




The following is a guest post by Jasper Visser, a self-taught programmer and enthusiastic Rustacean who is interested in scalable software design. Jasper is the kind of programmer who automates a 1-minute task by hand and likes to develop and contribute to open source projects.
For more on Rust, the developers at ScyllaDB are hosting a hands-on workshop that covers the Rust driver and sample code.
Today, I’m excited to unveil a project that I’ve been working on for the past few months. The majority of my working days are spent working with Java and SQL. In my spare time, I like to check out new technology and languages. I have been coding for quite a while now, starting around 5 years ago with Swift, a language created by Apple for making iOS/macOS apps. I like creating libraries which are used as building blocks for other people’s projects. Swift looks quite a lot like Rust, the language that is used for Catalytic.
I crossed paths with Rust after reading some RFCs regarding Swift’s development. Swift wants to implement features Rust has, especially the unique Ownership model. Rust was released in about the same year as Swift. While Swift is a little more ergonomic (no lifetimes for example), Rust provides much more flexibility, safety and speed. I really like Rust’s ownership system and the effort of the community to make it compete with the speed of C, while also remaining safe. I made some side projects in Rust, including GRDB-ORM, a wrapper around GRDB which is in turn a thin wrapper for SQLite. GRDB-ORM generates high speed and safe Swift code which can interact with an SQLite database. It generates Swift structs based on the metadata of the database. I like the idea of having a reliable library which derives code from database metadata.
My original goal was to build a server that would enable communication among iOS apps. The server needed a database which is able to handle a lot of writes while remaining scalable. Since scaling horizontally is an issue for relational databases, I had to search for a non-relational database that doesn’t suffer from scaling limitations.
It was a joy working with GRDB-ORM. The generated code ensured I wouldn’t have runtime issues. I knew that I needed something similar on the server side as well.
ScyllaDB and the Rust Driver

I came across ScyllaDB and I immediately liked the design: multiple computers (nodes) talking to each other and communicating the latest updates. I was impressed to see that ScyllaDB can handle 1 billion inserts a second and officially supports materialized views, a feature sorely lacking in Apache Cassandra. Combine that with the knowledge that scaling is as simple as adding nodes, and you have an awesome database.
With an awesome database should come awesome drivers. I was really happy to see the team recently released an official Rust ScyllaDB driver. I think the team did a great job developing a Rust driver with the latest technology, in particular, the Tokio framework. It is fully async and provides a decent number of proc macros, making the library ergonomic and easy to setup.
The maintainers of the rust-scylla-driver respond quickly to issues and are happy to profile and improve the driver. That triggered me enough to write Catalytic, a blazingly fast and safe ORM (Object–relational mapping) built on top of ScyllaDB’s official Rust driver. I did this because I hate:
❌ Run-time query errors
❌ Incorrect mapping between table and Rust struct. You usually want to have a Rust struct which maps 1-on-1 with a table in ScyllaDB. If you create the Rust structs by hand, it is possible to make a typo in the field declaration.
❌ Manually changing Rust structs when the schema changes
❌ Checking whether queries are still valid
Catalytic
Catalytic is designed to solve those problems. Straight out-of-the-box, it provides:
✅ Compile time checked queries
✅ Automatic table-to-Rust-struct mapping
✅ Auto serialize-deserialize types with the famous serde crate
The library isn’t fully complete: not all types are supported yet. Please feel free to add a new type and submit a PR!

an homage to Orm Marius
The ORM exclusively uses the prepared statement cache of the Rust driver. This means the driver will reuse queries if it can, providing the fastest query execution possible. To check what is generated based on this table definition, see this file. The Rust structs are generated in a directory you specify. This means you can generate the mapping once and use your crate without a running ScyllaDB definition.
Setup
Make sure you have ScyllaDB running. For this tutorial I recommend running ScyllaDB in Docker. ScyllaDB provides an excellent course that covers the Rust driver, therefore I skipped the introduction of the driver in this guide.
Let me show you the possibilities of Catalytic with the help of some code. The project with the finished code can be found here. For this example, a simple table is defined in ScyllaDB:
create keyspace scylla_mapping with replication = {
'class': 'SimpleStrategy',
'replication_factor': 3
};
use scylla_mapping;
create table person(name text, age int, email text, json_example text, primary key((name), age));Make sure your database is reachable from localhost with port 9042. You can change the database URL with the environment variable: SCYLLA_URI.
Let’s get our hands dirty and start with creating a Rust binary crate:
$ cargo new scylla_mapper --binCreate a rustfmt.toml file next to the Cargo.toml file. This file will format the generated code. The rustfmt.toml file should only have this as content:
edition = "2021"Open the project in your favorite IDE and navigate to the Cargo.toml file. Add dependencies on the Catalytic and ScyllaDB crate:
[build-dependencies]
catalytic = "0.1"
catalytic_table_to_struct = "0.1"
[dependencies]
catalytic = "0.1"
catalytic_macro = "0.1"
scylla = "0.3"
tracing = "0.1"
tracing-subscriber = "0.2"Run your executable, which will download the dependencies. This is required to get autocomplete working in the IDE (I had to restart my IDE). The build-dependencies section is for a build.rs file. The code inside a build.rs will execute when code changes are made in any of the source files.
Create a build.rs file next to the Cargo.toml and rustfmt.toml file. In this build.rs, we call the table mapper to generate Rust structs. Copy paste this code into the new file:
use catalytic_table_to_struct::transformer::DefaultTransformer;
use std::env::current_dir;
fn main() {
// 1
catalytic_table_to_struct::generate(
// 2
¤t_dir().unwrap().join("src").join("generated"),
// 3
DefaultTransformer,
);
}- Calls the
fnwhich actually generates the Rust structs from the database metadata - The dir to put the generated code in
- A customization point. The
DefaultTransformeris not intelligent, so it probably needs to be changed to a user-specific transformer if you want to do more. For an example of how to do this, see this file.
Navigate to your main.rs file and copy paste this code:
mod generated;
#[tokio::main]
async fn main() {}Add the key-value pair below as an environment variable. You can do this in your IDE or in the terminal if you run cargo from that:
TEST_DB_KEYSPACE_KEY=scylla_mapping
RUST_LOG=debugRun the application. You should now have the generated files in your src directory.
First, let’s run simple CRUD operations. Example operations also available here. First we need a CachingSession, a thin wrapper around a regular ScyllaDB session that caches prepared statements.
Replace the current main.rs file with the following content:
use catalytic::env_property_reader::database_url;
use scylla::statement::Consistency;
use scylla::{CachingSession, SessionBuilder};
mod generated;
#[tokio::main]
async fn main() {
let session = create_session().await;
}
async fn create_session() -> CachingSession {
// Make sure there is logging available when executing the statements
tracing_subscriber::fmt::init();
// Create a session:
// - which can operate on a single node
// - caches 1_000 queries in memory
let session = CachingSession::from(
SessionBuilder::new()
.known_node(database_url())
.default_consistency(Consistency::One)
.build()
.await
.unwrap(),
1_000,
);
// Use the keyspace
session
.session
.use_keyspace("scylla_mapping", false)
.await
.unwrap();
session
}Now that we have generated files and a session which can operate on those structs, let’s try to do stuff with the Person struct. Add this method in your main.rs file:
/// This is an example what you can do with a Person
/// You can only do CRUD operations with structs which borrows values, not owned structs
async fn crud_person(session: &CachingSession) -> Result<(), QueryError> {
// This is an owned struct
// You can convert this to a primary key or a borrowed version
let person = Person {
name: "Jeff".to_string(),
age: 52,
email: "[email protected]".to_string(),
json_example: "something".to_string(),
};
// Insert the person
// First convert it to the borrowed version
person.to_ref().insert(session).await?;
// Select the person back in memory
// This will return an owned struct
let person_queried = person
.primary_key()
.select_unique_expect(session)
.await
.unwrap()
.entity;
assert_eq!(person, person_queried);
// Update the email column of person
// Updating and deleting should always be executed on the borrowed version of the primary key
// since you can only update/delete 1 row
let pk = person.primary_key();
pk.update_email(session, "[email protected]").await?;
// Delete the row in the database
pk.delete(session).await?;
Ok(())
}Make sure your main fn looks like this:
#[tokio::main]
async fn main() {
let session = create_session().await;
crud_person(&session).await.unwrap();
}When you now run the application, you will see in the logging that it inserted the person, selected it back, updated and deleted stuff in the database. A lot of code is generated, which I will guide you through.
Generated File
The file that is derived from the database metadata can be a little overwhelming. The diagram below provides a quick overview of what’s generated:
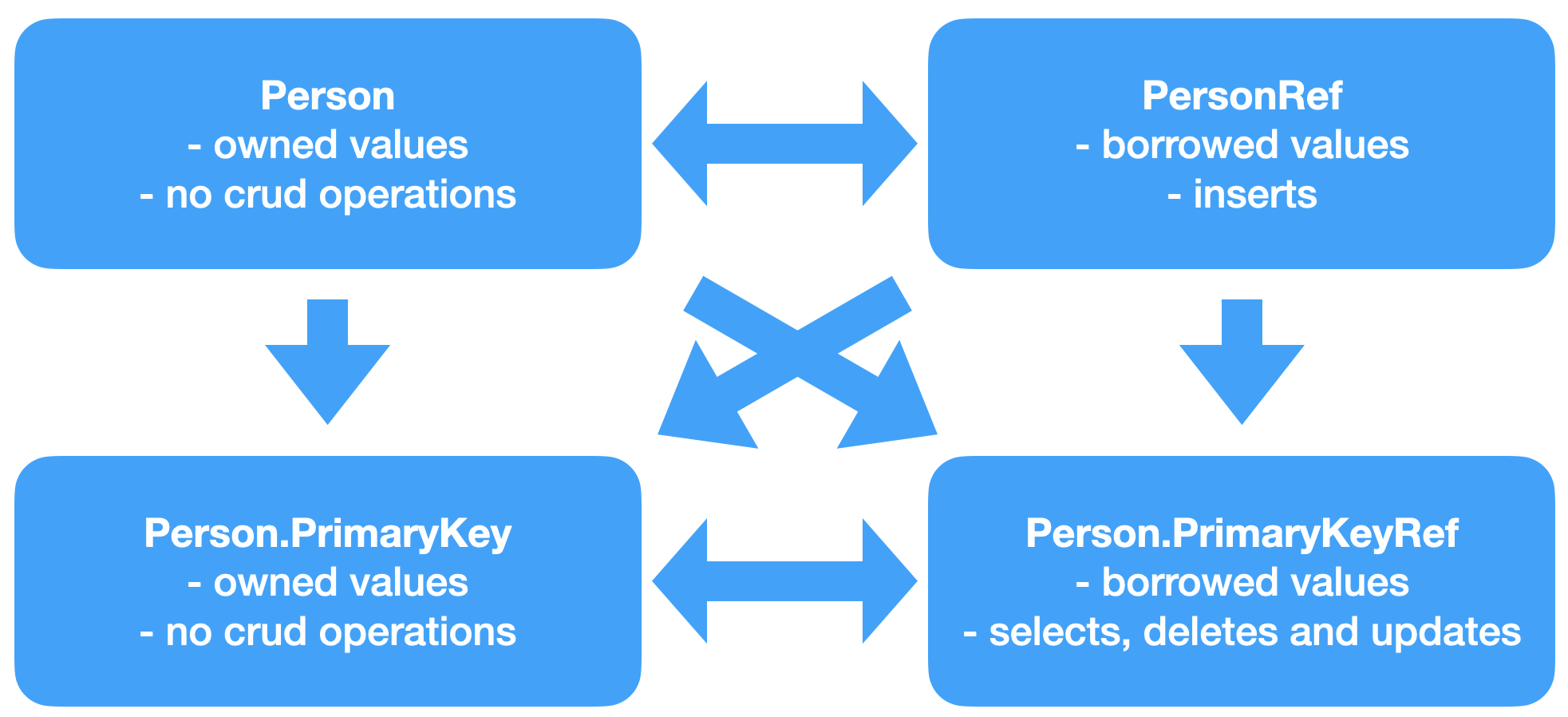
As shown in the diagram above, a few structs are generated for every table in the database. The arrows show which conversion methods are available:
- If you have a
Person, you can create aPersonRef,PrimaryKeyandPrimaryKeyRef. - If you want to insert a person, you would need a
PersonRef, and if you want to update a row, you would need aPrimaryKeyRef.
For examples on how to use this, see this file. When you want to update dynamic columns, you should use the UpdatableColumnRef enum.
Compile Time Checked Queries
Now that we have the structs generated with predefined queries, you might want to write your own query. That can be done with macro crate. This is the method you want to call and you can find an example here. A big note: only static queries are supported. This means you cannot build a query at runtime and check it at compile time!
Let me show you how you can write a compile time checked query. First add another environment variable; this is needed so that the macro can find the modules in which the structs are defined:
GENERATED_DB_ENTITIES_PATH_PREFIX=crate::generatedNow add the compile time checked query:
fn query_persons_older_than(
name: &str,
age: i32,
) -> Result<SelectMultiple<Person>, SerializeValuesError> {
let result =
catalytic_macro::query!("select * from person where name = ? and age > ?", name, age);
Ok(result)
}The macro will replace the select * by selecting all the columns. This is done on purpose, since prepared statements can go out of sync when using *. In this example above, the method returns a SelectMultiple struct. The query macro can read what type of query you want. With the SelectMultiple struct, you can do the following:
- Create an iterator which queries the rows pages, processing the entities one by one
- Selecting everything in memory
- Paging with a pagestate
The code below shows how you can select everything in memory with the SelectMultiple type:
/// Demonstrates an easy way how to write a compile time checked query
async fn compile_time_checked_query(session: &CachingSession) {
// Generate a person, it can be asserted later that the persons are equal to the queried persons
let person = Person {
name: "jhon".to_string(),
age: 20,
email: "nothing special".to_string(),
json_example: "not important".to_string(),
};
// Remember, you can not insert an owned struct, borrowed values only
person.to_ref().insert(session).await.unwrap();
let persons = query_persons_older_than(&person.name, person.age - 1).unwrap();
// Since persons is of type SelectMultiple, functions are available to query multiple rows in the person table
// Including paging, limiting and loading everything in memory
// For now, just load everything into memory
let persons = persons
.select_all_in_memory(&session, 10)
.await
.unwrap()
.entities;
assert_eq!(1, persons.len());
assert_eq!(person, persons[0]);
}Now call it from the main fn. Your main fn should look like this:
#[tokio::main]
async fn main() {
let session = create_session().await;
crud_person(&session).await.unwrap();
compile_time_checked_query(&session).await; // This line is new
}The macro is quite smart in determining what type of query it is. It will reject queries that are already predefined with the table-to-struct mapper, so you never write a query that has already been generated.
Takeaways
We looked at how we can generate Rust structs from ScyllaDB/Cassandra tables. You do this with the table to struct crate. This crate will make sure your Rust structs will always be in sync with the database.
💡 Place the generation of the Rust structs inside a build.rs
💡 You can add the generated files in your .gitignore file. It is generated and should always produce the same output.
For brevity, I won’t elaborate on the Transformer trait but use it to:
- add types that are serializable and deserializable
- specify a different logging library
- add derives on top of the generated structs
- determine if columns are nullable or not
Implementing the transformer trait isn’t hard; see the example file to see how to do this.
Using the macro crate, you can create compile time checked queries. It returns a specific type with methods on it. So, if you write a query that counts the number of rows, it will return a Count struct, on which you can call ‘count’. This extra step ensures that the query does exactly as you want.
💡 Create a workspace and create a separate library containing the generated entities and compile time checked queries. This way, the build.rs isn’t executed every time you change your source files. Add a rerun if changed command to your cql file, then it will automatically run on schema change.
Another very useful feature is the mapping between a materialized view and the base view. If you have a materialized view with exactly the same columns as the base view (different primary keys are permitted), you can convert the materialized view to the base table in two ways:
- There is a special
query_base_tablemacro in the macros crate. You can write your custom query which queries the materialized view. The returned type of the macro will be the type of the base table. The macro will do some checks to see if the conversion is safe at compile time. You can find an example here. This shows that a query is done in a materialized view, but the return type is the struct of the base table. - The generated code will also perform a check to see whether an auto conversion can take place and generates code if it’s safe to do so.
Missing Features
Catalytic is capable of doing a lot of things, making it very easy and safe to interact with ScyllaDB. There are a few things that would be useful if implemented:
- Not all types are supported yet. While the basic types are supported, it lacks support for UDT.
- Checking queries at compile time is possible, as long as the queries are static. This means you can not conditionally add conditions to the query. I am not sure whether it will ever be possible to lift this restriction.
Troubleshooting
Catalytic provides examples for all the functionality, along with lots of tests. If you still have a question, just start a discussion at https://github.com/Jasperav/catalytic/discussions or look at the example folders.
Looking Forward
Rust is an awesome language and, in my opinion, the most convenient one. The ScyllaDB Rust driver is already one of the fastest ScyllaDB drivers, if not the fastest. It also provides a lot of safety. Combined with Catalytic, the Rust developer now has a really powerful toolset to build on ScyllaDB, in probably the fastest way possible.
ScyllaDB’s development is also skyrocketing. ScyllaDB Summit 2022 was held February 9-10, with talks from companies using ScyllaDB in production. Piotr Sarna’s talk, “ScyllaDB Rust Driver: One Driver to Rule Them All” was particularly interesting. You can watch his session and all of the talks on-demand.




