How databases can get better performance by optimizing memory management
The following blog post is an excerpt from Chapter 3 of the Database Performance at Scale book, which is available for free. This book sheds light on often overlooked factors that impact database performance at scale.
Memory management is the central design point in all aspects of programming. Even comparing programming languages to one another always involves discussions about the way programmers are supposed to handle memory allocation and freeing. No wonder memory management design affects the performance of a database so much.
Applied to database engineering, memory management typically falls into two related but independent subsystems: memory allocation and cache control. The former is in fact a very generic software engineering issue, so considerations about it are not extremely specific to databases (though they are crucial and are worth studying). Opposite to that, the latter topic is itself very broad, affected by the usage details and corner cases. Respectively, in the database world, cache control has its own flavor.
Allocation
The manner in which programs or subsystems allocate and free memory lies at the core of memory management. There are several approaches worth considering.
As illustrated by Figure 3-2, a so-called “log-structured allocation” is known from filesystems where it puts sequential writes to a circular log on the persisting storage and handles updates the very same way. At some point, this filesystem must reclaim blocks that became obsolete entries in the log area to make some more space available for future writes. In a naive implementation, unused entries are reclaimed by rereading and rewriting the log from scratch; obsolete blocks are then skipped in the process.
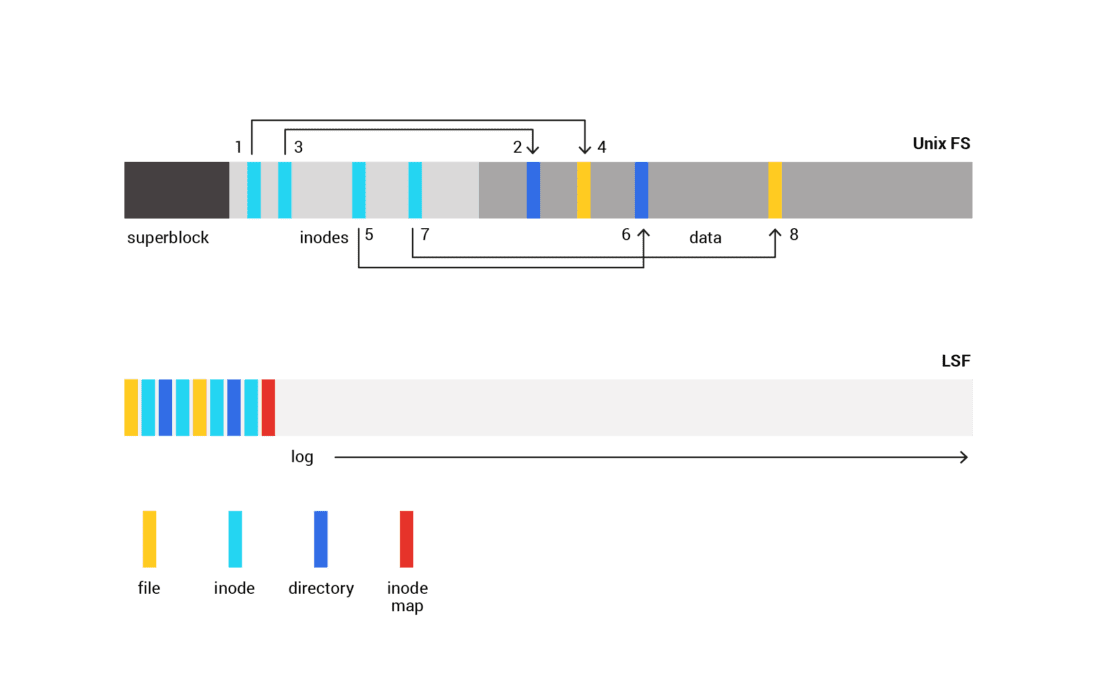
Figure 3-2: A log-structured allocation puts sequential writes to a circular log on the persisting storage and handles updates the very same way
A memory allocator for naive code can do something similar. In its simplest form, it would allocate the next block of memory by simply advancing a next-free pointer. Deallocation would just need to mark the allocated area as freed. One advantage of this approach is the speed of allocation. Another is the simplicity and efficiency of deallocation if it happens in FIFO order or affects the whole allocation space. Stack memory allocations are later released in the order that’s reverse to allocation, so this is the most prominent and the most efficient example of such an approach.
Using linear allocators as general-purpose allocators can be more problematic because of the difficulty of space reclamation. To reclaim space, it’s not enough to just mark entries as free. This leads to memory fragmentation, which in turn outweighs the advantages of linear allocation. So, as with the filesystem, the memory must be reclaimed so that it only contains allocated entries and the free space can be used again. Reclamation requires moving allocated entries around – a process that changes and invalidates their previously known addresses. In naive code, the locations of references to allocated entries (addresses stored as pointers) are unknown to the allocator. Existing references would have to be patched to make the allocator action transparent to the caller; that’s not feasible for a general-purpose allocator like malloc. Logging allocator use is tied to the programming language selection. Some RTTIs, like C++, can greatly facilitate this by providing move-constructors. However, passing pointers to libraries that are outside of your control (e.g., glibc) would still be an issue.
Another alternative is adopting a strategy of pool allocators, which provide allocation spaces for allocation entries of a fixed size (see Figure 3-3). By limiting the allocation space that way, fragmentation can be reduced. A number of general-purpose allocators use pool allocators for small allocations. In some cases, those application spaces exist on a per-thread basis to eliminate the need for locking and improve CPU cache utilization.
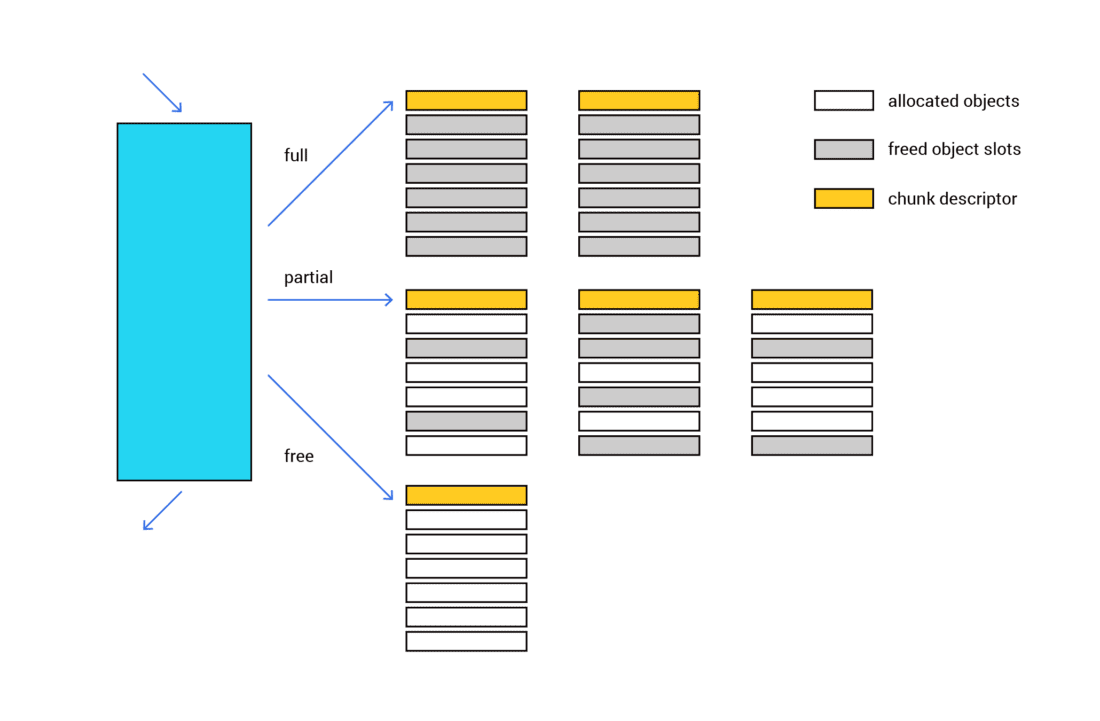
Figure 3-3: Pool allocators provide allocation spaces for allocation entries of a fixed size. Fragmentation is reduced by limiting the allocation space
This pool allocation strategy provides two core benefits. First, it saves you from having to search for available memory space. Second, it alleviates memory fragmentation because it pre-allocates in memory a cache for use with a collection of object sizes. Here’s how it works to achieve that:
- The region for each of the sizes has fixed-size memory chunks that are suitable for the contained objects, and those chunks are all tracked by the allocator.
- When it’s time for the allocator to actually allocate memory for a certain type of data object, it’s typically possible to use a free slot (chunk) within one of the existing memory slabs. ( Note: We are using the term “slab” to mean one or more contiguous memory pages that contain pre-allocated chunks of memory.)
- When it’s time for the allocator to free the object’s memory, it can simply move that slot over to the containing slab’s list of unused/free memory slots.
- That memory slot (or some other free slot) will be removed from the list of free slots whenever there’s a call to create an object of the same type (or a call to allocate memory of the same size).
The best allocation approach to pick heavily depends upon the usage scenario. One great benefit of a log-structured approach is that it handles fragmentation of small sub-pools in a more efficient way. Pool allocators, on the other hand, generate less background load on the CPU because of the lack of compacting activity.
Cache control
When it comes to memory management in a software application that stores lots of data on disk, you cannot overlook the topic of cache control. Caching is always a must in data processing, and it’s crucial to decide what and where to cache.
If caching is done at the I/O level, for both read/write and mmap, caching can become the responsibility of the kernel. The majority of the system’s memory is given over to the page cache. The kernel decides which pages should be evicted when memory runs low, when pages need to be written back to disk, and controls read-ahead. The application can provide some guidance to the kernel using the madvise(2) and fadvise(2) system calls.
The main advantage of letting the kernel control caching is that great effort has been invested by the kernel developers over many decades into tuning the algorithms used by the cache. Those algorithms are used by thousands of different applications and are generally effective. The disadvantage, however, is that these algorithms are general-purpose and not tuned to the application. The kernel must guess how the application will behave next. Even if the application knows differently, it usually has no way to help the kernel guess correctly. This results in the wrong pages being evicted, I/O scheduled in the wrong order, or read-ahead scheduled for data that will not be consumed in the near future.
Next, doing the caching at the I/O level interacts with the topic often referred to as IMR – in memory representation. No wonder that the format in which data is stored on disk differs from the form the same data is allocated in memory as objects. The simplest reason why it’s not the same is byte-ordering. With that in mind, if the data is cached once it’s read from the disk, it needs to be further converted or parsed into the object used in memory. This can be a waste of CPU cycles, so applications may choose to cache at the object level.
Choosing to cache at the object level affects a lot of other design points. With that, the cache management is all on the application side including cross-core synchronization, data coherence, invalidation, etc. Next, since objects can be (and typically are) much smaller than the average I/O size, caching millions and billions of those objects requires a collection selection that can handle it (we’ll get to this in a follow-up blog). Finally, caching on the object level greatly affects the way I/O is done.