




Often-overlooked risks related to external caches — and how 3 teams are replacing their core database + external cache with a single solution (ScyllaDB)
Teams often consider external caches when the existing database cannot meet the required service-level agreement (SLA). This is a clear performance-oriented decision. Putting an external cache in front of the database is commonly used to compensate for subpar latency stemming from various factors, such as inefficient database internals, driver usage, infrastructure choices, traffic spikes and so on.
Caching might seem like a fast and easy solution because the deployment can be implemented without tremendous hassle and without incurring the significant cost of database scaling, database schema redesign or even a deeper technology transformation. However, external caches are not as simple as they are often made out to be. In fact, they can be one of the more problematic components of a distributed application architecture.
In some cases, it’s a necessary evil, such as when you require frequent access to transformed data resulting from long and expensive computations, and you’ve tried all the other means of reducing latency. But in many cases, the performance boost just isn’t worth it. You solve one problem, but create others.
Here are some often-overlooked risks related to external caches and ways three teams have achieved a performance boost plus cost savings by replacing their core database and external cache with a single solution. Spoiler: They adopted ScyllaDB, a high-performance database that achieves improved long-tail latencies by tapping a specialized internal cache.
Why Not Cache
At ScyllaDB, we’ve worked with countless teams struggling with the costs, hassles and limits of traditional attempts to improve database performance. Here are the top struggles we’ve seen teams experience with putting an external cache in front of their database.
An External Cache Adds Latency
A separate cache means another hop on the way. When a cache surrounds the database, the first access occurs at the cache layer. If the data isn’t in the cache, then the request is sent to the database. This adds latency to an already slow path of uncached data. One may claim that when the entire data set fits the cache, the additional latency doesn’t come into play. However, unless your data set is considerably small, storing it entirely in memory considerably magnifies costs and is thus prohibitively expensive for most organizations.
An External Cache is an Additional Cost
Caching means expensive DRAM, which translates to a higher cost per gigabyte than solid-state disks (see this P99 CONF talk by Grafana’s Danny Kopping for more details on that). Rather than provisioning an entirely separate infrastructure for caching, it is often best to use the existing database memory, and even increase it for internal caching. Modern database caches can be just as efficient as traditional in-memory caching solutions when sized correctly. When the working set size is too large to fit in memory, then databases often shine in optimizing I/O access to flash storage, making databases alone (no external cache) a preferred and cheaper option.
External Caching Decreases Availability
No cache’s high availability solution can match that of the database itself. Modern distributed databases have multiple replicas; they also are topology-aware and speed-aware and can sustain multiple failures without data loss.
For example, a common replication pattern is three local replicas, which generally allows for reads to be balanced across such replicas to efficiently make use of your database’s internal caching mechanism. Consider a nine-node cluster with a replication factor of three: Essentially every node will hold roughly a third of your total data set size. As requests are balanced among different replicas, this grants you more room for caching your data, which could completely eliminate the need for an external cache. Conversely, if an external cache happens to invalidate entries right before a surge of cold requests, availability could be impeded for a while since the database won’t have that data in its internal cache (more on this below).
Caches often lack high availability properties and can easily fail or invalidate records depending on their heuristics. Partial failures, which are more common, are even worse in terms of consistency. When the cache inevitably fails, the database will get hit by the unmitigated firehose of queries and likely wreck your SLAs. In addition, even if a cache itself has some high availability features, it can’t coordinate handling such failure with the persistent database it is in front of. The bottom line: Rely on the database, rather than making your latency SLAs dependent on a cache.
Application Complexity — Your Application Needs to Handle More Cases
External caches introduce application and operational complexity. Once you have an external cache, it is your responsibility to keep the cache up to date with the database. Irrespective of your caching strategy (such as write-through, caching aside, etc.), there will be edge cases where your cache can run out of sync from your database, and you must account for these during application development. Your client settings (such as failover, retry and timeout policies) need to match the properties of both the cache as well as your database to function when the cache is unavailable or goes cold. Usually such scenarios are hard to test and implement.
External Caching Ruins the Database Caching
Modern databases have embedded caches and complex policies to manage them. When you place a cache in front of the database, most read requests will reach only the external cache and the database won’t keep these objects in its memory. As a result, the database cache is rendered ineffective. When requests eventually reach the database, its cache will be cold and the responses will come primarily from the disk. As a result, the round-trip from the cache to the database and then back to the application is likely to add latency.
External Caching Might Increase Security Risks
An external cache adds a whole new attack surface to your infrastructure. Encryption, isolation and access control on data placed in the cache are likely to be different from the ones at the database layer itself.
External Caching Ignores The Database Knowledge And Database Resources
Databases are quite complex and built for specialized I/O workloads on the system. Many of the queries access the same data, and some amount of the working set size can be cached in memory to save disk accesses. A good database should have sophisticated logic to decide which objects, indexes and accesses it should cache. The database also should have eviction policies that determine when new data should replace existing (older) cached objects.
An example is scan-resistant caching. When scanning a large data set, say a large range or a full-table scan, a lot of objects are read from the disk. The database can realize this is a scan (not a regular query) and choose to leave these objects outside its internal cache. However, an external cache (following a read-through strategy) would treat the result set just like any other and attempt to cache the results. The database automatically synchronizes the content of the cache with the disk according to the incoming request rate, and thus the user and the developer do not need to do anything to make sure that lookups to recently written data are performant and consistent. Therefore, if, for some reason, your database doesn’t respond fast enough, it means that:
- The cache is misconfigured
- It doesn’t have enough RAM for caching
- The working set size and request pattern don’t fit the cache
- The database cache implementation is poor
A Better Option: Let the Database Handle It
How can you meet your SLAs without the risks of external database caches? Many teams have found that by moving to a faster database such as ScyllaDB with a specialized internal cache, they’re able to meet their latency SLAs with less hassle and lower costs. Results vary based on workload characteristics and technical requirements, of course. But for an idea of what’s possible, consider what these teams were able to achieve.
SecurityScorecard Achieves 90% Latency Reduction with $1 Million Annual Savings
SecurityScorecard aims to make the world a safer place by transforming the way thousands of organizations understand, mitigate and communicate cybersecurity. Its rating platform is an objective, data-driven and quantifiable measure of an organization’s overall cybersecurity and cyber risk exposure.
The team’s previous data architecture served them well for a while, but couldn’t keep up with their growth. Their platform API queried one of three data stores: Redis (for faster lookups of 12 million scorecards), Aurora (for storing 4 billion measurement stats across nodes), or a Presto cluster on Hadoop Distributed File System (for complex SQL queries on historical results).
As data and requests grew, challenges emerged. Aurora and Presto latencies spiked under high throughput. The largest possible instance of Redis still wasn’t sufficient, and they didn’t want the complexity of working with a Redis Cluster.
To reduce latencies at the new scale that their rapid business growth required, the team moved to ScyllaDB Cloud and developed a new scoring API that routed less latency-sensitive requests to Presto and S3 storage. Here’s a visualization of this – and considerably simpler – architecture:
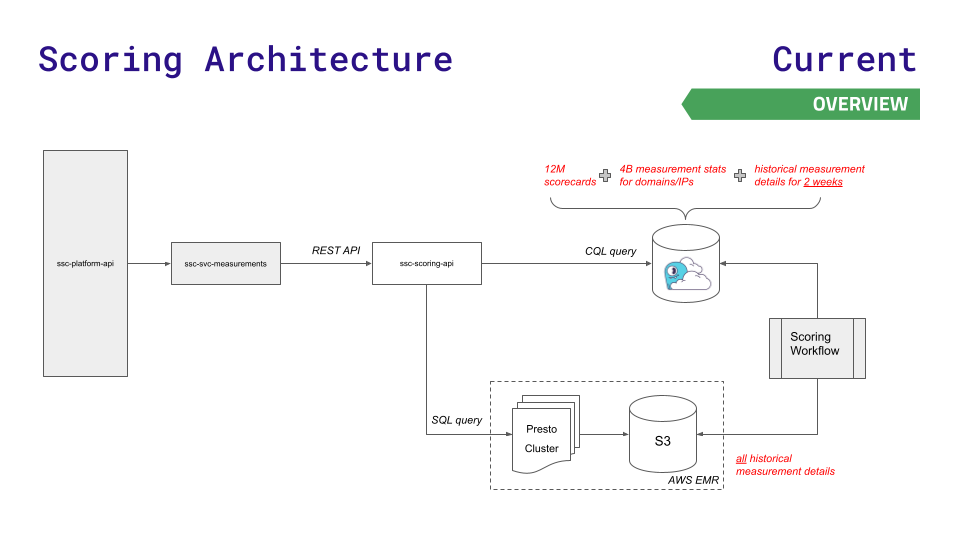
The move resulted in:
- 90% latency reduction for most service endpoints
- 80% fewer production incidents related to Presto/Aurora performance
- $1 million infrastructure cost savings per year
- 30% faster data pipeline processing
- Much better customer experience
Read more about the SecurityScorecard use case
IMVU Reins in Redis Costs at 100X Scale
A popular social community, IMVU enables people all over the world to interact with each other using 3D avatars on their desktops, tablets and mobile devices. To meet growing requirements for scale, IMVU decided it needed a more performant solution than its previous database architecture of Memcached in front of MySQL and Redis. The team looked for something that would be easier to configure, easier to extend and, if successful, easier to scale.
“Redis was fine for prototyping features, but once we actually rolled it out, the expenses started getting hard to justify,” said Ken Rudy, senior software engineer at IMVU. “ScyllaDB is optimized for keeping the data you need in memory and everything else in disk. ScyllaDB allowed us to maintain the same responsiveness for a scale a hundred times what Redis could handle.”
Comcast Reduces Long Tail Latencies 95% with $2.5 million Annual Savings
Comcast is a global media and technology company with three primary businesses: Comcast Cable, one of the United States’ largest video, high-speed internet and phone providers to residential customers; NBCUniversal and Sky. Comcast’s Xfinity service serves 15 million households with more than 2 billion API calls (reads/writes) and over 200 million new objects per day. Over seven years, the project expanded from supporting 30,000 devices to more than 31 million.
Cassandra’s long tail latencies proved unacceptable at the company’s rapidly increasing scale. To mask Cassandra’s latency issues from users, the team placed 60 cache servers in front of their database. Keeping this cache layer consistent with the database was causing major admin headaches. Since the cache and related infrastructure had to be replicated across data centers, Comcast needed to keep caches warm. They implemented a cache warmer that examined write volumes, then replicated the data across data centers.
After struggling with the overhead of this approach, Comcast soon moved to ScyllaDB. Designed to minimize latency spikes through its internal caching mechanism, ScyllaDB enabled Comcast to eliminate the external caching layer, providing a simple framework in which the data service connected directly to the data store. Comcast was able to replace 962 Cassandra nodes with just 78 nodes of ScyllaDB. They improved overall availability and performance while completely eliminating the 60 cache servers. The result: 95% lower P99, P999 and P9999 latencies with the ability to handle over twice the requests – at 60% of the operating costs. This ultimately saved them $2.5 million annually in infrastructure costs and staff overhead.
Closing Thoughts
Although external caches are a great companion for reducing latencies (such as serving static content and personalization data not requiring any level of durability), they often introduce more problems than benefits when placed in front of a database.
The top tradeoffs include elevated costs, increased application complexity, additional round trips to your database and an additional security surface area. By rethinking your existing caching strategy and switching to a modern database providing predictable low latencies at scale, teams can simplify their infrastructure and minimize costs. And at the same time, they can still meet their SLAs without the extra hassles and complexities introduced by external caches.


