“ScyllaDB is the ideal database for IoT in the industry right now. Especially without the garbage collection that Cassandra has. Small footprint. It just does what you need it to do.”
— Doug Stuns, GPS Insight
Doug Stuns began his presentation at ScyllaDB Summit 2018 by laying out his company’s goals. Founded in 2004, GPS Insight now tracks more than 140,000 vehicles and assets. The company collects a wide variety of data for every one of those vehicles. Battery levels, odometer readings, hard stops, acceleration, vehicle performance, emissions, and GPS data to determine route efficiency.
By the time Doug was brought onboard, they knew they needed to move away from their exclusively SQL SAP Adaptive Server Enterprise (ASE) architecture to include NoSQL for real-time vehicle data management. “They had effectively too much machine data for their relational database environment,” which had been built 8 to 10 years prior. All the GPS data, all the machine data, and all the diagnostic data for monitoring their fleet was being ingested into their SQL system.
Over time, their SQL database just was inadequate to scale to the task. “As the data got larger and larger, it became harder and harder to keep the performance up on all this machine data in a relational database. So they were looking at NoSQL options, and that’s where I came in on the scene for GPS.”
GPS Insight was, at that point, growing their data by a terabyte a year just for diagnostics. Trying to create JOINs against these large tables was creating terrible performance. An additional problem was deleting old data. “With no TTL in a relational database, what are you stuck with? A bunch of custom purge scripts,” which also impacted performance.
“My task was to find a NoSQL-based solution that would handle this. When I originally came to GPS Insight we were 100% going down the Cassandra road… I thought Hadoop was a little too ‘Gen One’ and a little too cumbersome. So I started off heading down this Cassandra road and I stumbled upon ScyllaDB. And from there we decided to do a POC, since we had the opportunity to go with with the best technology.” For example, one major issue Doug did not like about Cassandra was having to maintain an oversized cluster mainly because of Java Virtual Machine (JVM) garbage collection.
Proof of Concept
In the POC, Doug took a year’s worth of data and stood up two 3-node clusters on AWS, consisting of i3.2xlarge machines. They fired off a loading utility and began to populate both clusters.
“We loaded the ScyllaDB data in, like, four or five hours, while it took us close to two days to load the Cassandra data.”
For production, which would scale to a ten-node cluster, ScyllaDB solution engineers advised creating a stand-alone ScyllaDB loader, consisting of a “beefed-up” m4.xl10 instance, with 40 processors on it. On that node, Doug installed the client libraries, and created sixteen child processes.
After loading the cluster, Doug created stress tests: one in PHP and one in golang using the respective language drivers. Both were quick to deploy. “No issues there.”
When they first ran the tests, there was no difference between ScyllaDB and Cassandra. But as they kept increasing load, ScyllaDB scaled while Cassandra quickly topped out. ScyllaDB could execute reads at 75,000 rows per second, while Cassandra was limited to 2,000 rows per second.
Getting to Production
With the POC complete and knowing ScyllaDB could handle the load, it was time to implement. The team’s concerns turned to what business logic (stored procedures, etc.) were already in SAP, and what they would put in ScyllaDB. They decided to focus exclusively on GPS data, diagnostic data, and hardware-machine interface (HMI) data. This would come from the device GPS Insight installed in every vehicle, sending updates on fifteen to twenty data points every second.
For production, GPS Insight decided to deploy a hybrid topology, with five nodes on premises and five nodes in the cloud. The on-premises servers were Dell 720s. “Definitely not state-of-the-art.” While they had 192 GB of RAM, they had spinning HDDs for storage. For the cloud, Doug said they used i3.4xlarge nodes, each with 4TB NVMe storage.
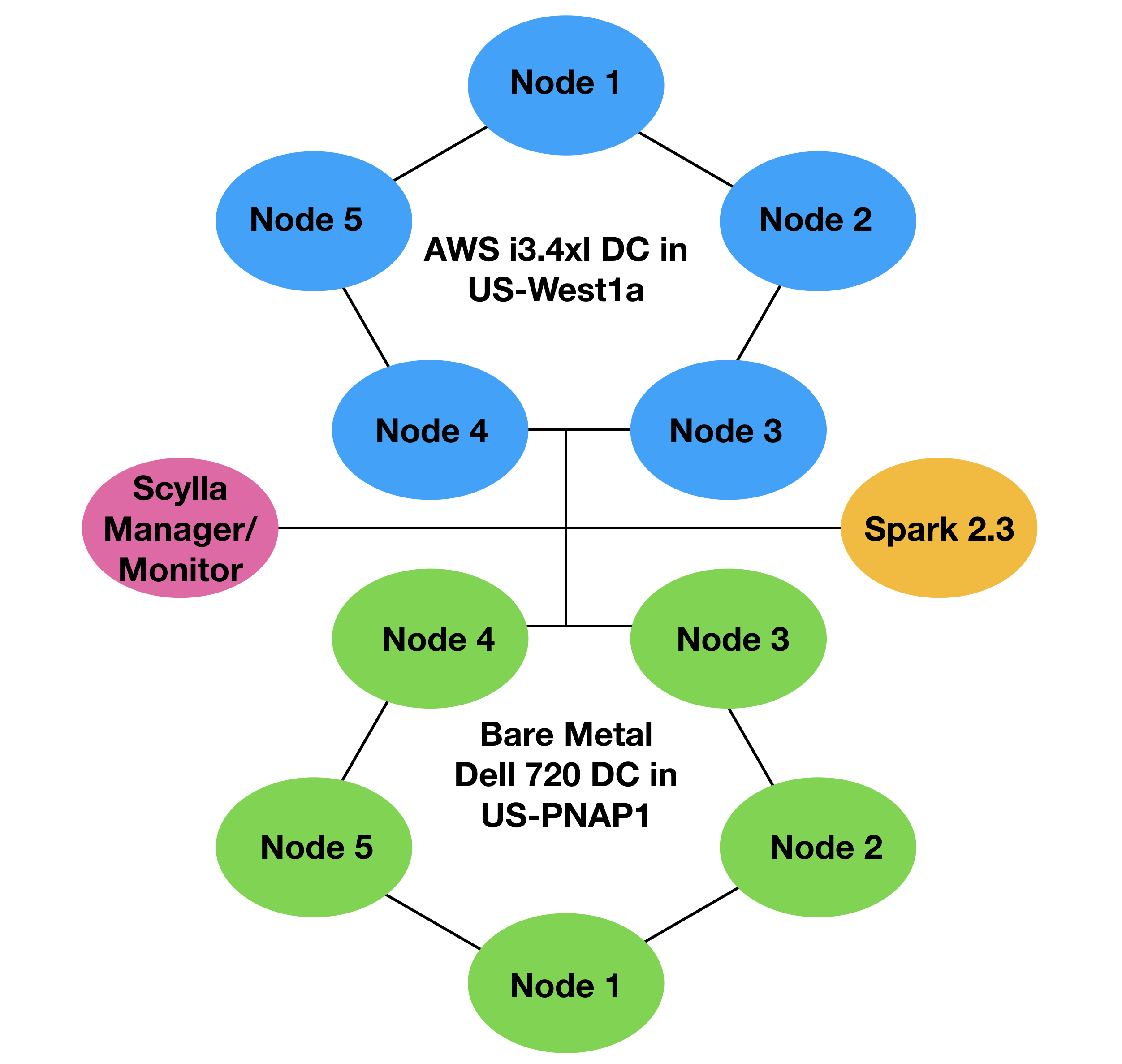
Next, Doug set up a Spark 2.3 node for the developers. Looking at the set of twenty queries they needed to run, they worked together to define a diagnostic Data Definition Language (DDL) to be able to communicate between their ScyllaDB cluster and the SQL system. It included both non-expiring data that needed to be “kept forever” for contractual reasons (such as fuel consumption) as well as data that had the exact same schema, but had a five-month TTL expiration. “Each table was exactly the same minus the partitioning clause, and the primary key and other ordering constraints so you could get the data back to support the queries.” It also solved various data purging problems.
They partitioned one table using a compound key of account ID and vehicle identification number (VIN). The next table was identical, but partitioned only by account ID. The next was by account ID and category. They had recently added some time series data as well.
“The beauty of that for the developers was we barely had to change our PHP code and golang code. We were just able to add the drivers in and the reporting mechanism worked almost without any changes.”
They audited and validated the reports from ScyllaDB against SAP ASE. Audit reports would expire after five months.
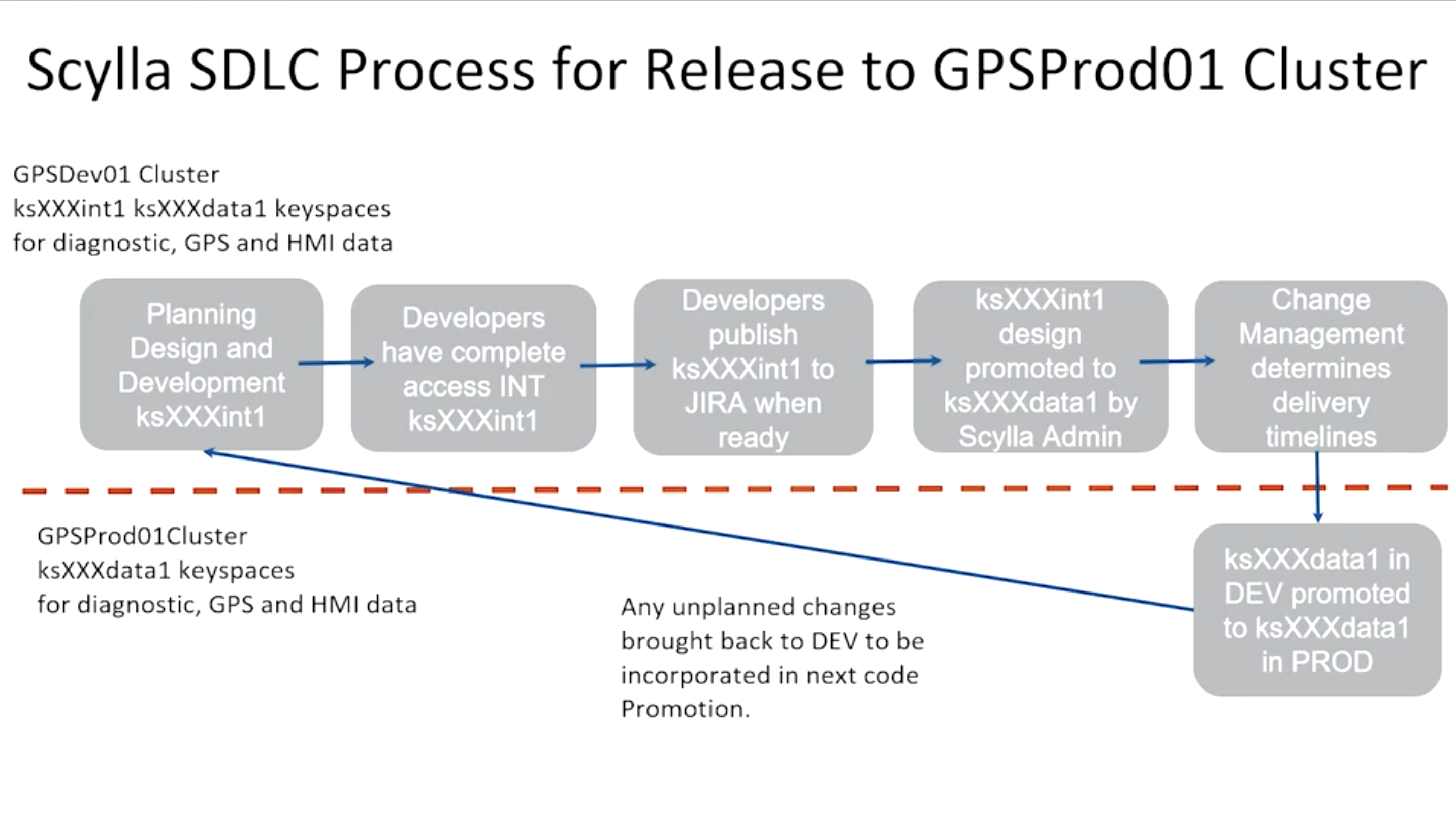
To support the developers, Doug created a three keyspace software development lifecycle environment:
- A dev keyspace, where the developers can do what they wish.
- A keyspace that matches production, to which developers can commit their changes, and Doug can promote to production, and
- A production keyspace, which can take any unplanned changes back to dev.
As a side benefit of offloading the raw data management to ScyllaDB, Doug explained that this approach now allowed the SAP ASE team the ability to upgrade the SQL system since load was nowhere near as large nor uptime so critical as it had been.
“ScyllaDB has allowed GPS Insight an inexpensive and efficient way of offloading machine data from SAP ASE while having even better visibility and performance.”
— Doug Stuns
Want to learn more? Watch the full video below:
If after watching you have any more questions or ideas regarding your own Big Data projects, make sure to join our Slack channel, or contact us directly.