feature flags that explicitly encode the major version number, such as "num-bigint-03".
Why did we do this?
- API Stability & Semver Compliance – The 1.0 release promises a stable API, so breaking changes must be avoided in future minor updates. If our public API directly depended on pre-1.0 crates, any breaking changes in those dependencies would force us to introduce breaking changes as well. By removing them from the public API, we shield users from unexpected incompatibilities.
- Greater Flexibility for Users – Developers using the ScyllaDB Rust driver can now opt into specific versions of optional dependencies via feature flags. This allows better integration with their existing projects without being forced to upgrade or downgrade dependencies due to our choices.
- Long-Term Maintainability – By isolating unstable dependencies, we reduce technical debt and make future updates easier. If a dependency introduces breaking changes, we can simply update the corresponding feature flag (e.g.,
"num-bigint-04") without affecting the core driver API. - Avoiding Unnecessary Dependencies – Some users may not need certain dependencies at all. Exposing them via opt-in feature flags helps keep the dependency tree lean, improving compilation times and reducing potential security risks.
- Improved Ecosystem Compatibility – By allowing users to choose specific versions of dependencies, we minimize conflicts with other crates in their projects. This is particularly important when working with the broader Rust ecosystem, where dependency version mismatches can lead to build failures or unwanted upgrades.
- Support for Multiple Versions Simultaneously – By namespacing dependencies with feature flags (e.g.,
"num-bigint-03"and"num-bigint-04"), users can leverage multiple versions of the same dependency within their project. This is particularly useful when integrating with other crates that may require different versions of a shared dependency, reducing version conflicts and easing the upgrade path.
How this impacts users:
- The core ScyllaDB Rust driver remains stable and free from external pre-1.0 dependencies (with one exception: the popular
randcrate, which is still in 0.*). - If you need functionality from an optional dependency, enable it explicitly using the appropriate feature flag (e.g.,
"num-bigint-03"). - Future updates can introduce new versions of dependencies under separate feature flags – without breaking existing integrations.
This change ensures that the ScyllaDB Rust driver remains stable, flexible, and future-proof, while still providing access to powerful third-party libraries when needed.
Rustls Support for TLS
The driver now supports Rustls, simplifying TLS connections and removing the need for additional system C libraries (openssl).
Previously, ScyllaDB Rust Driver only supported OpenSSL-based TLS – like our other drivers did. However, the Rust ecosystem has its own native TLS library: Rustls. Rustls is designed for both performance and security, leveraging Rust’s strong memory safety guarantees while often outperforming OpenSSL in real-world benchmarks.
With the 1.0.0 release, we have added Rustls as an alternative TLS backend. This gives users more flexibility in choosing their preferred implementation. Additional system C libraries (openssl) are no longer required to establish secure connections.
Feature-Based Backend Selection
Just as we isolated pre-1.0 dependencies via version-encoded feature flags (see the previous section), we applied the same strategy to TLS backends. Both OpenSSL and Rustls are exposed through opt-in feature flags.
This allows users to explicitly select their desired implementation and ensures:
- API Stability – Users can enable TLS support without introducing unnecessary dependencies in their projects.
- Avoiding Unwanted Conflicts – Users can choose the TLS backend that best fits their project without forcing a dependency on OpenSSL or Rustls if they don’t need it.
- Future-Proofing – If a breaking change occurs in a TLS library, we can introduce a new feature flag (e.g.,
"rustls-023", "openssl-010") without modifying the core API.
Abstraction Over TLS Backends
We also introduced an abstraction layer over the TLS backends. Key enums such as TlsProvider, TlsContext, TlsConfig and Tls now contain variants corresponding to each backend. This means that switching between OpenSSL and Rustls (as well as between different versions of the same backend) is a matter of enabling the respective feature flag and selecting the desired variant.
- If you prefer Rustls, enable the
"rustls-023"feature and use theTlsContext::Rustlsvariant. If you need OpenSSL, enable"openssl-010"and useTlsContext::OpenSSL. - If you want both backends or different versions of the same backend (in production or just to explore), you can enable multiple features and it will “just work.”
- If you don’t require TLS at all, you can exclude both, reducing dependency overhead.
Our ultimate goal with adding Rustls support and refining TLS backend selection was to ensure that the ScyllaDB Rust Driver is both flexible and well-integrated with the Rust ecosystem. We hope this better accommodates users’ different performance and security needs.
The Battle For The Empty Enums
We really wanted to let users build the driver with no TLS backends opted in. In particular, this required us to make our enums work without any variants, (i.e., as empty enums).
This was a bit tricky. For instance, one cannot match over &x, where x: X is an instance of the enum, if X is empty.
Specifically, consider the following definition:
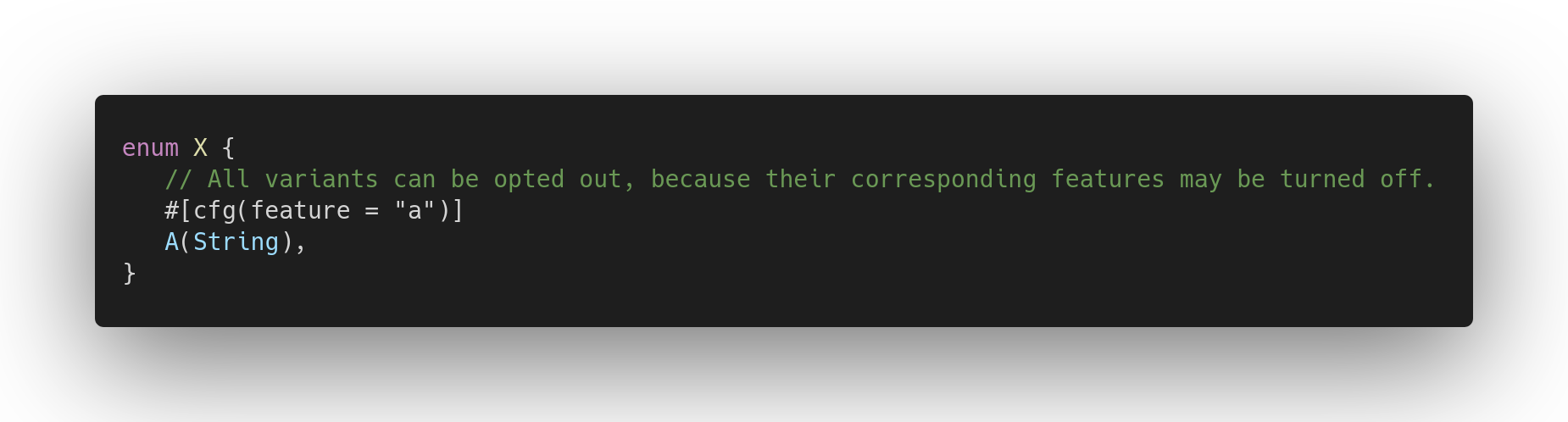 This would not compile:
This would not compile:![]() error[E0004]: non-exhaustive patterns: type `&X` is non-empty
error[E0004]: non-exhaustive patterns: type `&X` is non-empty
–> scylla/src/network/tls.rs:230:11
|
230 | match x {
| ^
|
note: `X` defined here
–> scylla/src/network/tls.rs:223:6
|
223 | enum X {
| ^
= note: the matched value is of type `&X`
= note: references are always considered inhabited
help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern as shown
|
230 ~ match x {
231 + _ => todo!(),
232 + }
|
Note that references are always considered inhabited. Therefore, in order to make code compile in such a case, we have to match on the value itself, not on a reference:
![]() But if we now enable the
But if we now enable the "a" feature, we get another error…
error[E0507]: cannot move out of `x` as enum variant `A` which is behind a shared reference
–> scylla/src/network/tls.rs:230:11
|
230 | match *x {
| ^^
231 | #[cfg(feature = “a”)]
232 | X::A(s) => { /* Handle it */ }
| –
| |
| data moved here
| move occurs because `s` has type `String`, which does not implement the `Copy` trait
|
help: consider removing the dereference here
|
230 – match *x {
230 + match x {
|
Ugh. rustc literally advises us to revert the change. No luck… Then we would end up with the same problem as before.
Hmmm… Wait a moment…
I vaguely remember Rust had an obscure reserved word used for matching by reference, ref. Let’s try it out.
![]() Yay, it compiles!!!
Yay, it compiles!!!
This is how we made our (possibly) empty enums work… finally!.
Faster and Extended Metrics
Performance matters. So we reworked how the driver handles metrics, eliminating bottlenecks and reducing overhead for those who need real-time insights. Moreover, metrics are now an opt-in feature, so you only pay (in terms of resource consumption) for what you use. And we added even more metrics!
Background
Benchmarks showed that the driver may spend significant time logging query latency. Flamegraphs revealed that collecting metrics can consume up to 11.68% of CPU time!

We suspected that the culprit was contention on a mutex guarding the metrics histogram. Even though the issue was discovered in 2021 (!), we postponed dealing with it because the publicly available crates didn’t yet include a lock-free histogram (which we hoped would reduce the overhead).
Lock-free histogram
As we approached the 1.0 release deadline, two contributors (Nikodem Gapski and Dawid Pawlik) engaged with the issue. Nikodem explored the new generation of the histogram crate and discovered that someone had added a lock-free histogram: AtomicHistogram. “Great”, he thought. “This is exactly what’s needed.”
Then, he discovered that AtomicHistogram is flawed: there’s a logical race due to insufficient synchronization! To fix the problem, he ported the Go implementation of LockFreeHistogram from Prometheus, which prevents logical races at the cost of execution time (though it was still performing much better than a mutex). If you are interested in all the details about what was wrong with AtomicHistogram and how LockFreeHistogram tries to solve it, see the discussion in this PR.
Eventually, the histogram crate’s maintainer joined the discussion and convinced us that the skew caused by the logical races in AtomicHistogram is benign. Long story short, histogram is a bit skewed anyway, and we need to accept it.
In the end, we accepted AtomicHistogram for its lower overhead compared to LockFreeHistogram. LockFreeHistogram is still available on its author’s dedicated branch. We left ourselves a way to replace one histogram implementation with another if we decide it’s needed.
More metrics
The Rust driver is a proud base for the cpp-rs-driver (a rewrite of cpp-driver as a thin bindings layer on top of – as you can probably guess at this point – the Rust driver). Before cpp-driver functionalities could be implemented in cpp-rs-driver, they had to be implemented in the Rust driver first. This was the case for some metrics, too. The same two contributors took care of that, too. (Btw, thanks, guys! Some cool sea monster swag will be coming your way).
Metrics as an opt-in
Not every driver user needs metrics. In fact, it’s quite probable that most users don’t check them even once. So why force users to pay (in terms of resource consumption) for metrics they’re not using? To avoid this, we put the metrics module behind the "metrics" feature (which is disabled by default). Even more performance gain!
For a comprehensive list of changes introduced in the 1.0 release, see our release notes.
Stepping Stones on the Path to the 1.0 Release
We’ve been working towards this 1.0 release for years, and it involved a lot of incremental improvements that we rolled out in minor releases along the way. Here’s a look at the most notable ones.
Ser/De (from versions 0.11 and 0.15)
Previous releases reworked the serialization and deserialization APIs to improve safety and efficiency. In short, the 0.11 release introduced a revamped serialization API that leverages Rust’s type system to catch misserialization issues early. And the 0.15 release refined deserialization for better performance and memory efficiency. Here are more details.
Serialization API Refactor (released in 0.11): Leverage Rust’s Powerful Type System to Prevent Misserialization — For Safer and More Robust Query Binding
Before 0.11, the driver’s serialization API had several pitfalls, particularly around type safety. The old approach relied on loosely structured traits and structs (Value, ValueList, SerializedValues, BatchValues, etc.), which lacked strong compile-time guarantees. This meant that if a user mistakenly bound an incorrect type to a query parameter, they wouldn’t receive an immediate, clear error. Instead, they might encounter a confusing serialization error from ScyllaDB — or, in the worst case, could suffer from silent data corruption!
To address these issues, we introduced a redesigned serialization API that replaces the old traits with SerializeValue, SerializeRow, and new versions of BatchValues and SerializedValues. This new approach enforces stronger type safety. Now, type mismatches are caught locally at compile time or runtime (rather than surfacing as obscure database errors after query execution).
Key benefits of this refactor include:
- Early Error Detection – Incorrectly typed bind markers now trigger clear, local errors instead of ambiguous database-side failures.
- Stronger Type Safety – The new API ensures that only compatible types can be bound to queries, reducing the risk of subtle bugs.
Deserialization API Refactor (released in 0.15): For Better Performance and Memory Efficiency
Prior to release 0.15, the driver’s deserialization process was burdened with multiple inefficiencies, slowing down applications and increasing memory usage. The first major issue was type erasure — all values were initially converted into the CQL-type-agnostic CqlValue before being transformed into the user’s desired type. This unnecessary indirection introduced additional allocations and copying, making the entire process slower than it needed to be.
But the inefficiencies didn’t stop there. Another major flaw was the eager allocation of columns and rows. Instead of deserializing data on demand, every column in a row was eagerly allocated at once — whether it was needed or not. Even worse, each page of query results was fully materialized into a Vec<Row>. As a result, all rows in a page were allocated at the same time — all of them in the form of the ephemeric CqlValue. This usually required further conversion to the user’s desired type and incurred allocations. For queries returning large datasets, this led to excessive memory usage and unnecessary CPU overhead.
To fix these issues, we introduced a completely redesigned deserialization API. The new approach ensures that:
- CQL values are deserialized lazily, directly into user-defined types, skipping
CqlValueentirely and eliminating redundant allocations. - Columns are no longer eagerly deserialized and allocated. Memory is used only for the fields that are actually accessed.
- Rows are streamed instead of eagerly materialized. This avoids unnecessary bulk allocations and allows more efficient processing of large result sets.
Paging API (released in 0.14)
We heard from our users that the driver’s API for executing queries was prone to misuse with regard to query paging. For instance, the Session::query() and Session::execute() methods would silently return only the first page of the result if page size was set on the statement. On the other hand, if page size was not set, those methods would perform unpaged queries, putting high and undesirable load on the cluster. Furthermore, Session::query_paged() and Session::execute_paged() would only fetch a single page! (if page size was set on the statement; otherwise, the query would not be paged…!!!)
To combat this:
- We decided to redesign the paging API in a way that no other driver had done before. We concluded that the API must be crystal clear about paging, and that paging will be controlled by the method used, not by the statement itself.
- We ditched
query()andquery_paged()(as well as theirexecutecounterparts), replacing them withquery_unpaged()andquery_single_page(), respectively (similarly forexecute*). - We separated the setting of page size from the paging method itself. Page size is now mandatory on the statement (before, it was optional). The paging method (no paging, manual paging, transparent automated paging) is now selected by using different session methods (
{query,execute}_unpaged(),{query,execute}_single_page(), and{query,execute}_iter(), respectively). This separation is likely the most important change we made to help users avoid footguns and pitfalls. - We introduced strongly typed PagingState and PagingStateResponse abstractions. This made it clearer how to use manual paging (available using
{query,execute}_single_page()). - Ultimately, we provided a cheat sheet in the Docs that describes best practices regarding statement execution.
Looking Ahead
The journey doesn’t stop here. We have many ideas for possible future driver improvements:
- Adding a
preludemodule containing commonly used driver’s functionalities. - More performance optimizations to push the limits of scalability (and benchmarks to track how we’re doing).
- Extending CQL execution APIs to combine transparent paging with zero-copy deserialization, and introducing
BoundStatement. - Designing our own test harness to enable cluster sharing and reuse between tests (with hopes of speeding up test suite execution and encouraging people to write more tests).
- Reworking CQL execution APIs for less code duplication and better usability.
- Introducing
QueryDisplayerto pretty print results of the query in a tabular way, similarly to thecqlshtool.- (In our dreams) Rewriting
cqlsh(based on Python driver) with cqlsh-rs (a wrapper over Rust driver).
- (In our dreams) Rewriting
And of course, we’re always eager to hear from the community — your feedback helps shape the future of the driver!
Get Started with ScyllaDB Rust Driver 1.0
If you’re working on cool Rust applications that use ScyllaDB and/or you want to contribute to this Rust driver project, here are some starting points.
- GitHub Repository: ScyllaDB Rust Driver – Contributions welcome!
- Crates.io: Scylla Crate
- Documentation: crate docs on docs.rs, the guide to the driver.
And if you have any questions, please contact us on the community forum or ScyllaDB User Slack (see the #rust-driver channel).





