




What is a User Defined Type? (UDT)?
User Defined Types (UDTs) allow a definition of struct that includes multiple typed named fields (including other UDTs). Once a UDT is defined, it can be used as a column type in a table definition. In ScyllaDB, you can define a Column as a frozen<UDT>.
One of the hidden advantages of using UDTs is better performance. The example in this blog post will show that you can get more than a 225% increase in write throughput, 150% increase in read throughput, and ~35% better (lower) 99.9% latency in read. To understand why you can get better performance, let’s review what CQL allows for each Column/Cell in a Row:
- Insert/Update each Cell independently
- Delete each Cell independently
- Set a different TTL for each Cell (CQL: INSERT INTO … USING TTL X; )
- Set a different Writetime for each Cell (CQL: INSERT INTO… USING WRITETIME X;)
When a Column is defined as of type frozen, the Cell stored UDT fields share the same metadata (same TTL, Writetime).
So how much does it matter? Let’s test it out!
In the tests we compared the following:
- “Regular Columns” table with X columns of blob type. The schema for a 10 column regular table tested:
- “User Defined Types” table with a single column using a UDT of X fields of blob type. The schema for a table with a 10 column UDT field tested:
The tests were run multiple times with an increasing number of columns vs fields:
- The selected X values 10,20,30,40,50 (e.g in the last case, a table with 50 blob columns was compared to a table with a UDT table of 50 blob fields)
- In the write tests, all blob fields/columns have been set with 10-byte values
- In the read case, all blob fields/columns have been retrieved
- All tests were run with ScyllaDB 2.0.0
Test 1: Write Throughput
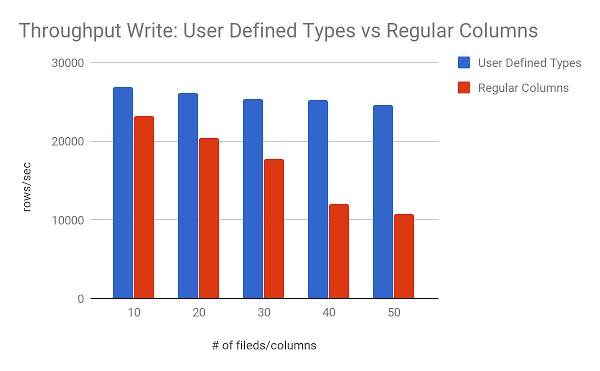
| # of fields/columns | 10 | 20 | 30 | 40 | 50 |
| User Defined Types | 26870.19698 | 26151.79679 | 25352.78645 | 25179.01465 | 24562.727 |
| Regular Columns | 23161.82146 | 20403.72706 | 17759.65957 | 11979.37982 | 10738.29647 |
| Gain | 116.01% | 128.17% | 142.75% | 210.19% | 228.74% |
Test 2: Read Throughput

| # of fields/columns | 10 | 20 | 30 | 40 | 50 |
| User Defined Types | 21924.22546 | 21858.83075 | 20520.39159 | 20827.56757 | 20448.30044 |
| Regular Columns | 20114.99601 | 17521.71543 | 16212.19758 | 13664.00421 | 12595.18025 |
| Gain | 108.99% | 124.75% | 126.57% | 152.43% | 162.35% |
Test 3: Read Latency

| # of fields/columns | 10 | 20 | 30 | 40 | 50 |
| User Defined Types | 1.08134 | 1.01581 | 1.08134 | 1.24518 | 1.14688 |
| Regular Columns | 1.14688 | 1.27795 | 1.34349 | 1.57286 | 1.76947 |
| Gain | 5.71% | 20.51% | 19.51% | 20.83% | 35.19% |
With regard to reads, there are two things worth mentioning:
- In CQL, you can return a subset of some UDT fields so there is no need to return all of the fields.
- The gains results shown above would not have changed significantly if a single column/field had been selected instead of all columns/fields that were requested in the test. ScyllaDB’s cache is a data row cache—when a query is run to return part of a row ScyllaDB will search for the complete row and insert that into the cache and only then create the query result.
Please note:
- UDTs require additional processing on the client side (serialize/deserialize the structure)
- Very limited test results show that not all drivers support UDTs as best as they can:
- The tests above have been done using GoCQL driver—which seems to work well. You can find the scylla-bench fork with extensions for these tests here.
- Previous tests with the Java driver were not as shiny.
To conclude, if you care about performance, consider using UDTs. ScyllaDB currently does not support updating a subset of the fields – the enhancement is enqueued for a future release (vote for it if your use case may need it).
This a recap of an Ignite Talk I gave at ScyllaDB Summit 2017 – you can find a recording of the talk and the slides on our Techtalk page.



