





How ScyllaDB and DynamoDB cost and latency compare across different workloads and pricing models
Since early 2022, ScyllaDB has experienced a significant increase in the number of DynamoDB users moving to ScyllaDB Cloud, our database-as-a-service offering. Price performance is cited as a primary driver in virtually all of these interactions. To help teams better assess whether a move makes sense, we decided to expand on our original DynamoDB benchmark with a detailed price-performance comparison analyzing:
- How cost compares across both DynamoDB pricing models under various workload conditions, distributions, and read:write ratios
- How latency compares across a variety of workload conditions
This report outlines the detailed findings, but here’s the bottom line: ScyllaDB costs are significantly lower in all but one scenario. In realistic workloads, costs would be 5X to 40X lower — with up to 4X better P99 latency
Here is a consolidated look at how DynamoDB and ScyllaDB compare on cost and performance for just one of the many workloads we tested. DynamoDB shines with a Uniform distribution and struggles with the others; we chose to highlight a case where it shines.
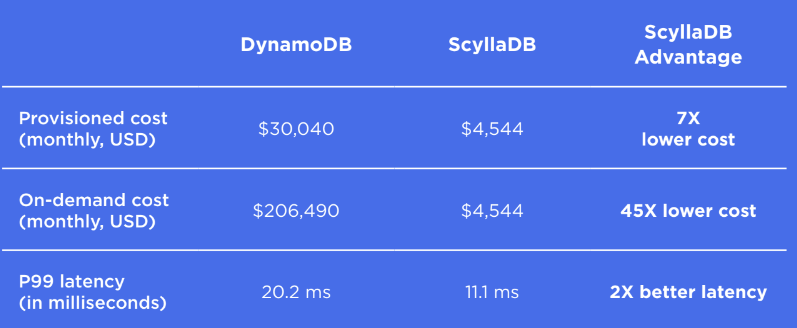
Note that for ScyllaDB, we use on-demand pricing for both cost comparisons. “Provisioned throughput pricing” does not apply to ScyllaDB. Also, both vendors offer discounts for annual and multi-year commitments. ScyllaDB’s latencies were measured when utilization was at 75% capacity, where throughput was reported. Lower utilization results in better latencies.

Cost Results
For our cost comparisons, we started with a range of throughput + workload scenarios and calculated their cost on ScyllaDB Cloud with the AWS instances specified in the extended report. Next, we calculated the cost of running the same throughput + workload scenarios on DynamoDB. We needed to know:
- The item size (to compute the WCUs and RCUs used per operation)
- The monthly price for 1 TB of storage
- The cost per unit
We used an item size of 1081 bytes (calculated using the DynamoDB documentation), which translates to 2 WCUs per write operation and 1 RCU per read operation on DynamoDB. 1 TB costs ~$250/month. The cost per unit varies according to the pricing model: provisioned or on-demand.
For ScyllaDB we used a 3-node cluster for all modes. Users can scale out/in the cluster at any point. Hourly rates (on-demand) were used for ScyllaDB. As the platform scales with the amount of resources, you can linearly change the price for the performance level you require. Annual pricing provides significant cost reduction but is out of the scope of this benchmark.
DynamoDB has two modes for non-annual pricing: provisioned and on-demand pricing. Provisioned mode is recommended if your workloads are reasonably predictable. On-demand pricing is significantly more expensive and is a fit for unpredictable workloads. It is possible to combine modes, add auto-scaling, and so forth. DynamoDB provides considerable flexibility around managing the cost and scale of the aforementioned options, but this also results in considerable complexity.
We measured the ScyllaDB performance in all different workload mixes and distributions, then compared it to the cost of DynamoDB with allocations to the required read/write units. Note that beyond ScyllaDB’s on-demand pricing (which can be estimated via our pricing calculator), discounts are provided for annual commitments. To see how we calculated costs, refer to the Cost Calculations section of the full report’s Appendix.
Access Detailed Benchmark Report
ScyllaDB Utilization
The number of operations per second that the ScyllaDB cluster performs for each workload is reported under the X axis in the following graphs. Through all tests, we ensured that the ScyllaDB cluster utilization (load) was no more than 75% and reported its resulting latency. Given that, note that it is possible to achieve higher peak performance (up to 2x the amount reported for shorter bursts) at no additional cost under a cluster of the same size, as well as achieve lower latencies with a lower utilization.
Provisioned Mode Cost Comparisons
Provisioned mode is recommended if your workloads are reasonably predictable. With DynamoDB, you need to be able to predict per-table capacity regarding read and write capacity units.
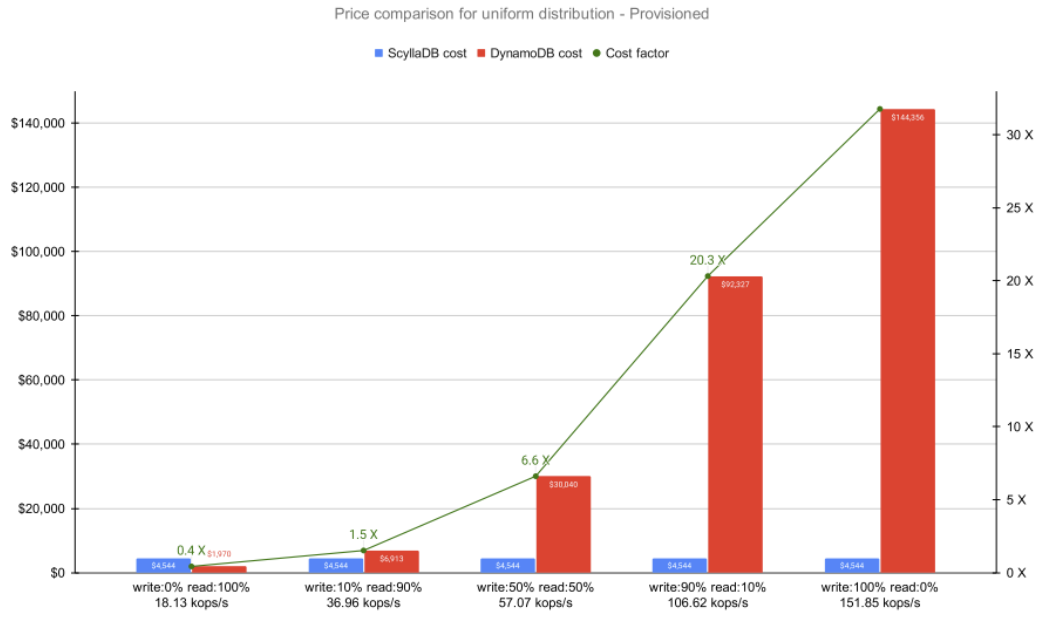
With just one exception, DynamoDB’s cost estimates were consistently higher than ScyllaDB’s – and much more so for the most write-heavy workloads.* This is not surprising, given that DynamoDB charges 5X more for writes than for reads, while ScyllaDB does not differentiate between operations, and its pricing is based on the actual cluster size.
We also compared pricing using DynamoDB’s on-demand pricing model. For details, see the complete benchmark report.
Access Complete Benchmark Report
Performance Results
Next, let’s shift the focus to performance. For use cases that require near real-time responses (e.g., AdTech, messaging, gaming, IoT), P99 latency is critical for meeting SLAs and delivering an engaging user experience.
Uniform Distribution
Here are the performance results for the Uniform distribution.
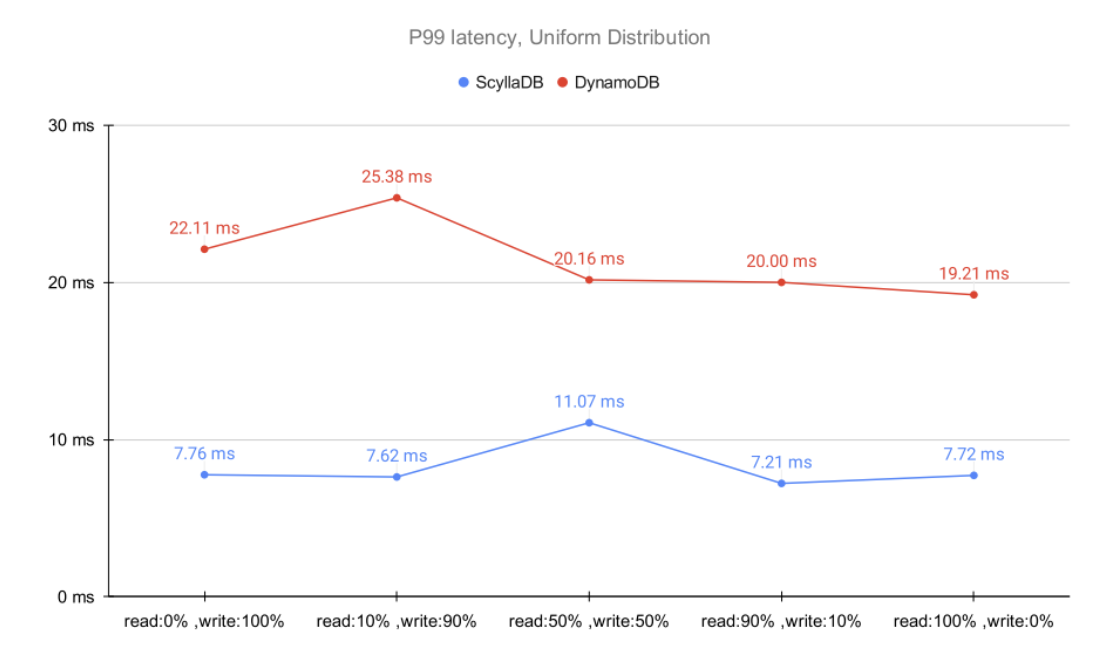
ScyllaDB’s latency was significantly lower than that of DynamoDB – at a fraction of the cost. An even larger reduction in P99 latency and mean latency (under 1 ms) could be achieved by using a larger ScyllaDB cluster and reducing the utilization from 75% to the 30%-50% range. Additionally, ScyllaDB comes with several options which might further improve latencies, such as the BYPASS CACHE extension, designed for workloads that don’t make effective use of caching (e.g., a workload that is much larger than the RAM with Uniform distribution). Such options have not been applied for the purpose of this performance testing.
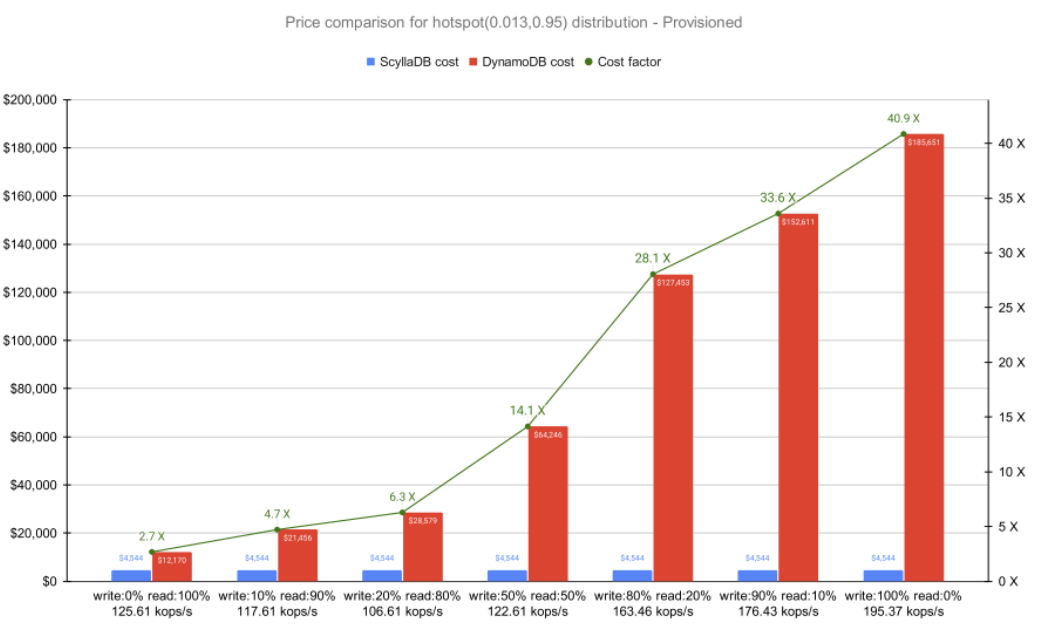
Hotspot Distribution
Now, let’s shift to a more realistic distribution: Hotspot. As explained in the full report’s Appendix, the Hotspot distribution has some sets of values accessed more frequently than others.
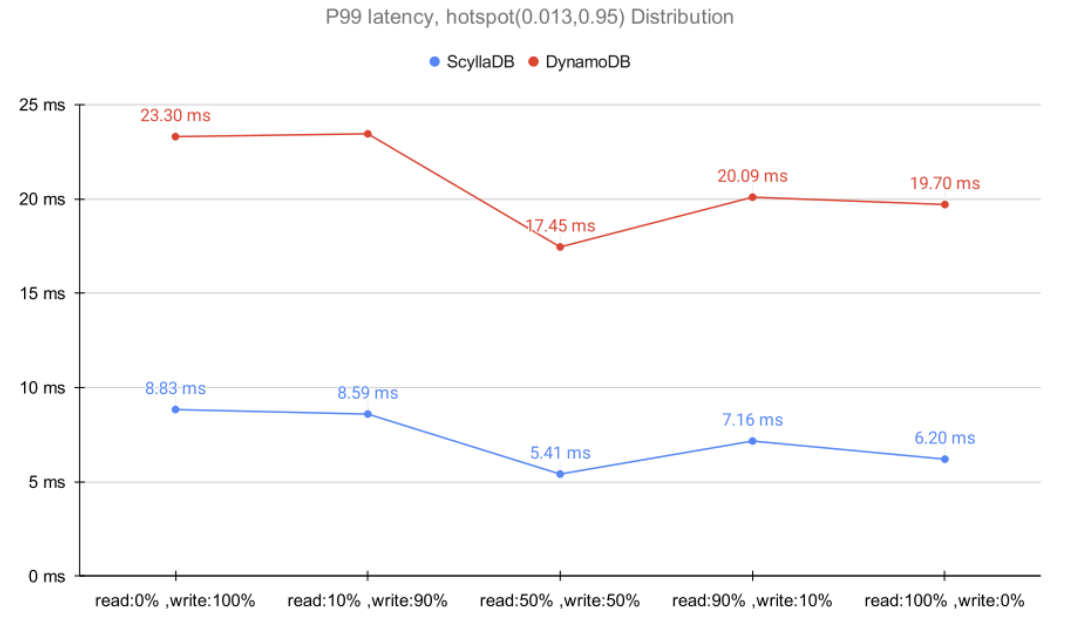
As you can see, the discrepancy between DynamoDB and ScyllaDB latencies widened for these more realistic workloads. Since a portion of the requests had a higher chance of hitting an object from the hot set, the probability of ScyllaDB’s cache being touched during reads increased significantly. The results show that ScyllaDB P99 latencies decreased compared to the previous Uniform results as the read ratio increased.
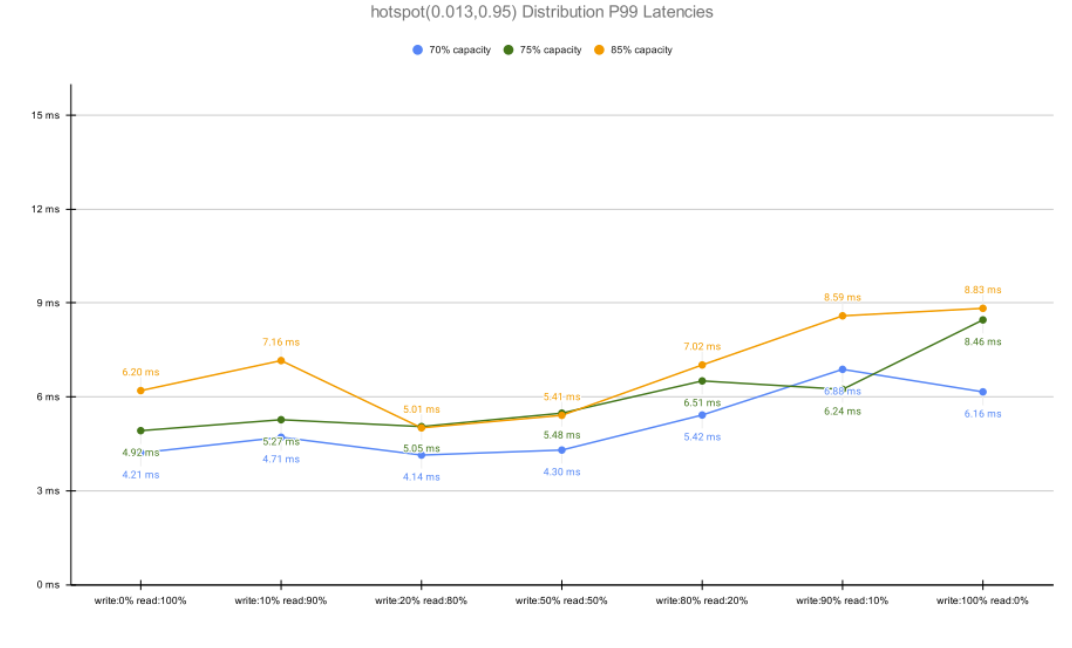
The next graph represents the P99 latency as a function of ScyllaDB’s utilization. Note how the P99 decreases along with a lower cluster load:
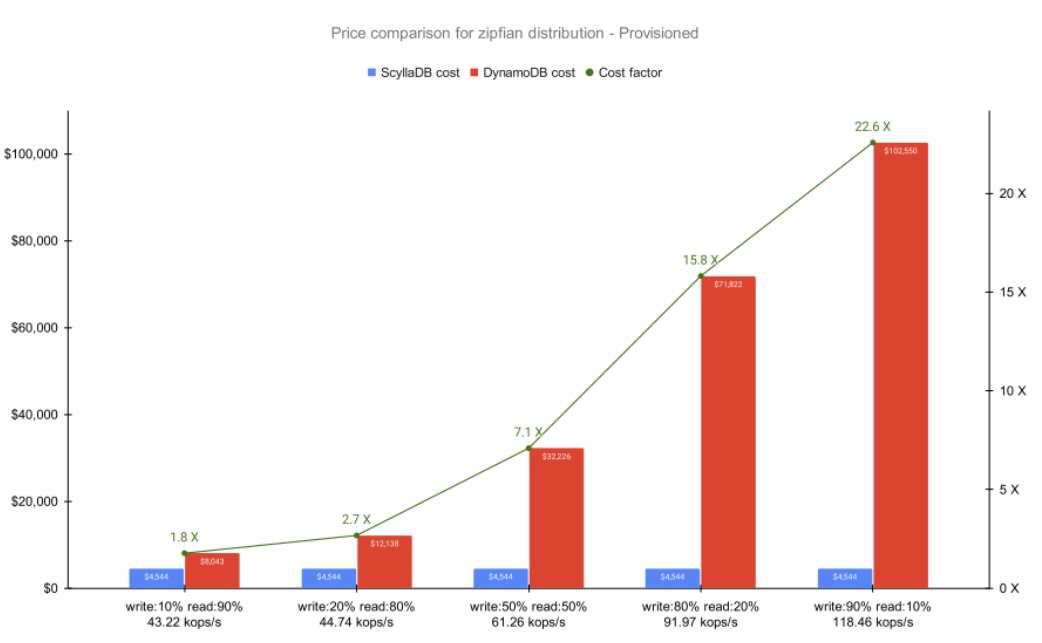
Zipfian Distribution
Finally, let’s look at the interesting case of Zipfian distribution. Zipfian distribution takes the hotspot to new levels by simulating access patterns with an exponential relation between items (a.k.a. “hotness”). As Alex DeBrie notes, Zipfian is generally problematic for DynamoDB: “The most popular items are accessed orders of magnitude more than the average item. Because DynamoDB wants a more even distribution of your data, your application may get throttled as it tries to access popular items.”
As expected, DynamoDB performed poorly on these workloads.
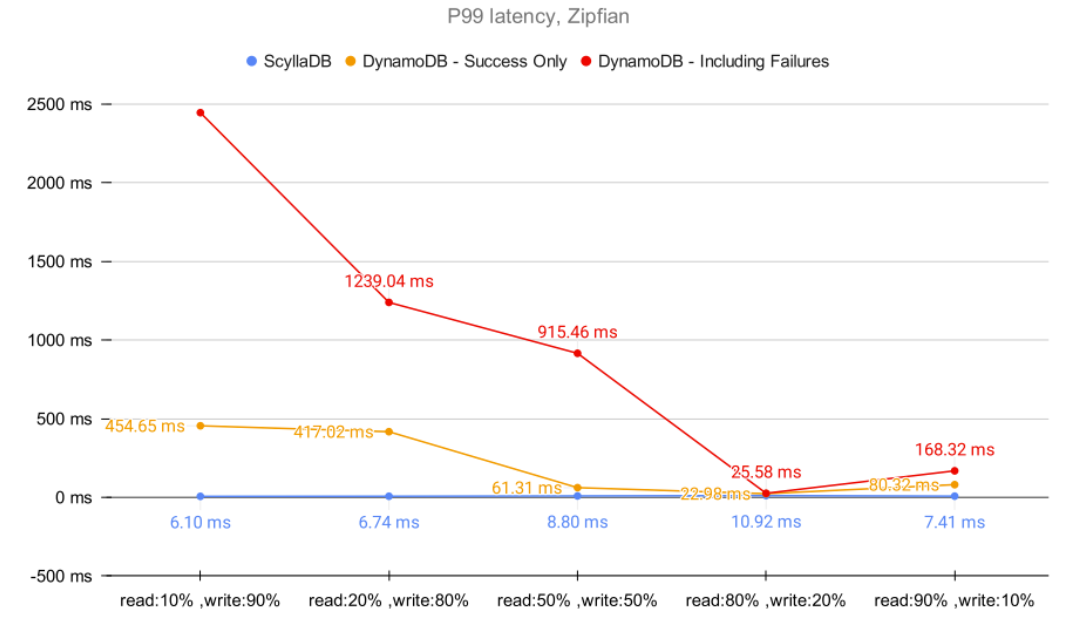
As noted by DeBrie, the Zipfian distribution is likely to create hot partitions, an imbalance introduced by uneven item access from within the database. As hot partitions are a known antipattern, DynamoDB restricts the number of hits on the same partition (documented to be 3,000 RCUs and 1,000 WCUs per partition at the time of writing). Aware of this limitation and of Zipfian’s imbalances, we compared both ScyllaDB and DynamoDB at scale.
Once DynamoDB limits were reached, requests started getting throttled, requiring the application to retry. As a result of the throttling and retries, the YCSB latency became severely impacted. Under some circumstances, we experienced DynamoDB throttling at up to ~2.5 seconds per request – thus preventing the application from accessing the item during that time.
At best, DynamoDB delivered 39.72% of the expected throughput (88.19 good kops/s vs. the target 222 kops/s). At worst, it delivered only 16.22% (20.28 kops/s) of what was purchased (125 kops/s) and supposedly provisioned. Given the documented DynamoDB limitations, some discrepancy is to be expected. However, the magnitude of this unfulfilled throughput was surprising.
Unlike DynamoDB, ScyllaDB managed to sustain the target throughput without any throttling and still deliver single-digit millisecond latencies. In that regard, ScyllaDB does not impose any hard limits on querying hot partitions. Even though ScyllaDB implements concurrency-limiting mechanisms, frequently accessing popular items will typically benefit from its cache implementation – thus explaining why no failures have been seen during the Zipfian tests. Even then, it is worth underscoring that hot partitions are an antipattern, even for databases like ScyllaDB. Read more about ScyllaDB’s advanced control mechanisms in ScyllaDB in this blog.
Advanced Configurations
Caching: DynamoDB Accelerator (DAX)
Given the latency results, it is interesting to note that teams using DynamoDB with latency-sensitive workloads and strict P99 requirements might require relying on DynamoDB Accelerator (DAX) to achieve their SLA targets. However, caching solutions add a significant increase to DynamoDB costs and complexity (driven by the constant need to monitor cost, reserved capacity, and scaling). ScyllaDB does not require any external caching component to sustain predictable low latencies. As mentioned in the extended report, ScyllaDB’s BYPASS CACHE feature allows the user to give the database hints about which query results should not be cached, thus protecting against cache invalidation.
Auto Scaling: A Mix of Provisioned and On-Demand
Once the DynamoDB cost grows, users often start to optimize it with a set of tools that AWS offers: combining on-demand and provisioned workloads, auto scaling, etc.
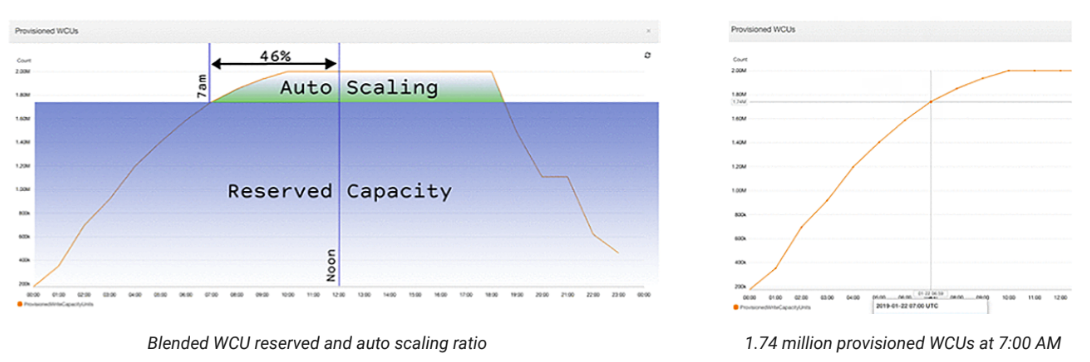
However, this not only increases complexity; it could also incur limitations from the speed of elasticity and even throttling. Any cost savings achieved by adding this complexity are highly unlikely to close the large cost gap between the two databases.
Making ScyllaDB Even More Cost Effective
Unlike DynamoDB (where you provision tables), ScyllaDB is provisioned as a cluster, capable of hosting several tables – and therefore consolidating several workloads under a single deployment. Excess hardware capacity may be shared to power more use cases on that cluster. Users may rely on ScyllaDB’s Workload Prioritization feature to assign different priorities to different tables (or to different use cases that share a single table).
For example, assume there are 10 use cases that require 100K OPS each. However, at any given point in time, only two of them will reach their limit. With DynamoDB, users would be forced to allocate a provisioned workload per table or to use the rather expensive on-demand mode. A standard ScyllaDB deployment is not only more cost effective. It also allows users to run all 10 workloads within a single cluster with a sustained capacity of 200k-300k OPS, and to share the idle time among all those workloads. Prioritized workloads will receive more CPU and IO resources from the scheduler, resulting in higher throughput and lower latencies.
Conclusion
As the results indicate, what might begin at a seemingly reasonable cost can quickly escalate into “bill shock” with DynamoDB – especially as the throughput increases, and particularly with write-heavy workloads. This makes it a suboptimal choice for data-intensive applications anticipating steady or rapid growth. ScyllaDB’s significantly lower costs – a reflection of ScyllaDB taking full advantage of modern infrastructure for high throughput and low latency – make it a more cost-effective solution for data-intensive applications.
ScyllaDB – with its LSM-tree-based storage, unified caching, shard-per-core design, and advanced schedulers – allows you to maximize the advantages of modern hardware, from huge CPU chips to blazing-fast NVMe.
This small-scale benchmark demonstrated how a 57K OPS workload with a 50:50 read/write ratio that cost $4,500/month on-demand on ScyllaDB would cost $30,000 to $200,000/month with DynamoDB. Beyond those cost savings, ScyllaDB sustains 2X peaks and provides 2X-4X better P99 latency. Additionally, it can further reduce latency when idle – or enable spare resources to be shared across multiple tables. For larger workloads spanning 500K-1M OPS and beyond, this can result in a cost saving in the millions – with better performance and fewer query limitations.
Additional Details About the Benchmark
See the complete benchmark report for additional details on:
- Methodology (including considerations, setup, and workloads)
- Our YCSB configuration and modifications
- How we calculated costs across both provisioned and on-demand pricing models
- A deeper dive into distributions (uniform, hotspot, and Zipfian)
Access Detailed Benchmark Report
* In the 1 out of 15 cases where DynamoDB turned out to be less expensive (at the price of higher P99 latency), ScyllaDB could actually drive more utilization to win over DynamoDB. However, we wanted to keep the results standard and fair.


