





Today’s article highlights the reasons why Zeotap moved their workload to ScyllaDB after trying a few other technologies first. It is drawn from a talk given at ScyllaDB Summit 2022 earlier this year. Note that you can watch all of the talks from that virtual event for free.
Zeotap’s Mission
Zeotap is a customer intelligence platform, also known as a Customer Data Platform (CDP) focusing on the needs of European marketers. It helps brands better understand their customers and predict behavior. Founded in Germany in 2014, as a third party data aggregation platform it evolved into a next-generation CDP. Their mission is to give a 360º view to their customers, allowing them to branch data and make better marketing decisions. To enable their rapid growth Zeotap built their brand on Google Cloud.
Zeotap rose quickly to the front ranks of the digital marketing industry, advancing the state-of-the-art through innovation while still meeting the stringent privacy compliance requirements for operating in the European Union. For example, Zeotap announced General Data Protection Regulation (GDPR) compliance in July 2016 — nearly two full years ahead of the mandatory May 2018 compliance date.
Another emerging aspect of privacy compliance is eliminating the currently near-ubiquitous 3rd party cookies that watch users as they traverse within sites and browse from site-to-site. Since HTTP cookies first debuted in 1994 at Netscape, an entire generation of technologists and companies have come to rely upon them for user identification and behavior attribution.
This time around the compliance requirement was not driven by government-mandated regulation but by industry fiat. Since Google’s Chrome browser accounts for the great majority of web clients — somewhere between 62% to 65% of detectable browser usage — the company can effectively dictate policy.
Google first announced in January 2020 it would phase out supporting third-party cookies by the start of 2022. However, this sent a panic through the tech industry. Many business models were based upon cookies and dependent on their implementation. Late in 2021, Google pushed out the deadline for compliance to mid-to-late 2023. Yet this was only a relatively brief reprieve which still has many companies scrambling.
Zeotap Leads the Way
Facing a world with a cookieless future, Zeotap tapped into its innovative spirit, once again pioneering how to implement compliant systems. At ScyllaDB Summit 2022 we had the pleasure of hosting Shubham Patil and Safal Pandita, two engineers from Zeotap who explained how their cookieless CDP system was implemented in their talk Building Zeotap’s Privacy Compliant Customer Data Platform (CDP) with ScyllaDB.
Shubham noted, “Today’s customer journeys are more complex than ever.” For example, a user might stumble across a company’s social media post which directs them to a blog, and then finally lands them on the e-commerce site. “With such unpredictable journeys, how can the business keep track of their customers?” Shubham asked, “and how can they deliver personalized experiences across an ever-expanding set of touch points?”
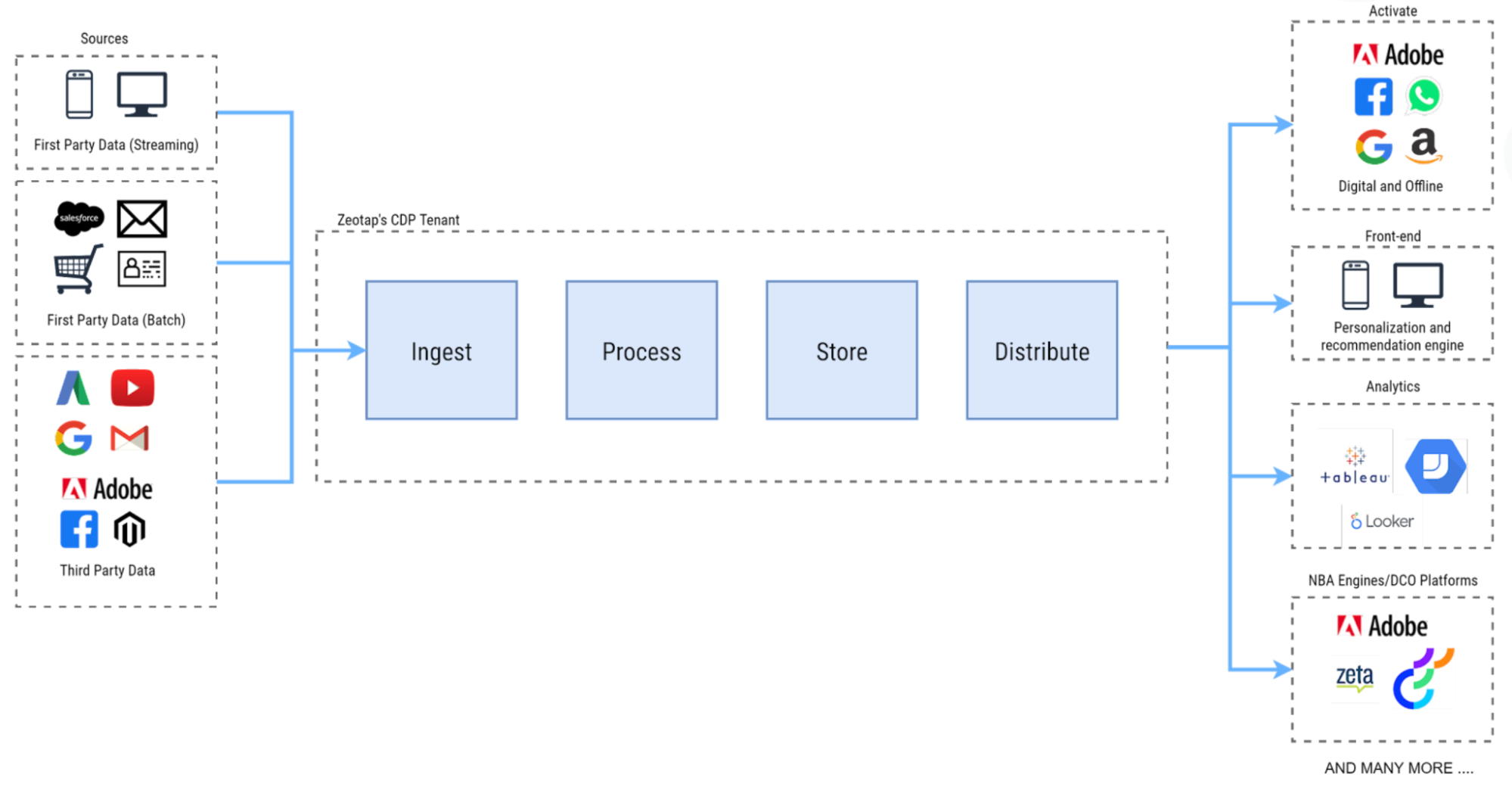
This is where the Customer Data Platform comes in. It defines unique users, and aggregates information related to those users’ detected online and offline activities. This means ingesting, processing, storing and distributing correlated data from hundreds of consented-to data sources. These can be first, second, or third party sources. For example, it could come from your Customer Relationship Management (CRM) platform, an adtech Data Management Platform (DMP), or your data lake or data warehouse. Or it could be a mobile application today, or an IoT-enabled device in the future.
This aggregated data is made into what are called “golden records.” These golden records which can then be segmented into target audiences, have Machine Learning (ML) algorithms run against them, and then be utilized, for example, in a paid social media advertising campaign.
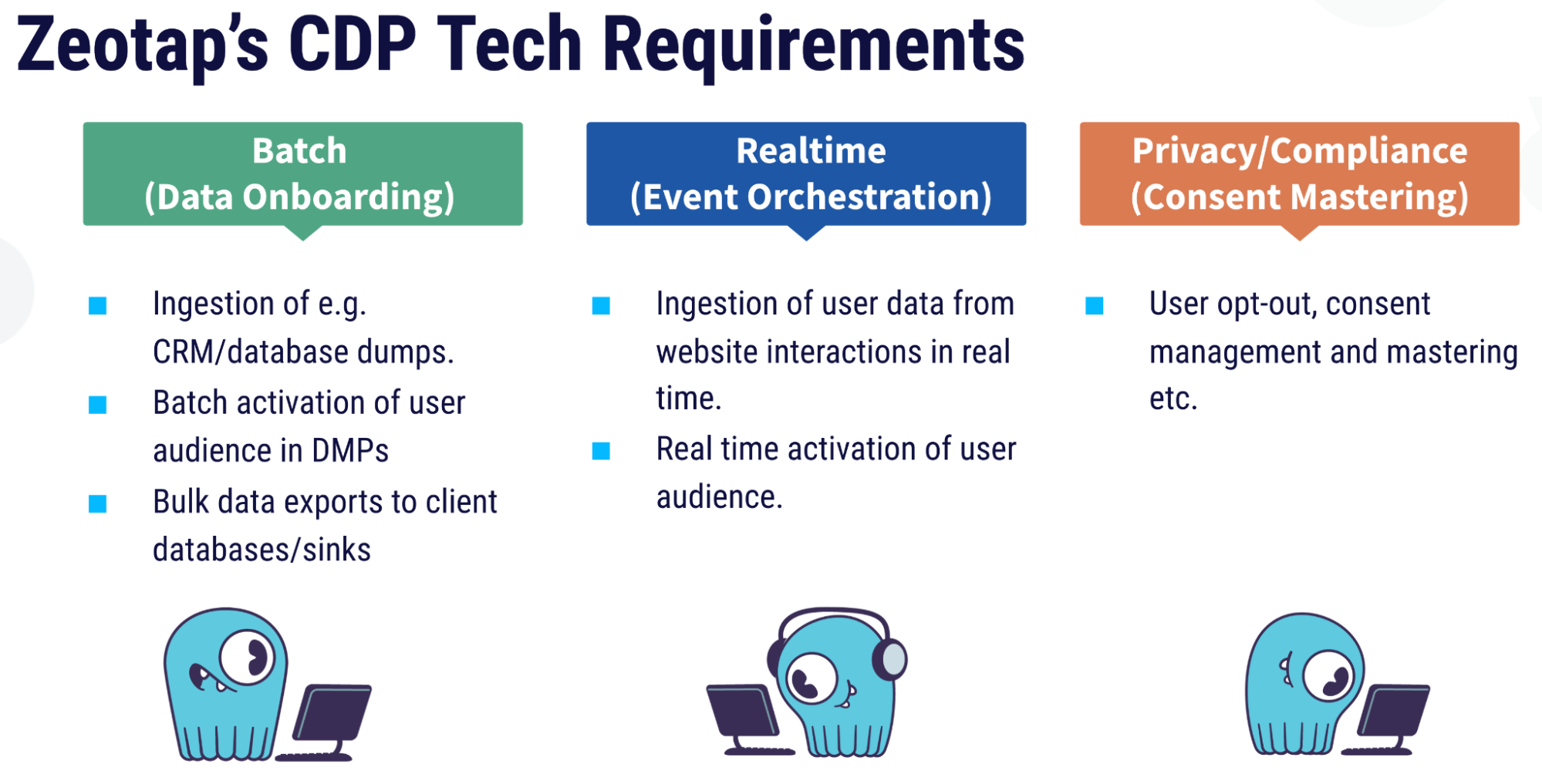
This data could come from bulk data batch processing, or real time event streaming. These weren’t just for ingestion, but also for data export. Beyond that, the database also needed to support strong privacy compliance measures, including user opt-outs and explicit consent management systems.
Zeotap had a list of other technical requirements as well, including:
- Multi-region, multi-tenant
- Low-latency (sub-second) real-time reads and writes
- Point lookups
- Scalable from megabytes to petabytes
- Mature monitoring stack
- Spark integration support
- Control of cluster sizing
- Encryption-at-rest
- Control of data model
- Simple SQL-like query
- Enterprise support
Fortunately, ScyllaDB met each of these requirements. Whereas their original system, based on Google BigQuery and detailed below, could not even provide sub-second query response, with ScyllaDB their responses were measurable in milliseconds.
First Version
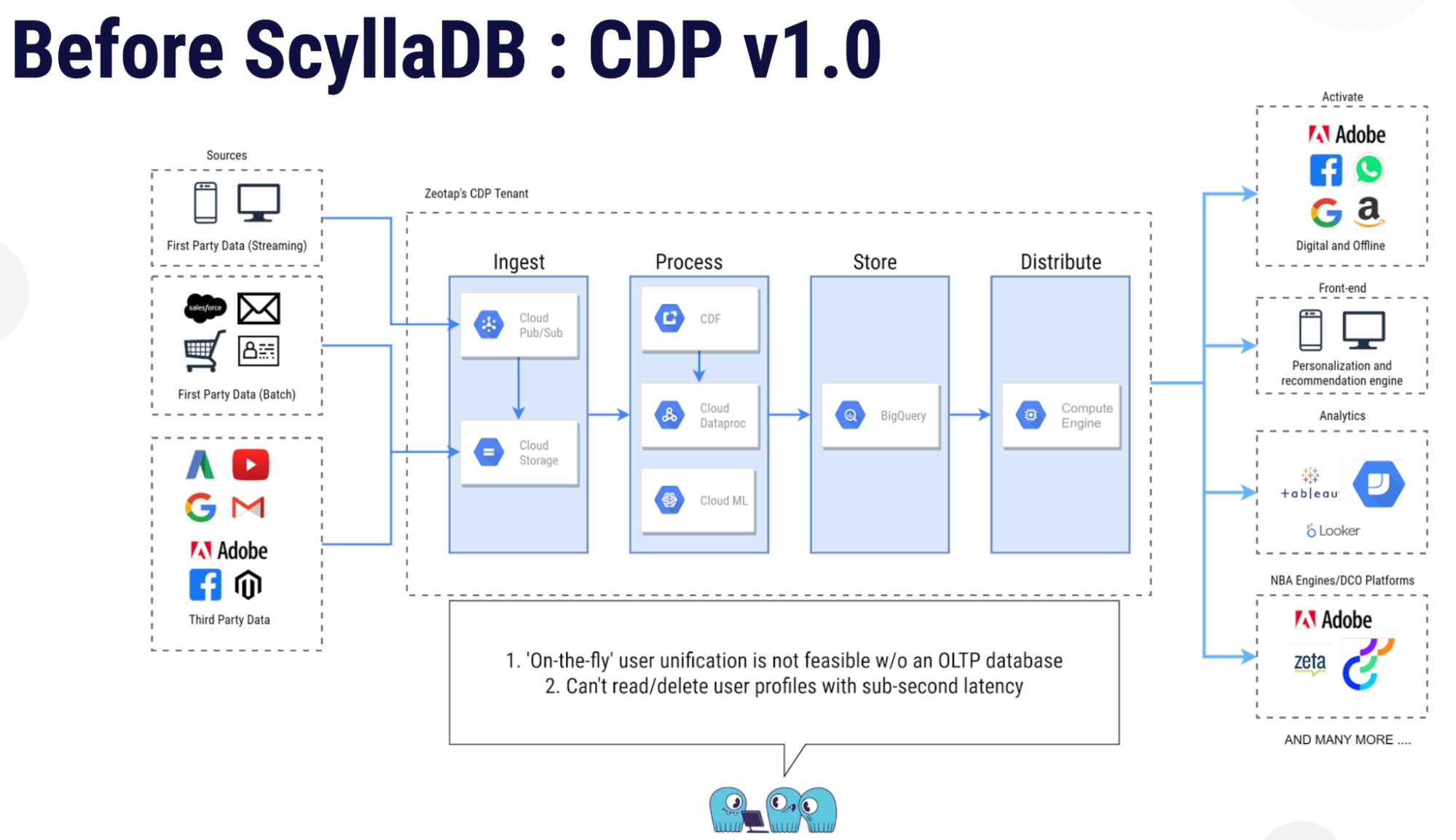
Zeotap implemented the first version of their CDP with very simplified goals using Google BigQuery for the data store for ingestion of all the client data. But there were some problems with this, Shubham observed. Their business requirements included on-the-fly user unification from data drawn from different sources with sub-second latencies, and this system could not manage that performance threshold. Here’s the scorecard that Zeotap applied to their first implementation.
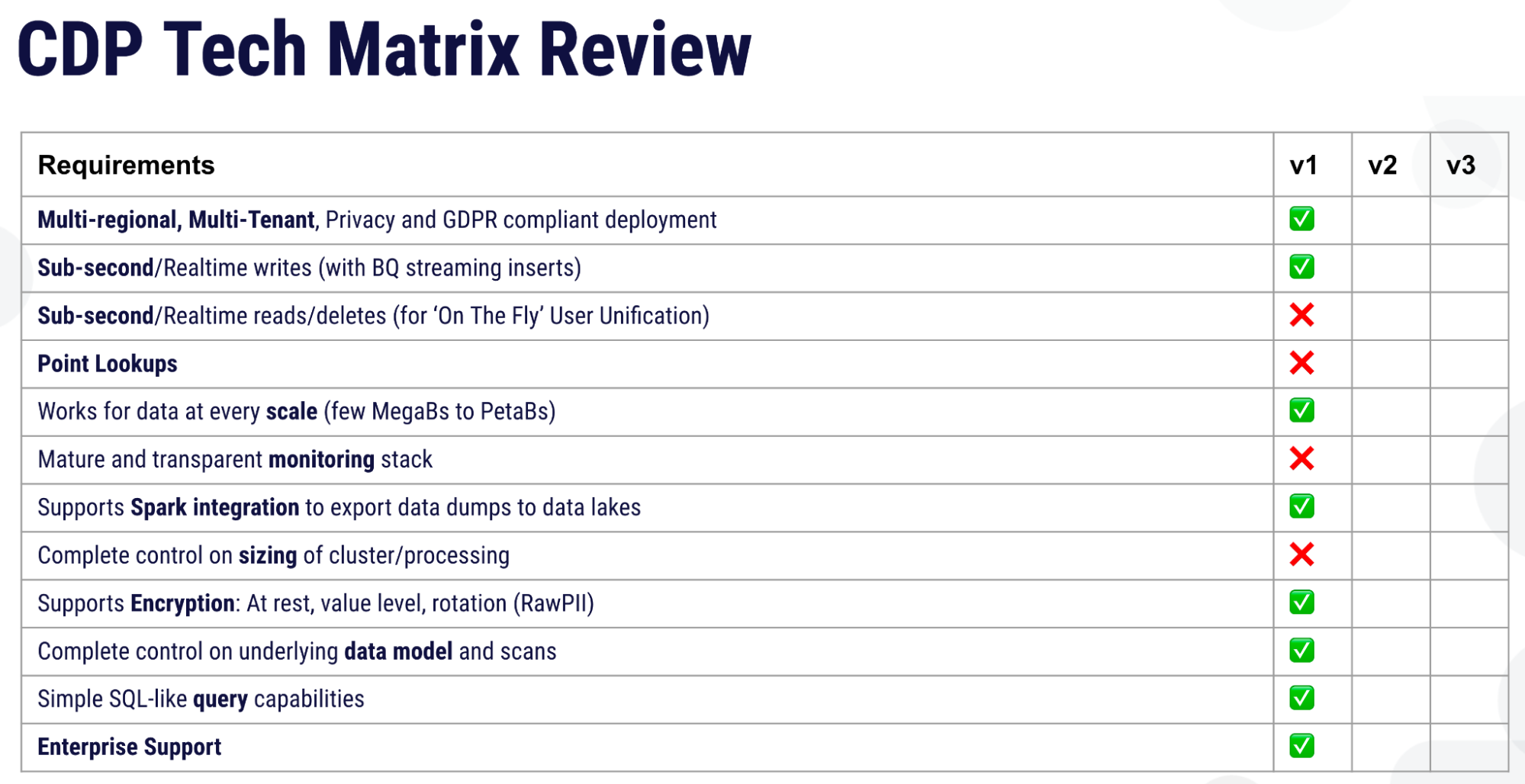
“We needed to do better,” Shubham admitted. “In this version one implementation our sub-second read writes were not possible. Point lookups were not possible. We also did not have a very good monitoring stack and also did not have complete control on sizing of the cluster. So we started exploring wide column OLTP databases.”
Second Version
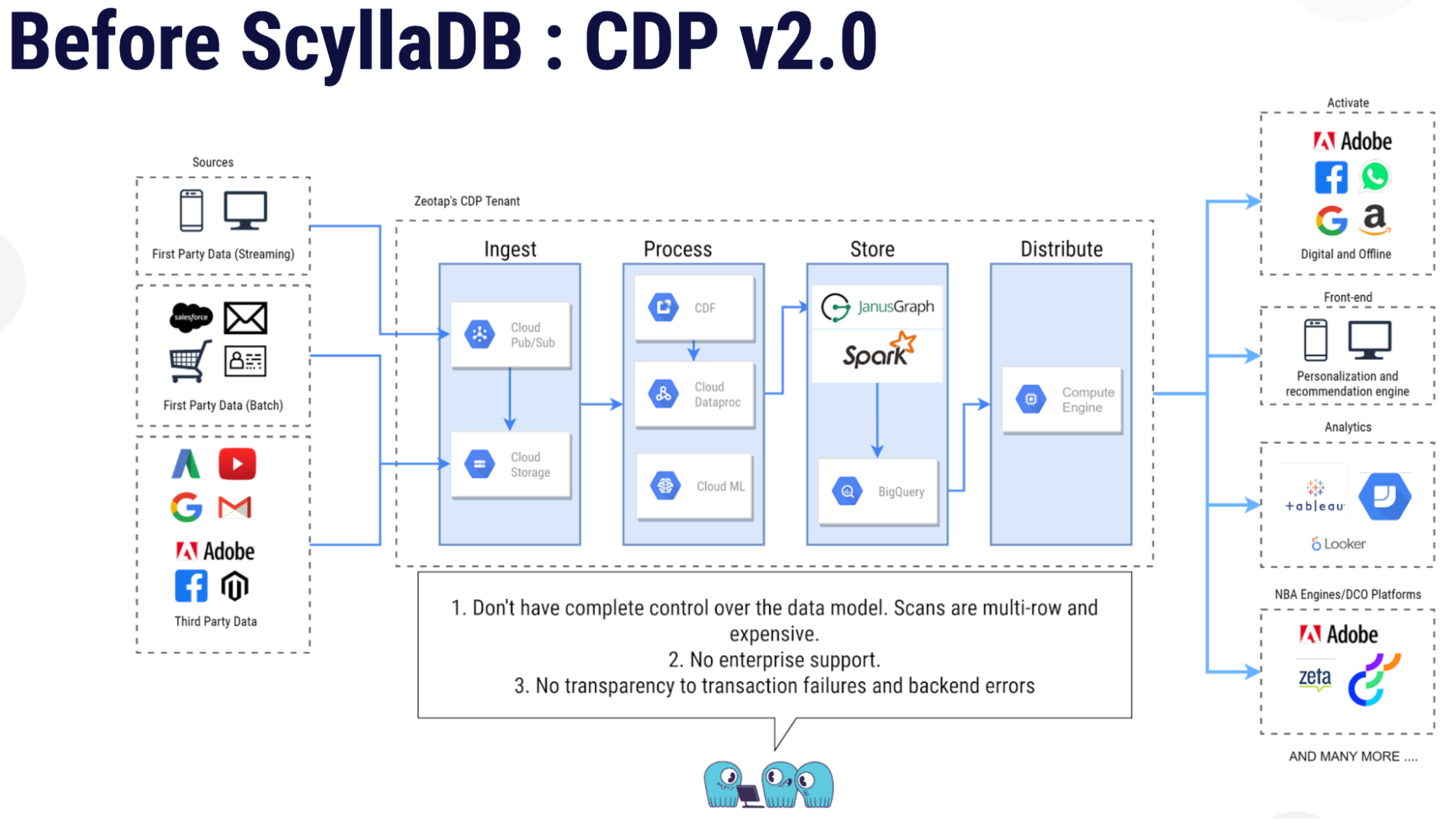
“Our next POC [Proof of Concept] was with JanusGraph using both HBase and ScyllaDB [as backend storage layers]. With this new tech we were able to solve most of our problems but then we also started facing some other issues. Specifically issues where we did not have complete control over the data model, scans were multi-row and expensive, and there was no enterprise support to any of the issues that we were facing. And there was no transparency to the transaction failure and back-end errors.”
After releasing version 2 with JanusGraph this is what their tech matrix looked like:
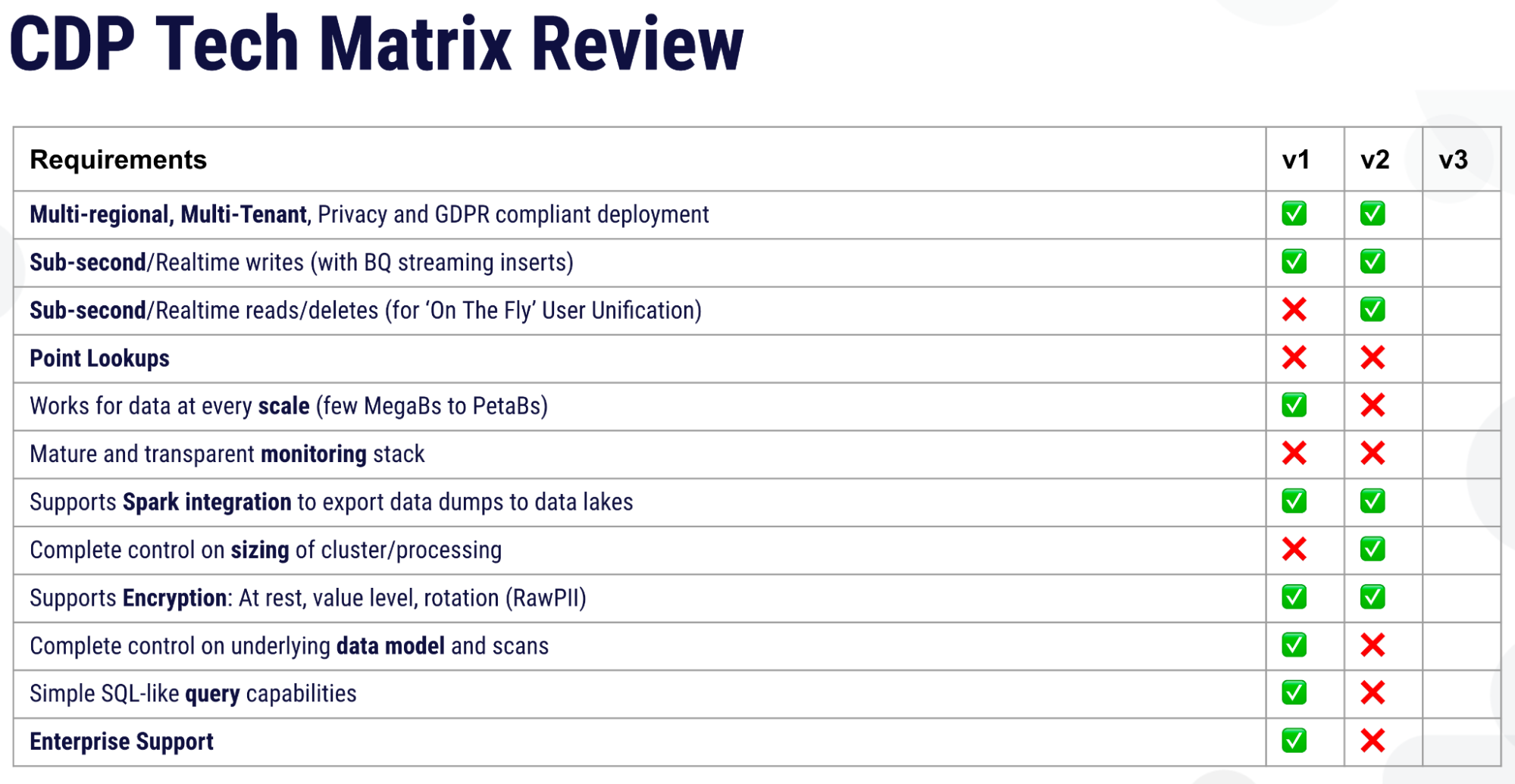
Shubham shared, “Some of the problems like sub-second reads and deletes were actually solved. But the other problems like point lookups and ‘works for data at every scale’ and a matured monitoring stack was still not there. Then again there were some other problems that came into the picture, like we did not have a simple SQL-like query interface and, again, we did not have complete control on the data model.”
JanusGraph uses Gremlin/Tinkerpop as its query language, which can appear quite foreign to developers familiar with SQL. ScyllaDB, on the other hand, uses Cassandra Query Language (CQL), which has a passing similarity to SQL, even though its syntax differs significantly. For example, CQL does not support table JOINs. But it did fit Zeotap’s requirements far better.
Third Version
The Zeotap team decided at that point to use ScyllaDB natively as the storage layer using its CQL interface for queries, and removed the JanusGraph layer on top.
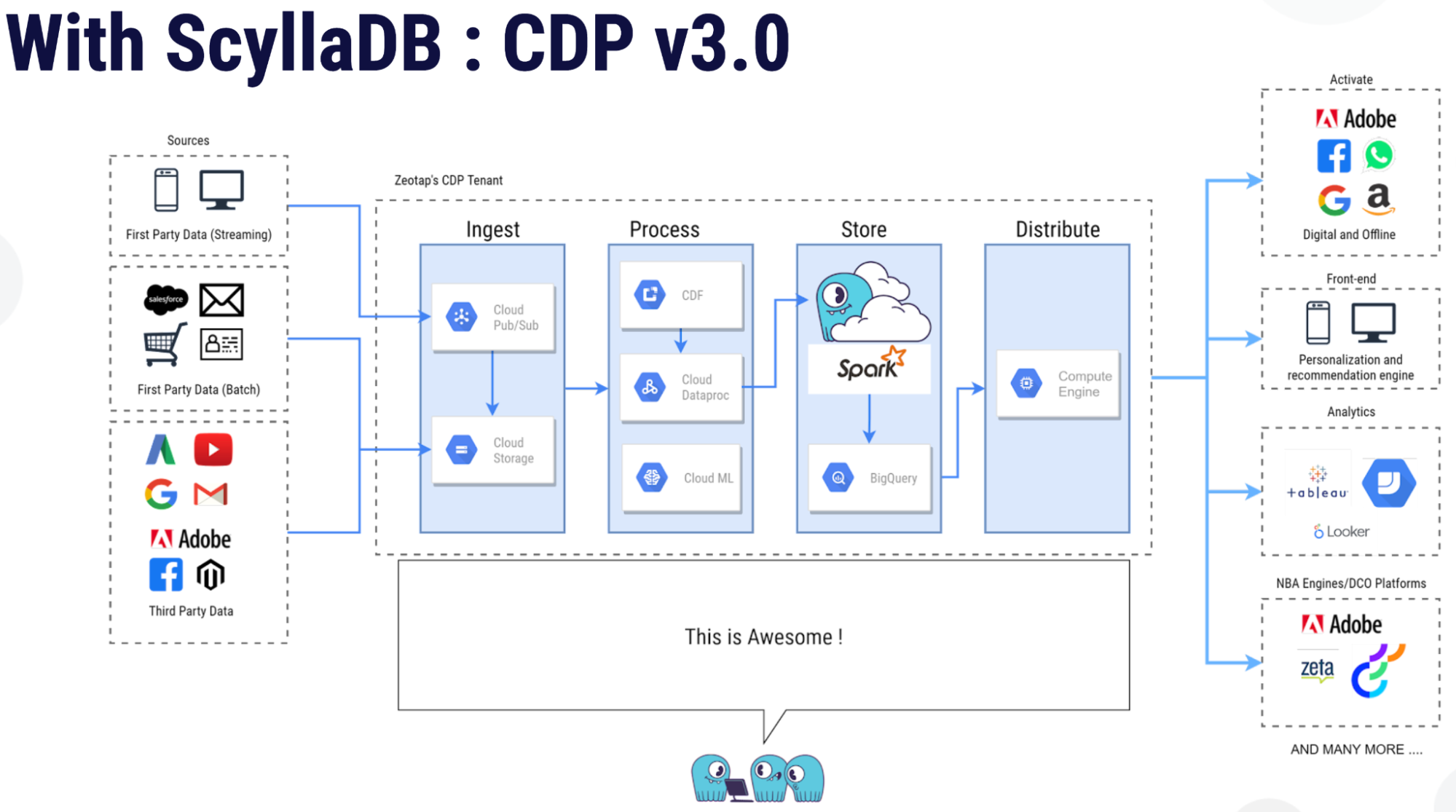
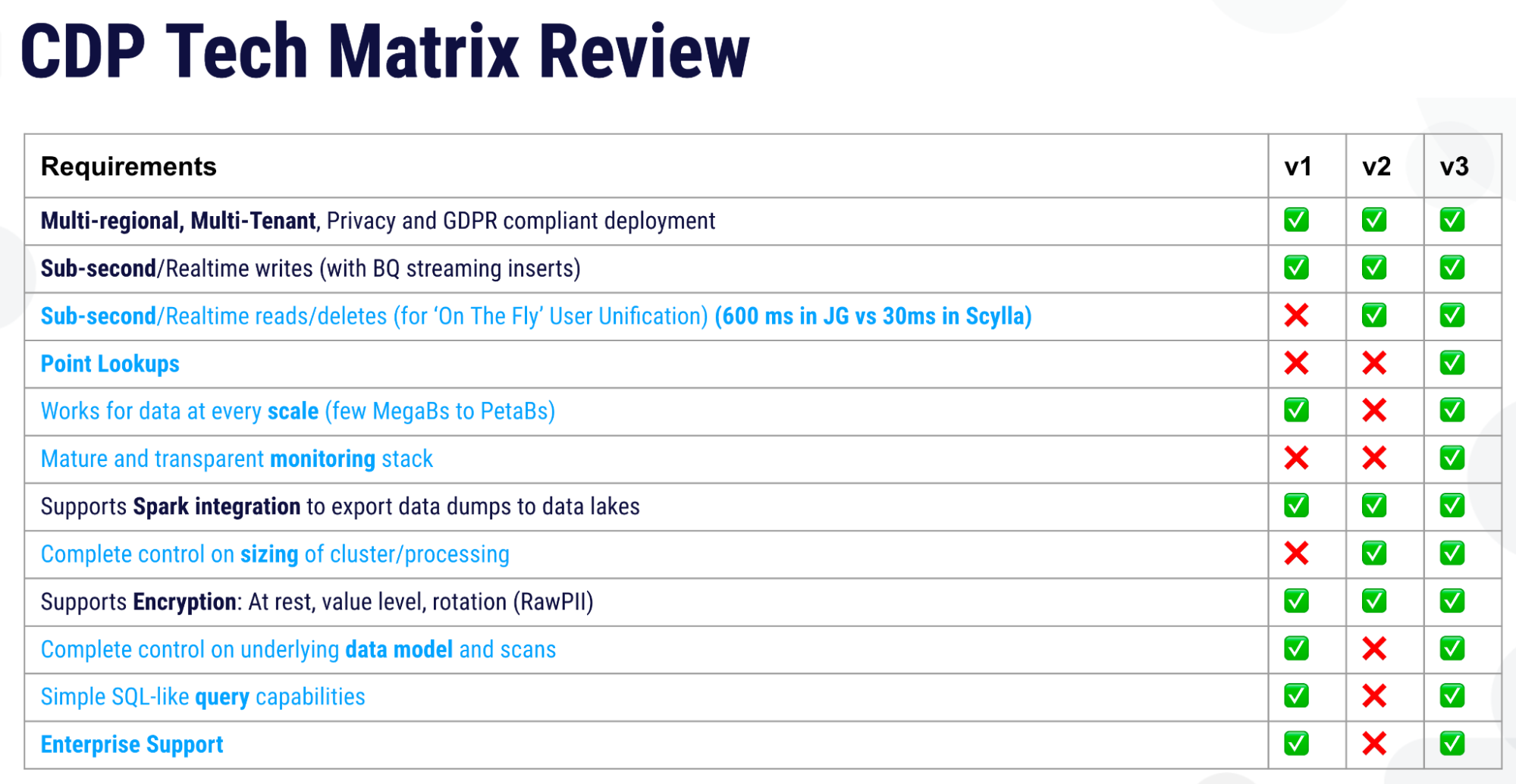
At last all their main technical requirements were met. All the problems faced in their first and second iterations were resolved. Latencies which had gotten down to 600 milliseconds using JanusGraph (nominally acceptable according to Zeotap’s “sub-second” requirement) now dropped far further in ScyllaDB — to only 30 milliseconds.
Plus, Zeotap now had a very mature and transparent observability platform in the form of ScyllaDB Monitoring Stack, which is comprised of open source components like Prometheus and Grafana. ScyllaDB also offered Apache Spark integration. Zeotap now had complete control on sizing of their cluster, their underlying data model, all with enterprise support.
After moving to ScyllaDB, Zeotap’s tech matrix finally looked like this:
Explore How Zeotap Implemented ScyllaDB
Shubham then introduced Senior Software Engineer Safal Pandita, who took the audience through the rest of the presentation describing Zeotap’s implementation of ScyllaDB. You won’t want to miss it! Fortunately, you can watch the entire video on demand.
Learn more about their data model, their queries, the performance optimizations they employed, and details of their operational deployment. Just to give you a sense of Zeotap’s scale, they now run four clusters across continental Europe, the UK, India, and the United States, with each cluster comprising six nodes of n2-highmem-64 instances.
If you have your own use case you have questions about and want to see if ScyllaDB is right for you, feel free to drop in to our Slack user community, or reach out to contact us privately.


