With continued and growing interest in Apache Spark, we had two speakers present at ScyllaDB Summit 2018 on the topic. This is the second of a two-part article. Make sure you read the first part, which covered the talk about ScyllaDB and Spark best practices by ScyllaDB’s Eyal Gutkind. This second installment covers the presentation by Google’s Holden Karau.
Holden Karau is an open source developer advocate at Google. She is an Apache Spark/PMC committer and a co-author of Learning Spark: Lightning-Fast Big Data Analysis and High Performance Spark: Best Practices for Scaling and Optimizing Apache Spark.
In her talk, entitled Building Recoverable (and Optionally Asynchronous) Pipelines in Spark, Holden provided an overview of Spark, how it can fail and, based on those different failures, she outlined a number of strategies for how pipelines can be recovered.
It’s no secret that Spark can fail in hour 23 of a 24-hour job. In her talk, Holden asks the question: “Have you ever had a Spark job fail in its second to last stage after a ‘trivial’ update? Have you been part of the way through debugging a pipeline to wish you could look at its data? Have you ever had an ‘exploratory’ notebook turn into something less exploratory?”
According to Holden, it’s surprisingly simple not only to build recoverable pipelines, but also to make them more debuggable. But the “simple” solution proposed turns out to have hidden flaws. Holden shows how to work around them, and ends with a reminder of how important it is to test your code.
In Holden’s view, there are a few different approaches that you can take towards making recoverable pipelines, each of which is subject to interesting problems.
Holden pointed out that Spark has many different components, with confusing redundancy among them. Many of the components have two copies, such as two different machine learning libraries; an old deprecated one that “sort of works” and a new one that doesn’t work yet, but isn’t deprecated. There are two different streaming engines with three different streaming execution engines. There is also a SQL engine, which, while it may not be cutting-edge, can provide a unified view and help you to work with the SQL lovers in your organization.
The Joy of Out of Memory Errors
Holden used the familiar Spark example, Wordcount.

But, she pointed out, Wordcount is limited. Real-world big data uses cases span ETL, SQL on top of NoSQL, machine learning, and deep learning. Holden’s examples can plug into all of these use cases.
In Holden’s experience, Spark is not only going to fail, it’s usually going to fail late. There are several reasons for this. Lazy evaluation may be cool, but it also means that no errors are thrown until the results are saved out. For example, if the input files don’t exist or the HDFS connection was improperly configured, or if we were querying a database and we didn’t have permissions, we wouldn’t get the out-of-memory errors.
“I mean I write a lot of errors in my code, “ said Holden, “When you change just one small piece, everything runs fine, since you only changed one thing. You deploy to production and then everything fails. The data size is increasing without the required tuning changes. As your database starts to grow, you may need to add more nodes to Spark. If you don’t add those nodes to Spark, it will try really hard to finish your job and then 23 hours later it will fail.”
Another scenario that Holden discussed is type-checking failures that can make Spark ‘catch on fire,’ such as key-skew (or data skew). The goal is to put the fire out and move on.
Why is making a Spark job recoverable so hard? Spark jobs tend to be scheduled on top of a cluster like Kubernetes or YARN. When jobs fail, all of the resources go back to the cluster manager and report failure. For those who use notebooks and persistent clusters like Apache Livy that’s not quite the case; you can have your Spark context and cluster resources still hanging around, which lets you recover a bit easily, but there are still downsides.
Building a “Recoverable” Wordcount
Holden provided a first take for an updated wordcount example that supports recovery:

A “Recoverable” Wordcount
In this example, if the file exists we load it, but we don’t compute our word count. Instead we will return the raw computation, which allows a place to checkpoint. If things go wrong, the code can run again and return to that checkpoint.
This doesn’t fix everything, however. If a job fails in a ‘weird’ way, the files will exist but they’ll be in a bad state, meaning that you need to check to make sure that things are actually in a good state. If the entire job succeeded, temporary recovery points may be sitting in persistent storage and need to be cleaned up. Another problem is that it’s not async, so it will block while saving. We could do something smarter, like using functions so that we have general-purpose code.
In a second example Holden showed how we could also do this a little bit differently to check for Spark’s success marker.

“Recoverable” Wordcount 2
Checking the success marker helps, but it also has limitations. For example, cleaning up on success is a bit complicated. We have to wait to finish writing out files which will slow the pipeline down to make it recoverable, when one reason we wanted to make our pipeline recoverable is that it was kind of slow. We want to minimize the impact of making it recoverable.
Holden then showed a third take on the same problem. This version checks for the two different kinds of success files, takes in data frames and checks that the success exists. If they do, we load it and return that we’re reusing it. Otherwise we save it and return the default data frame . If you know Spark you may realize that there’s some sad problems with this solution.

“Recoverable” Wordcount, 3rd try
Problems Making a “Happy Path”
We have two options: make the “happy path” (as Holden dubbed it) async or clean up on success. To make the saving async instead of calling save, you can use a non-blocking DataFrame save, where we kick a thread, save it back. According to Holden, “That’s kind of not great.” If we were working in the JVM, we would have proper async methods, but we don’t. Instead we can just use use Python threads here and and kick off our save, as follows:

Adding async
But this may break things. Now we need to examine the internals of Spark to understand why making this code async doesn’t just solve the problem.
Spark’s Core Magic: The DAG
In Spark, most work is done by transformations. At Spark’s core, what we ask it to do only happens when we finally force it to do so. When we do, it constructs a directed acyclic graph (DAG). Spark doesn’t perform them; it merely makes a note that it needs to do it. The problem is that, in Spark, the data doesn’t really exist until it absolutely has to.
Transformations return new RDDs or DataFrames representing the data. Those turn out to be just ‘plans’ that are executed when we command Spark to do so. While it looks like we’re saving a dataset that exists, it actually doesn’t exist until we call save. It also goes away right after we call save.
That’s unfortunate because it requires data to exist twice. But even if we make it exist twice there’s still a slight problem; the directed acyclic graph (DAG). While a DAG could be a simple sequence, it could also be a more complex job with multiple pieces coming together. When using DataFrames, the result is a query plan, which is similar to the DAG, but more difficult to read and contains things like code generation.
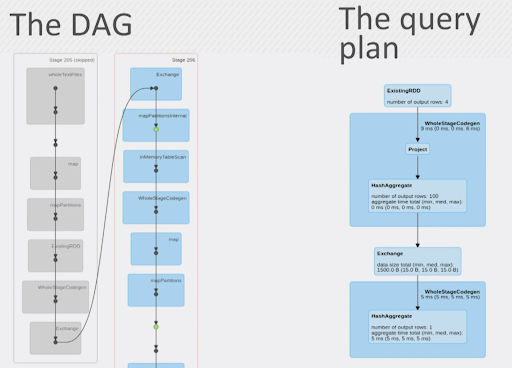
Example of the difference between a Directed Acyclic Graph (DAG) on the left and a DataFrame query plan on the right
So what’s gonna go boom? We cache the result and then we call count and do a non-blocking DataFrame save and return the DataFrame. This sort of fixes the problem to a degree.

A recoverable pipeline using cache, sync count, and async save
If Spark gets two requests for the same for the same piece of data, Spark isn’t ‘smart’ enough to realize that two different people want the same thing; it just computes the same result twice. But if you’re processing, you are probably doing your recoverable part on the expensive part of your pipeline.
“That’s fine for me, since I work at a cloud company, and we sell compute resources. But that might not be fine to your boss.”
By forcing this cache and count, we tell Spark we want to use the data twice, which should make it exist in memory (and keep it around). Spark should save and then return the result without blocking on the save, since the data already exists and the save can read out of memory. You don’t have to worry about the fact that we might ask it for a second time. Spark will just go back and read that same block of memory. The fact that we’re reading that same memory to write out is fine; you’re not duplicating an expensive operation. Instead, we have an inexpensive operation happening twice, which may not be ideal but which works well enough. There are some minor downsides, but we now have a recoverable pipeline.
You probably only need a recoverable pipeline where have complicated business logic, a service hitting an expensive API server. Don’t make everything recoverable, just do it on the parts that matter.
As a final note, Holden pointed out that one problem is that you need a concept of job IDs. Spark has a built-in understanding of what a job ID is, but it’s better to use your own to give you control. For example, if you want to run two different backfills, you don’t want them recovering from each other part of the way through. Instead, you want them to run separately. You can do that by giving them different job IDs, so they don’t interfere with each other’s data.
Register Now for ScyllaDB Summit 2019!
If you enjoyed technical insights from industry leaders, and want to learn more about how to get the most out of ScyllaDB and your big data infrastructure, sign up for ScyllaDB Summit 2019, coming up this November 5-6, 2019 in San Francisco, California.