How SecurityScorecard built a scalable and resilient security ratings platform with ScyllaDB
SecurityScorecard is the global leader in cybersecurity ratings, with millions of organizations continuously rated. Their rating platform provides instant risk ratings across ten groups of risk factors, including DNS health, IP reputation, web application security, network security, leaked information, hacker chatter, endpoint security, and patching cadence.
Nguyen Cao, Staff Software Engineer at SecurityScorecard, joined us at ScyllaDB Summit 2023 to share how SecurityScorecard’s scoring architecture works and why they recently rearchitected it. This blog shares his perspective on how they decoupled the frontend and backend services by introducing a middle layer for improved scalability and maintainability.
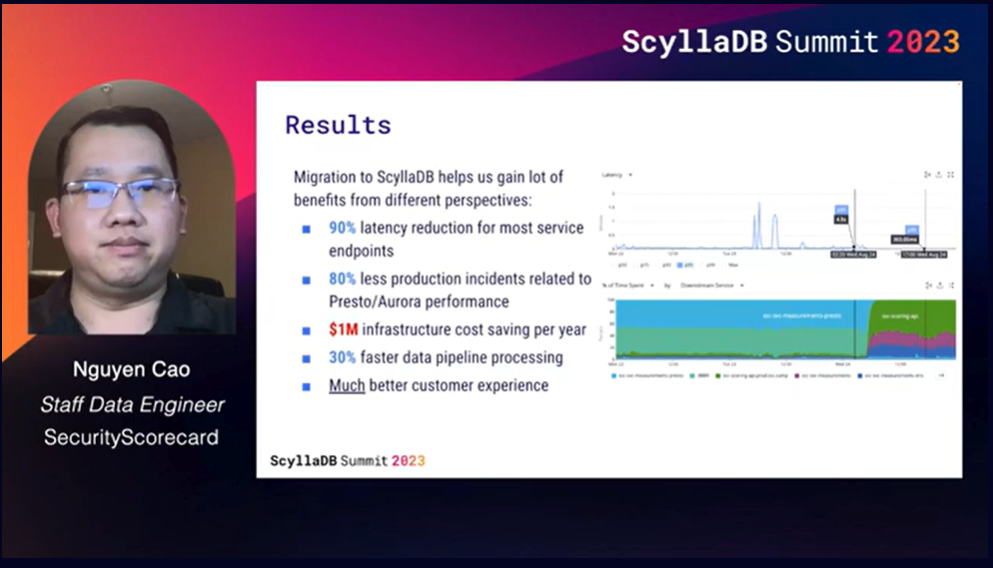
Spoiler: Their architecture shift involved a migration from Redis and Aurora to ScyllaDB. And it resulted in:
- 90% latency reduction for most service endpoints
- 80% fewer production incidents related to Presto/Aurora performance
- $1M infrastructure cost savings per year
- 30% faster data pipeline processing
- Much better customer experience
Curious? Read on as we unpack this.
Join us at ScyllaDB Summit 24 to hear more firsthand accounts of how teams are tackling their toughest database challenges. Disney, Discord, Expedia, Paramount, and more are all on the agenda.
Update: ScyllaDB Summit 2024 is now a wrap!
Access ScyllaDB Summit On Demand
SecurityScorecard’s Data Pipeline
SecurityScorecard’s mission is to make the world a safer place by transforming the way organizations understand, mitigate, and communicate cybersecurity to their boards, employees, and vendors. To do this, they continuously evaluate an organization’s security profile and report on ten key risk factors, each with a grade of A-F.
Here’s an abstraction of the data pipeline used to calculate these ratings:
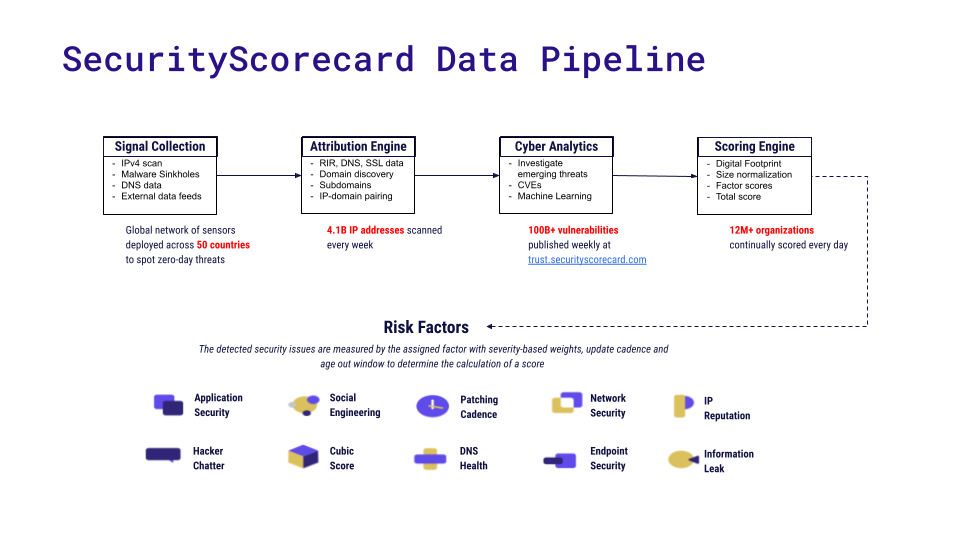
Starting with signal collection, their global networks of sensors are deployed across over 50 countries to scan IPs, domains, DNS, and various external data sources to instantly detect threats. That result is then processed by the Attribution Engine and Cyber Analytics modules, which try to associate IP addresses and domains with vulnerabilities. Finally, the scoring engines compute a rating score. Nguyen’s team is responsible for the scoring engines that calculate the scores accessed by the frontend services.
Challenges with Redis and Aurora
The team’s previous data architecture served SecurityScorecard well for a while, but it couldn’t keep up with the company’s growth.
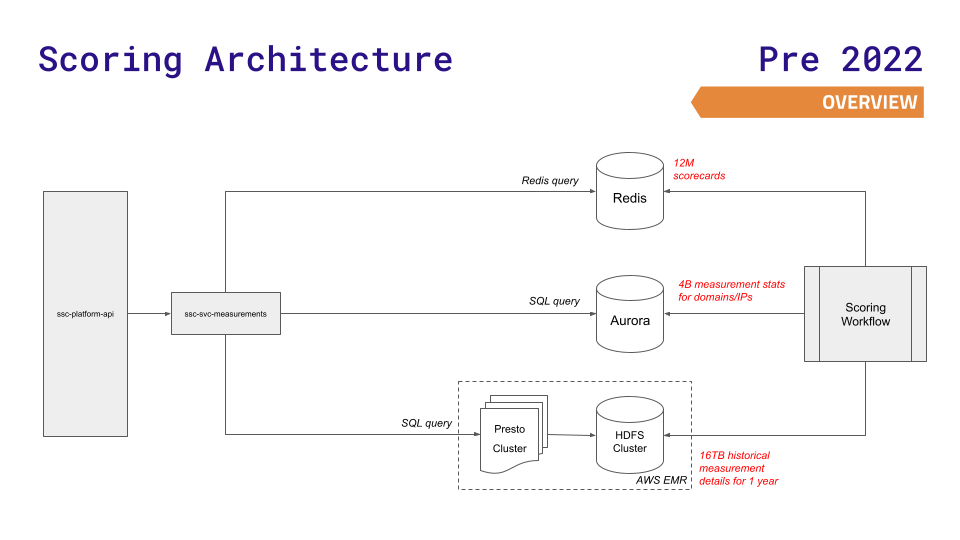
The platform API (shown on the left side of the diagram) received requests from end users, then made further requests to other internal services, such as the measurements service. That service then queried datastores such as Redis, Aurora, and Presto on HDFS. The scoring workflow (an enhancement of Apache Airflow) then generated a score based on the measurements and the findings of over 12 million scorecards.
This architecture met their needs for years. One aspect that worked well was using different datastores for different needs. They used three main datastores: Redis (for faster lookups of 12 million scorecards), Aurora (for storing 4 billion measurement stats across nodes), or a Presto cluster on HDFS (for complex SQL queries on historical results).
However, as the company grew, challenges with Redis and Aurora emerged.
Aurora and Presto latencies spiked under high throughput. The Scoring Workflow was running batch inserts of over 4B rows into Aurora throughout the day. Aurora has a primary/secondary architecture, where the primary node is solely responsible for writes and the secondary replicas are read-only. The main drawback of this approach was that their write-intensive workloads couldn’t keep up. Because their writes weren’t able to scale, this ultimately led to elevated read latencies because replicas were also overwhelmed. Moreover, Presto queries became consistently overwhelmed as the number of requests and amount of data associated with each scorecard grew. At times, latencies spiked to minutes, and this caused problems that impacted the entire platform.
The largest possible instance of Redis still wasn’t sufficient. The largest possible instance od Redis supported only 12M scorecards, but they needed to grow beyond that. They tried Redis cluster for increased cache capacity, but determined that this approach would bring excessive complexity. For example, at the time, only the Python driver supported consistent hashing-based routing. That meant they would need to implement their own custom drivers to support this critical functionality on top of their Java and Node.js services.
HDFS didn’t allow fast score updating. The company wants to encourage customers to rapidly remediate reported issues – and the ability to show them an immediate score improvement offers positive reinforcement for good behavior. However, their HDFS configuration (with data immutability) meant that data ingestion to HDFS had to go through the complete scoring workflow first. This meant that score updates could be delayed for 3 days.
Maintainability. Their ~50 internal services were implemented in a variety of tech stacks (Go, Java, Node.js, Python, etc.). All these services directly accessed the various datastores, so they had to handle all the different queries (SQL, Redis, etc.) effectively and efficiently. Whenever the team changed the database schema, they also had to update all the services.
Moving to a New Architecture with ScyllaDB
To reduce latencies at the new scale that their rapid business growth required, the team moved to ScyllaDB Cloud and developed a new scoring API that routed less latency-sensitive requests to Presto + S3 storage. Here’s a visualization of this – and considerably simpler – architecture:
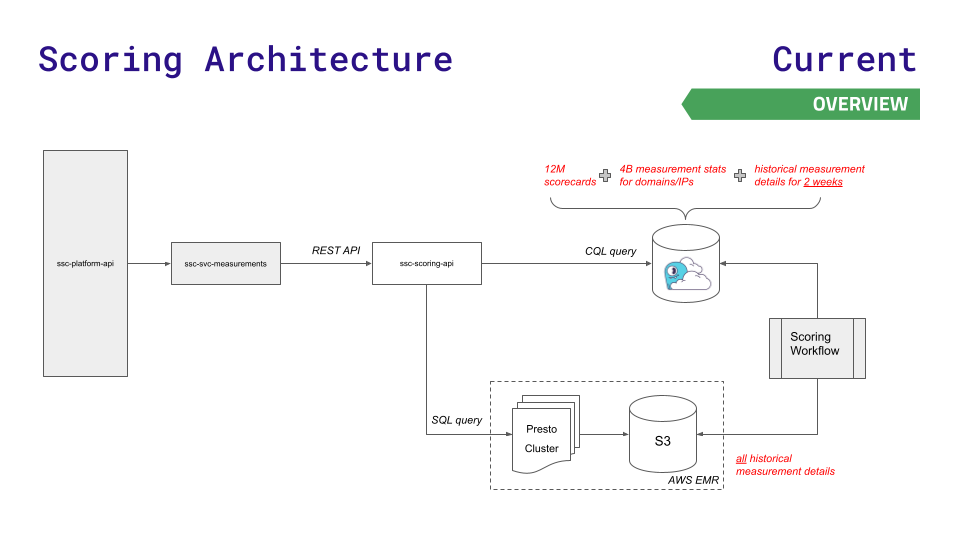
A ScyllaDB Cloud cluster replaced Redis and Aurora, and AWS S3 replaced HDFS (Presto remains) for storing the scorecard details. Also added: a scoring-api service, which works as a data gateway. This component routes particular types of traffic to the appropriate data store.
How did this address their challenges?
Latency
With a carefully-designed ScyllaDB schema, they can quickly access the data that they need based on the primary key. Their scoring API can receive requests for up to 100,000 scorecards. This led them to build an API capable of splitting and parallelizing these payloads into smaller processing tasks to avoid overwhelming a single ScyllaDB coordinator. Upon completion, the results are aggregated and then returned to the calling service. Also, their high read throughput no longer causes latency spikes, thanks largely to ScyllaDB’s eventually consistent architecture.
Scalability
With ScyllaDB Cloud, they can simply add more nodes to their clusters as demand increases, allowing them to overcome limits faced with Redis. The scoring API is also scalable since it’s deployed as an ECS service. If they need to serve requests faster, they just add more instances.
Fast Score Updating
Now, scorecards can be updated immediately by sending an upsert request to ScyllaDB Cloud.
Maintainability
Instead of accessing the datastore directly, services now send REST queries to the scoring API, which works as a gateway. It directs requests to the appropriate places, depending on the use case. For example, if the request needs a low-latency response it’s sent to ScyllaDB Cloud. If it’s a request for historical data, it goes to Presto.
Results & Lessons Learned
Nguyen then shared the KPIs they used to track project success. On the day that they flipped the switch, latency immediately decreased by over 90% on the two endpoints tracked in this chart (from 4.5 seconds to 303 milliseconds). They’re fielding 80% fewer incidents. And they’ve already saved over $1M USD a year in infrastructure costs by replacing Redis and Aurora. On top of that, they achieved a 30% speed improvement in their data processing.
Wrapping up, Nguyen shared their top 3 lessons learned:
- Design your ScyllaDB schema based on data access patterns with a focus on query latency.
- Route infrequent, complex, and latency-tolerant data access to OLAP engines like Presto or Athena (generating reports, custom analysis, etc.).
- Build a scalable, highly parallel processing aggregation component to fully benefit from ScyllaDB’s high throughput.
Watch the Complete SecurityScorecard Tech Talk
You can watch Nguyen’s complete tech talk and skim through the deck in our tech talk library.