




A story of rewriting cqlsh in Rust…with Claude Code and a lot of planning
Dear cqlsh,
I vouched for you. I told the team you were fine. I forked you, catered to you, vendored your dependencies and your dependencies’ dependencies. I patched things upstream that I knew you would never merge. I pinned your Python, re-pinned it after the OS upgraded, and explained to people (with a straight face) why that was totally normal and not a problem at all.
I wrote you twice already. You never wrote back.
I’m not even mad. I get it: you’re busy. 30+ CLI flags, 25 CQL types, a COPY engine with enough options to fill a man page…You’ve got a lot going on.
But I found someone faster, someone who compiles to a static binary without a runtime, without vendoring. They don’t make me think about “which Python are we using today?” They just…work.
I hope you understand.
Yours (for now),
Israel
This is the story of cqlsh-rs – a ground-up Rust rewrite of the Python cqlsh, the interactive CQL shell used daily by everyone working with Cassandra and ScyllaDB. It’s also a story about what happens when you take the lessons from one AI-assisted project and apply them to another project.
Why bother rewriting? Because packaging is a nightmare.
ScyllaDB ships a relocatable package, a self-contained bundle with its own Python runtime baked in. The system Python can change, upgrade, or disappear entirely, and ScyllaDB’s startup scripts and cqlsh keep working because they’re running against a known, pinned Python version inside the bundle.
Except cqlsh has to live inside that bundle.
And cqlsh is a Python tool. It has dependencies, those dependencies’ dependencies have dependencies, and they all need to be vendored in alongside the bundled Python. Every time cqlsh or one of its dependencies needs updating (a bug fix, a new Cassandra protocol version, a security patch), you need to update the bundle, test the bundle, and ship the bundle. And if something conflicts or breaks inside that carefully pinned environment, it’s your problem to untangle.
A static Rust binary sidesteps all of this. You compile once per target, you get a single file with zero runtime dependencies, and you ship it. Done.
The second pain point is COPY TO/FROM, cqlsh‘s built-in feature for bulk-exporting and importing table data to CSV. It’s one of the most-used features, and it’s been carrying around a long list of bugs for years. It does have parallel workers (threads and processes), but the machinery is complicated, fragile, and notoriously hard to test. The bug list reflects that.
Both of these are solvable in Rust. So, the question became: is now the time to actually solve them?
It all started with a BIG plan (to the tune of The Big Bang Theory)
In a previous post, I wrote about using GitHub Copilot to bring a 4-year-old Python idea (coodie, a Pydantic ODM for Cassandra) back to life. That project was relatively contained: give the AI a concept, come back to a working implementation. Fire and forget it, more or less.
cqlsh-rs is a different category of project. The original Python cqlsh has been around for over a decade. It has hundreds of CLI flags, a compatibility matrix that spans multiple database versions, a COPY engine with 30+ options per direction, tab completion that must be schema-aware, and a type system covering 25+ CQL types with specific formatting rules. Shipping something that “mostly works” is not good enough if people are going to actually switch to it. Every muscle-memory command has to work the same way.
So before writing a single line of Rust, I started with a plan.
That plan started as one document. It grew, then it became a master design document plus sub-plans. By the time the architecture settled, there were 19 sub-plans (SP01 through SP19) covering everything from the CLI argument parser to the CQL type formatter to the COPY engine to a future --ai-help flag for offline CQL error diagnostics.
Here’s what the roadmap looked like near the start:
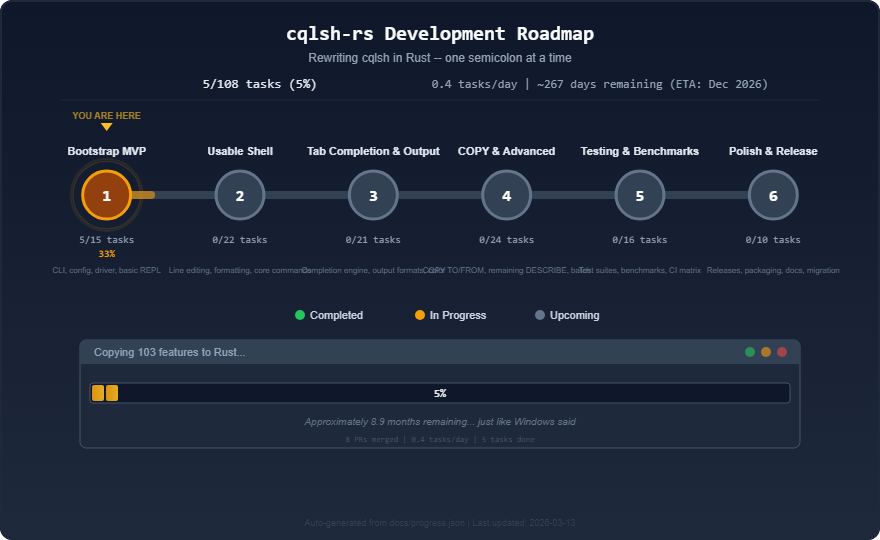
5 out of 108 tasks. 0.4 tasks per day. The footer on that SVG read: “Approximately 8.9 months remaining… just like Windows said.”
Reader, it did not take 8.9 months.
“Wait, why is there a skill for that?”
I started in Claude web, but not because that’s my comfort zone. With Copilot, I liked the browser because it made the conversation visible to the team, a kind of shared thinking space. I had the same instinct here. This way, design conversations, architecture decisions, trade-off explorations, etc all happened in the browser before a single file was created. Questions like
- What driver to use?
- How to structure the CLI argument parsing?
- Should we write a hand-rolled CQL parser or keep it simple with a line-buffer approach?
are genuinely better answered in conversation than in code.
The master plan came together there. So did the first sub-plans and the initial CI skeleton.
Then I started exploring Claude Code, the CLI. Somewhere around phase 2, I closed that browser tab once and for all. One reason is the feedback loop: you’re in the same environment as the code, so cargo test runs immediately after a change, failures surface in context, and the next prompt can reference the actual output. Another reason is just familiarity: the more you use it, the more you learn to point it at exactly the right problem.
Skills: write your conventions once, use them forever
The skills library was also critical for this project:
/rust-testing– What to test at the unit layer vs. the integration layer, how to useassert_cmdfor CLI tests, when to reach forinstasnapshots/rust-clippy– RunClippywith strict settings and fix everything it complains about/rust-error-handling– Idiomatic error handling patterns for this codebase/development-process– The full loop: review the relevant sub-plan, design tests first, implement, run tests, update the plan, commit
I carried the pattern directly from coodie. The specific skills are different (Python vs. Rust), but the idea is the same. Each skill you write makes every subsequent feature cheaper to build.
Living documents (or, an outdated plan is worse than no plan)
The 19 sub-plans are living documents that are updated when decisions are made (vs written upfront and then abandoned, like most docs). When a design decision changes mid-implementation, the plan changes too. When a task is done, the checkbox gets ticked. When a new edge case surfaces, it gets added.
This matters more than it might seem. An outdated plan is worse than no plan because the AI will follow it faithfully…in the wrong direction.
What’s in the box
Nothing terribly exotic; there’s:
- Rust with
Tokiofor async. - The scylla crate for the database driver.
- rustyline for the REPL and line editing.
- comfy-table and owo-colors for output formatting.
- testcontainers-rs for spinning up real Cassandra instances in CI.
While the stack itself might not be exciting, the interesting part is what it takes to get every CQL type to format exactly like the Python implementation – right down to float precision and frozen collection syntax. That’s where most of the compatibility work lives.
Where are we now?
Here’s the same roadmap today:
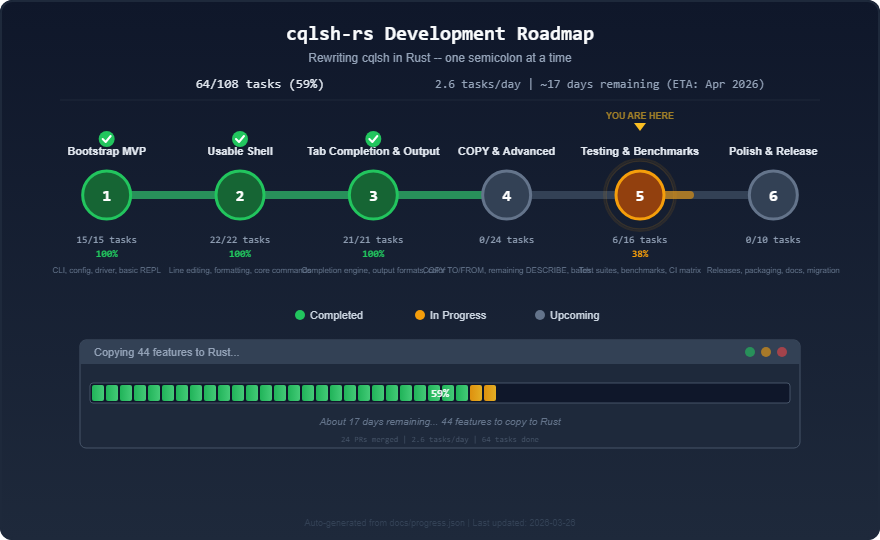
Phases 1 through 3 are done. The shell works: you can…
- Connect
- Run queries
- Get formatted output with colors and pagination
- Tab-complete keyspace and table names
- Run
DESCRIBEon anything - Use
SOURCEto execute a file
Phase 4 – COPY TO/FROM – is implemented.
Phase 5 (testing) is in progress, with 327 tests and counting.
Takeaways
Planning pays (but living documents are a nice touch). A static plan written at the start and never touched again is a liability. A plan that gets updated as decisions are made is an asset – and the primary reason Claude can work effectively across multiple sessions on a project this size.
Skills compound. A good amount of work is required to find the right skill for the task and adapt it to the project: the conventions, the patterns, the “this is how we do it here” info. But once that’s written down, it becomes easier to implement every feature.
The workflow is never done. The pace of this space is genuinely disorienting. We now regularly use tools that didn’t even exist six months ago. This means that what works today might not work in a month.
It’s still writing code, just differently. (I have a bit of trouble using the word “engineering” here.) Claude doesn’t replace judgment on architecture, on what actually matters to users, on “is this the right trade-off?” It removes the friction between having a clear idea of what you want and that thing existing. Whether that makes it better or worse probably depends on the day.
Lessons from one project carry over to the next. The skills pattern from coodie was carried into cqlsh-rs with a different language and a different domain. You can start from what you already learned, and the AI follows the same process docs that you wrote last time.
Things to look forward to
One idea that popped up during this: an --ai-help flag that embeds a small local model to give offline diagnostics when your CQL query fails. In other words, building an AI-assisted tool with an AI assistant that will assist with AI-assisted queries. I’m going to stop thinking about that too hard. 😉
For the model routing, we’ll probably use LiteLLM. I heard it’s become quite popular lately.
I had fun. Claude had fun too, probably. I didn’t ask.




