Derek Ramsey, Software Engineering Manager at Sensaphone, gave an overview of ValuStor at ScyllaDB Summit 2018. Sensaphone is a maker of remote monitoring solutions for the Industrial Internet of Things (IIoT). Their products are designed to watch over your physical plant and equipment — such as HVAC systems, oil and gas infrastructure, livestock facilities, greenhouses, food, beverage and medical cold storage. Yet there is a lot of software behind the hardware of IIoT. ValuStor is an example of ostensible “hardware guys” teaching the software guys a thing or two.
Overview and Origins of ValuStor
![]() Derek began his ScyllaDB Summit talk with an overview: what is ValuStor? It is a NoSQL memory cache and a persistent database utilizing a ScyllaDB back-end, designed for key-value and document store data models. It was implemented as a single header-only database abstraction layer and comprises three components: the ScyllaDB database, a ValuStor Client and Cassandra driver (which ScyllaDB can use since it is CQL-compliant).
Derek began his ScyllaDB Summit talk with an overview: what is ValuStor? It is a NoSQL memory cache and a persistent database utilizing a ScyllaDB back-end, designed for key-value and document store data models. It was implemented as a single header-only database abstraction layer and comprises three components: the ScyllaDB database, a ValuStor Client and Cassandra driver (which ScyllaDB can use since it is CQL-compliant).
ValuStor is released as free open source under the MIT license. The MIT license is extremely permissive, allowing anyone to “use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the software.” Which means that you can bake it into your own software, services and infrastructure freely and without reservation.
Derek then went back a bit into history to describe how Sensaphone began down this path. What circumstances gave rise to the origins of ValuStor? It all started when Sensaphone launched a single-node MySQL database. As their system scaled to hundreds of simultaneous connections, they added memcached to help offload their disk write load on the backend database. Even so, they kept scaling, and their system was insufficient to handle the growing load. It wasn’t the MySQL database that was the issue. It was memcached that was unable to handle all the requests.
For the short term, they began by batching requests. Yet Sensaphone needed to address the fundamental architectural issues, including the need for redundancy and scalability. There was also a cold cache performance risk (also known as the “thundering herd” problem) if they ever needed to restart.
No one in big data takes the decision to replace infrastructure lightly. Yet when they did the cutover it was surprisingly quick. It took only three days from inception to get ScyllaDB running in production. And, as of last November, Sensaphone had already been in production for a year.
Since its initial implementation, Sensaphone added two additional use cases: managing web sessions, and for a distributed message queuing fan out for a producer/consumer application (a publish-subscribe design pattern akin to an in-house RabbitMQ or ActiveMQ). Derek recommended that anyone interested check out the published Usage Guide on GitHub.
Comparisons to memcached
Derek made a fair but firm assessment of the limitations of memcached for Sensaphone’s environment. First he cited the memcached FAQ itself, where it says it is not recommended for sessions, since if the cache is ever lost you may lock users off your site. While the PHP manual had a section on sessions in memcached, there is simply no guarantee of survivability of user data.
Second, Derek cited the minimal security implementation (e.g., SASL authentication). There has been a significant amplification of attacks on memcached in recent years (such as DDoS attacks), and while there are ways to minimize risks, there is no substitution for built-in end-to-end encryption.
Derek listed the basic, fundamental architectural limitations: “it has no encryption, no failover, no replication, and no persistence. Of course it has no persistence — it’s a RAM cache.” That latter point, while usually a feature for performance in memcached’s favor, was exactly what leads to the cold cache problem when your server inevitably crashes or has to be restarted.
Sensaphone was resorting to use batching to maintain a semblance of performance, whereas batch is an antipattern for ScyllaDB.
ValuStor: How does it work?
ValuStor Client
Derek described client design, which kept ease-of-use first and foremost. There are only two API functions: get and store. (Deletes are not done directly, Instead, setting a time-to-live — TTL — of 1 second on data is effectively a delete.)
Implemented as an abstraction layer means you can use your data in a native programming language with native data types: integers, floating point, strings, JSON, blobs, bytes, and UUIDs.
For fault tolerance, ValuStor also added a client-side write queue for a backlog function, and automatic adaptive consistency (more on this later).
Cassandra Driver
The Cassandra driver supports thread safety and is multi-threaded. “Practically speaking, that means you can throw requests at it and it will automatically scale to use more CPU resources as required and you don’t need to do any special locking,” Derek explained. “Unlike memcached… [where] the C driver is not thread-safe.”
ValuStor also offers connection control, so if a ScyllaDB node goes down it will automatically re-establish the connection with a different node. It is also datacenter-aware and will choose your datacenters intelligently.
ScyllaDB Database Server
The ScyllaDB server at the heart of ValuStor offers various architectural advantages. “First and foremost is performance. With the obvious question, ‘How in the world can a persistent database compete with RAM-only caching?’”
Derek then described how ScyllaDB offers its own async and userspace I/O schedulers. Such architectural features can, at times, result in ScyllaDB responsiveness with sub-millisecond latencies.
ScyllaDB also has its own cache and separate memtable, which acts as a sort of cache. “In our use case at Sensaphone we have 100% cache hits all the time. We never have to hit the disk, even though it has one, and since our database has never actually gone down we’ve never actually even had to load it from disk except for maintenance periods.”
In terms of cache warming, Derek provided some advice, “The cold cache penalty is actually less severe for ScyllaDB if you use heat-weighted load balancing because ScyllaDB will automatically warm up your cache for you for the nodes you restart.”
Derek then turned to the issues of security. His criticisms were sobering: “Memcached is what I call ‘vulnerable by design.’” In the latest major issue, “their solution was simply to disable UDP by default rather than fix the problem.”
“By contrast, ValuStor comes with complete TLS support right out of the box.” That includes client authentication and server certified verification by domain or IP, over-the-wire encryption within and across datacenters, and of course basic password authentication and access control. You can read more about TLS setup in the ValuStor documentation.
“Inevitably, though, the database is going to go offline from the client perspective. Either you have network outage or you’ll have hardware issues on your database server.” Derek then dove down into a key additional feature for fault tolerance: a client-side write queue on the producer side. It buffers up and performs automatic retries. When the database is back up, it clears its backlog. The client keeps the requests serialized, so that data is not written in the wrong order. “Producers keep on producing and your writes are simply delayed. They aren’t lost.”
Derek then noted “ScyllaDB has great redundancy. You can set your custom data replication factor per keyspace. It can be changed on the fly. And the client driver is aware of this and will route your traffic to the nodes that actually have your data.” You can also set different replication factors per datacenter, and the client is also aware of your multi-datacenter topology.
In terms of availability, Derek reminded the audience of the CAP theorem, “it states you can have Consistency, Availability or Partition tolerance. Pick any two.” This leads to the quorum problem (where you require n/2 + 1 nodes being available), which can lead to fragility issues in multi-datacenter deployments.
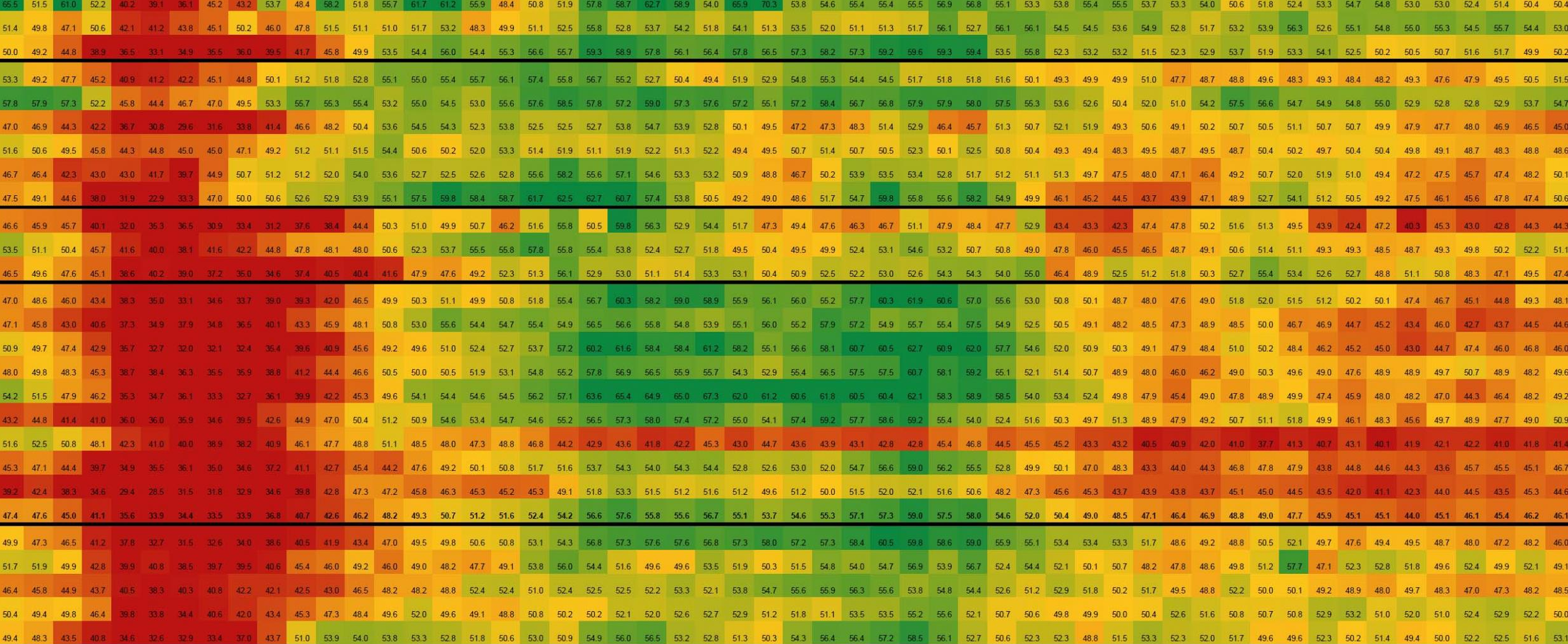
To illustrate, Derek showed the following series of graphics:

Let’s say you have a primary datacenter with three nodes, and a secondary datacenter with two nodes. The outage of any two nodes will not cause a problem in quorum.

However, if your primary datacenter goes offline, your secondary datacenter would not work if it required a strict adherence to quorum being set at n/2 +1.

In a second example Derek put forth, if you had a primary with three nodes, and two secondary sites, then if your primary site went down, you could still keep operating if the primary site went offline, since there would still be four nodes, which meets the n/2 + 1 requirement.

However, if both of your secondary datacenters went offline, Derek observed this failure would have the unfortunate effect of bringing your primary datacenter down with it, even if there was nothing wrong with your main cluster.
“The solution to this problem is automatic adaptive consistency. This is done on the client side.” Since ScyllaDB is an eventually consistent database with tunable consistency, this buys ValuStor “the ability to adaptively downgrade the consistency on a retry of the requests.” This dramatically reduces the issues of likelihood of inconsistency. It also works well with Hinted Handoffs, which further reduces problems when individual nodes go offline.
Derek took the audience on a brief refresher on consistency levels, including ALL, QUORUM, and ONE/ANY. You can learn more about these reading the ScyllaDB documentation and even teach yourself more going through our console demo.
Next, Derek covered the scalability of ScyllaDB. “The ScyllaDB architecture itself is nearly infinitely scalable. Due to the shard-per-core design you can keep throwing new cores and new machines at it and it’s perfectly happy to scale up. With the driver shard-aware, it will automatically route traffic to the appropriate location.” This is contrasted with memcached, which requires manual sharding. “This is not ideal.”
Using ValuStor
Configuring ValuStor is accomplished in a C++ template class. Once you’ve created the table in the database, you don’t even need to write any other CQL queries.

This is an example of a minimal configuration. There are more options for SSL.

Here is an example of taking a key-value and storing it, checking to see if the operation was successful, performing automatic retries if it did not, and handling errors if the operation still fails.
Comparisons

When designing ValuStor Derek emphasized, “We wanted all of the things on the left-hand side. In evaluating some of the alternatives, none of them really met our needs.”
In particular, Derek took a look at the complexity of Redis. It has dozens of commands. It has master-slave replication. And for Derek’s bottom line, it’s not going to perform as well as ScyllaDB. He cited the recent change in licensing to Commons Clause, which has caused some confusion and consternation in the market. He also pointed out that if you do need the complexity of Redis, you can move to Pedis, which uses the Seastar engine at its heart for better performance.

Derek also made comparisons to MongoDB and CouchDB, since ValuStor has full native JSON support and can also be used as a document store. “It’s not as full-featured, but depending on your needs, it might actually be a good solution.” He cited how Mongo also recently went through a widely-discussed licensing change (which we covered in a detailed blog).

Derek Ramsey at ScyllaDB Summit 2018
What’s Next for ValuStor
Derek finished by outlining the feature roadmap for ValuStor.
- SWIG bindings will allow it to connect to a wide variety of languages
- Improvements to the command line will allow scripts to use ValuStor
- Expose underlying Futures, to process multiple requests from a single thread for better performance, and lastly,
- A non-template configuration option
To learn more, you can watch Derek’s presentation below, check out Derek’s slides, or peruse the ValuStor repository on Github.