





New Rust library is faster than its Go counterpart – and uses less CPU
TL;DR ScyllaDB has a longstanding partnership with University of Warsaw: teams of Computer Science undergraduate students collaborate with ScyllaDB engineers to develop new features for ScyllaDB and to create new libraries that consume those features. One such project– a library that makes it easy to develop Rust applications that consume data from a ScyllaDB Change Data Capture Log – was just released, and it’s the focus of this blog. This new Rust library is faster than its Go counterpart – and it uses less CPU as well.
This project involved a group of 4 students: myself, Marcin Mazurek, Adam Boguszewski, and Maciej Herdon. Our supervisor for the bachelor’s thesis was Dr. Janina Mincer-Daszkiewicz. Piotr Dulikowski was our technical supervisor.
Background
ScyllaDB’s Change Data Capture (CDC) allows users to track the operations that update the data in a cluster. This earlier CDC blog shares useful information about why such a library is necessary and helpful for writing CDC consuming applications and what are the main challenges that the libraries overcome.
At a very high level, such a library allows ScyllaDB users to build streaming data pipelines that allow real-time data processing and analysis. It is no longer sufficient to just store data and process it once or twice a day with a batch job. More and more use cases require an almost immediate reaction to modifications occurring in the database. In a fast-moving world, the amount of new information is so big that it has to be processed on the spot. Otherwise, the backlog will grow to an unmaintainable size.
We previously released Go and Java libraries that would simplify consuming the CDC logs to address these challenges. But what about Rust?
Some time ago, a ScyllaDB internal developer hackathon gave rise to the open-source ScyllaDB Rust Driver. The development of the driver continued, adding new features such as authentication support with clusters that require username+password authentication, execution profile API and refactored load balancing module. The driver is officially in beta and recently it gained a lot of traction from the Rust community. Benchmarks have shown that the driver is very competitive in terms of scalability and performance. And as demonstrated by the number of downloads on crates.io, the driver has been gaining more and more traction. That’s a good indicator that the driver would be a good base for other libraries, such as a library for ScyllaDB CDC. This sparked a new year-long academic project co-organized with the University of Warsaw, where a group of 4 students were engaged in implementing a library for Scylla CDC in Rust, along with some example applications and benchmarks. This blog post explains how to write an application that processes CDC logs using this library, and also explores the library’s performance in comparison to its Java and Go counterparts.
So, let’s just jump right into it and learn more about the library and how to use it.
About the Library
The library was written in pure Rust, using Scylla Rust Driver and Tokio. It features:
- A simple callback-based interface for consuming changes from CDC streams,
- Automatic retries in case of errors,
- Transparent handling of the complexities related to topology changes,
- Optional checkpointing functionality – the library can be configured to save progress so that it can later continue from saved point after restart.
To learn more about how to use the library, see the tutorial on GitHub.
Like other CDC libraries, it can be used in multiple use cases. Most of them can be grouped into two categories: integration with other systems and real-time processing of data. Real-time processing can be done for example with Kafka Streams or Spark and is useful for triggers and monitoring. For example, it might be desirable to send an SMS to a user if a login attempt is performed from a country the user does not live in. Change Data Capture is also useful to replicate data stored in the database to other systems that create indexes or aggregations for it.
Getting Started
Let’s see how to install and use the Rust library in a simple program that will print the changes happening to a table in real-time.
The latest version of the library is available here. You can integrate it into your application by adding the following dependency in your Cargo.toml file:
scylla-cdc = { git = "https://github.com/scylladb/scylla-cdc-rust" }
Setting up the CDC consumer
Next, let’s create a CDCLogReader instance step by step, providing the required configuration through a CDCLogReaderBuilder instance. First, we need to establish a connection with a ScyllaDB cluster using the Rust driver:
let session: Session = SessionBuilder::new().known_node("127.0.0.1:9042").build().await.unwrap();
Next, we need to provide the base table name: keyspace and the table name. Note that the provided names should be of the base table but not the CDC log table (e.g., t.test and not t.test_scylla_cdc_log):
let keyspace: & str = "t";
let table: & str = "test";
Lastly, we should provide a change consumer factory which should implement the ConsumerFactory trait, and we need to define a consumer type, which should implement the Consumer trait:
Each consumer instance is able to consume changes from multiple streams in chronological order. The CDCLogReader instance will process generations one by one; when it starts to process the next generation, it stops the consumers from the previous generation. The library will create new consumers for each stream in every generation, so it is necessary to provide a consumer factory. The CDCLogReader instance will spawn a tokio task which will periodically fetch changes associated with certain streams in user specified window sizes and feed those changes to consumers associated with those streams. When the CDCLogReader configuration is ready, we can build an instance which will automatically start the reading process.
Consuming CDC changes
Now, let’s implement a printer application that shows what kind of information is available about the change. The CDCRow object represents a single row in a CDC log table. There are two types of columns in a CDCRow object:
- CDC log columns (streamID, timestamp, operation, TTL, etc)
- Base table columns
First, let’s show information that is independent of the schema of the base table (cdc$stream_id, cdc$time, etc).
We should omit details about the change schema such as data types of a column or whether a column is part of the primary key as a CDCRow object currently does not provide such information. So, let’s print the values in the Rust language’s debug format:
Full Example
The full source code of the Printer is available here on GitHub, and you can run it with the following commands:
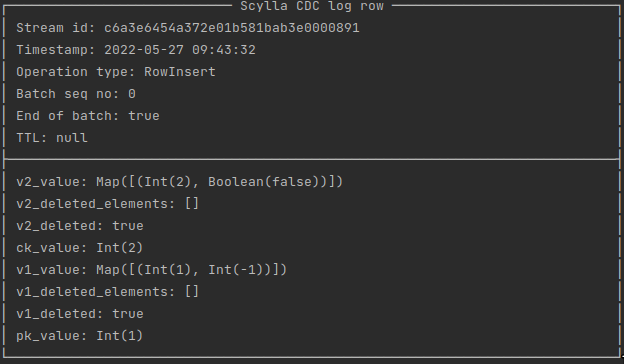
Here is an example result that our application has printed for a specific cdc row:
Saving progress
The library supports saving progress and restoring the last saved point in time for a particular stream. Imagine that there is a sudden power outage and you have to start the whole process again. By periodically saving progress, you can avoid having to start from the very beginning in such cases.
Note: This is an optional feature and you need to explicitly enable it.
If saving is enabled, the library will create a new Tokio task that will periodically save the beginning of the next time window.
To enable this feature, you need an object that implements the CDCCheckpointSaver trait. We provide an example implementation called TableBackedCheckpointSaver that saves progress in a ScyllaDB table alongside the base table and CDC log table.
To create TableBackedCheckpointSaver:
Note: You need to provide a custom table name that is not already used in a given keyspace.
Now we can tell CDCLogReaderBuilder that we want to save/load progress using user_checkpoint_saver:
Benchmarks
The benchmark starts reading from the first CDC generation in the cluster and counts the number of read rows; when it reaches a certain value, the benchmarking application stops. To ensure that no row is missed or read twice, the benchmark application calculates a checksum which is the sum of all the values of clustering keys. The benchmarking applications for all libraries were based on the printer application.
To make our benchmark fair for Java, we needed to warm up the JVM. We chose to do it by letting the Java benchmarking application read the first half of the rows and then benchmark the reading of the second half. The heap and stack size of the JVM was chosen to be fairly high to avoid a lot of garbage collection overhead. Also, it was necessary to do a little tuning for the size of the ExecutorService threadpools used in the Java CDC library.
The varying parameter in the benchmarks was the query window size: 15, 30 and 60 seconds and also the number of cores available for the benchmark. The latter was configured by using the taskset command. The sleep interval was 1 ms in order to simulate the Java library’s behavior, which does not sleep between processing data.
The benchmarks were run on local machines with 16 cores and 128GB of memory. The ScyllaDB cluster had 1 node with 8 shards. The testing table contained 40000 different partition keys with 2500 clustering keys for each partition key. So, overall the table contained 100000000 (100 million) rows and all the corresponding CDC rows had type RowInsert. The data was written with Scylla-bench. Taking into consideration that when a JVM based app is launched, the first requests the JVM receives are generally slower than the average response time, it would not be fair to compare the library in Java with Rust and Go without a proper JVM warm-up. So, in fact, we let the benchmarking applications read the first 50 million rows, and then start to benchmark the second 50 million, so that the main code path is compiled and “hot” for JVM.
Results
The results showed that the Rust library is actually as fast as (or maybe even slightly faster than) the Go library – and far faster than the Java driver. As the results did not differ significantly for 15, 30 and 60 second window sizes, the following chart illustrates some results of the benchmark with a window size equal to 60 seconds and on one core:
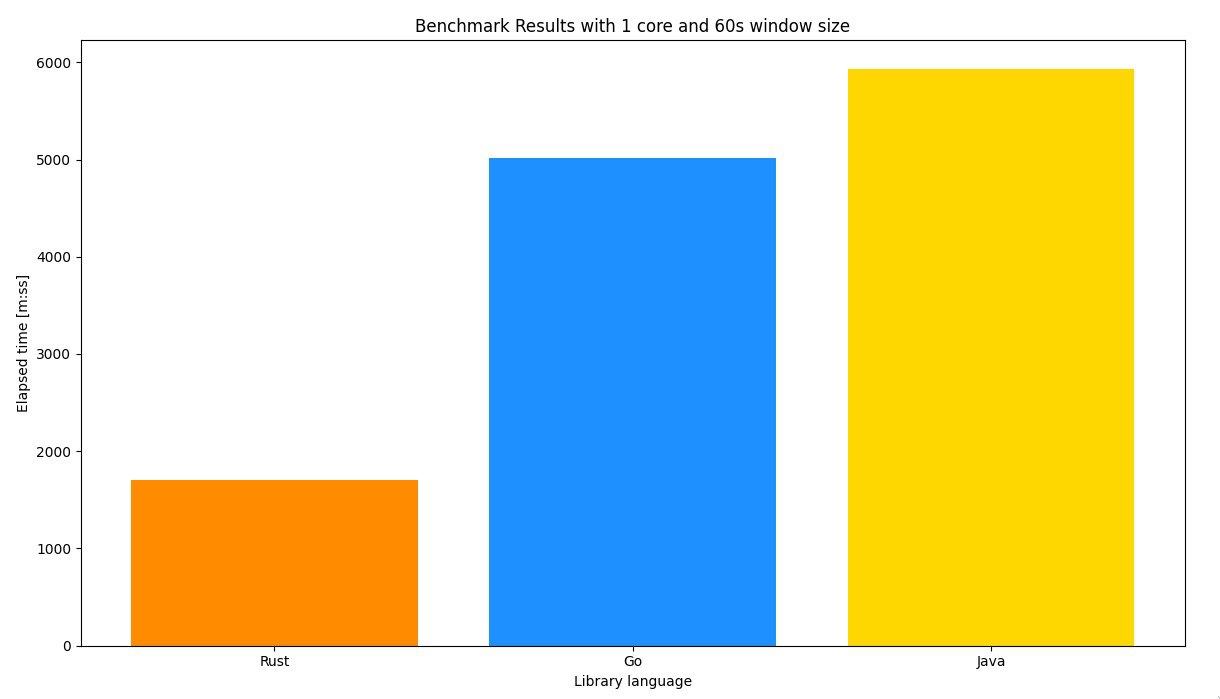
It is worth noting that it would be hard to compare Scylla-cdc-rust and Scylla-cdc-go in a benchmark with more rows without using a bigger cluster. The ScyllaDB instances during the benchmark had 42 shards in total and yet it was not able to process all the requests without noticeable latencies.
In the benchmark, Scylla-cdc-rust showed one significant advantage over Scylla-cdc-go. For window size equal to 15 seconds, the CPU usage (measured as a percentage of usage of a single core) for Rust was 169%, for 30 seconds – 147%, and for 60 seconds – 115%. The results for Go were 404%, 310% and 234% respectively. This shows the Rust library has one more advantage, as it used a lower percentage of CPU.
Summary
As we can see, the creation of the ScyllaDB Rust Driver has opened a path for creating fast applications and libraries connecting to a ScyllaDB cluster, such as a library for consuming Scylla CDC logs. The library has a user-friendly interface, which we showed by creating a simple printer application.
As mentioned above, this was a year-long project designed and developed by students from University of Warsaw and supervised by programmers from ScyllaDB, the fastest distributed database. The project was a foundation for the Bachelor’s thesis of the students who took part in it. It was reviewed and accepted by the University of Warsaw. You can read the complete thesis here; it contains a detailed description of the design, objectives, tests, and results.
Continue Learning About CDC
In this blog, we explained what problems the scylla-cdc-rust library solves and how performant it is in relation with scylla-cdc-go and scylla-cdc-java libraries. To learn more about it, check out the links below:
- Consuming CDC with Java and Go: Learn about CDC consuming libraries in Java and Go.
- Change Data Capture documentation: Knowledge about the design of ScyllaDB’s CDC can be helpful in understanding the concepts in the documentation for both the Java and Go libraries. The parts about the CDC log schema and representation of data in the log is especially useful.
- ScyllaDB University CDC lesson: Expand your knowledge about CDC in this tutorial.
- ScyllaDB Users Slack CDC channel: Ask anything about CDC on our Slack channel.
Take a Deep Dive into Rust + Low-Latency Engineering …at P99 CONF
If you’re interested in Rust and low-latency engineering, join us for P99 CONF 2023. P99 CONF is a free 2-day community event that’s intentionally virtual, highly interactive, and purely technical.
We’ve already got quite a few Rust tech talks on the agenda, including:
Ingesting in Rust
(Armin Ronacher, Sentry)
Expanding Horizons: A Case for Rust Higher Up the Stack
(Carl Lerche, AWS)
High-Level Rust for Backend Programming
(Adam Chalmers, KittyCAD)
5 Hours to 7.7 Seconds: How Database Tricks Sped up Rust Linting Over 2000X
(Predrag Gruevski, Trustfall)
Making Python 100x Faster with Less Than 100 Lines of Rust
(Ohad Ravid, Trigo)




