




benchANT compares MongoDB and ScyllaDB architectures, with a focus on what the differences mean for performance and scalability
When choosing a NoSQL database, the options can be overwhelming. One of the most popular choices is MongoDB, known for its easy use. But the highly performance-oriented ScyllaDB is one of the rising challengers. This benchANT report takes a closer technical look at both databases – comparing their architectures from an independent, technical angle.
Both MongoDB and ScyllaDB promise a high-available, performant and scalable architecture. But the way they achieve these objectives is much more different than you might think at first glance. For instance, an experience report demonstrates how ScyllaDB can easily be operated on AWS EC2 spot instances thanks to its distributed architecture while MongoDB’s distributed architecture would make this a very challenging task.
To highlight these differences, we provide an in-depth discussion of the internal storage architecture and the distributed architectures enabling high-availability and horizontal scalability.
Note: We also just released a benchmark quantifying the impact of these differences.
Read the DynamoDB vs MongoDB Benchmark Summary
Download this Comparison Report
A Performance Viewpoint on the Storage Architecture of MongoDB vs ScyllaDB
Both databases are implemented in C++ and recommend the use of the XFS filesystem. Moreover, MongoDB and ScyllaDB are building upon the write-ahead-logging concept, Commit Log in ScyllaDB terminology and Oplog in MongoDB terminology. With write-ahead-logging, all operations are written to a log table before the operation is executed. The write-ahead-log serves as a source to replicate the data to other nodes, and it is used to restore data in case of failures because it is possible to `replay` the operations to restore the data.
MongoDB uses as default storage engine a B+-Tree index (Wired Tiger) for data storage and retrieval. B+-Tree indexes are balanced tree data structures that store data in a sorted order, making it easy to perform range-based queries. MongoDB supports multiple indexes on a collection, including compound indexes, text indexes, and geospatial indexes. Indexing of array elements and nested fields, allowing for efficient queries on complex data structures, are also possible. In addition, the enterprise version of MongoDB supports an in-memory storage engine for low latency workloads.
ScyllaDB divides data into shards by assigning a fragment of the total data in a node to a specific CPU, along with its associated memory (RAM) and persistent storage (such as NVMe SSD). The internal storage engine of ScyllaDB follows the write-ahead-logging concept by applying a disk persistent commit log together with memory based memtables that are flushed to disk over time. ScyllaDB supports primary, secondary and composite indexes, both local per node and global per cluster. The primary index consists of a hashing ring where the hashed key and the corresponding partition are stored. And within the partition, ScyllaDB finds the row in a sorted data structure (SSTable), which is a variant of the LSM-Tree. The secondary index is maintained in an index table. When a secondary index is queried, ScyllaDB first retrieves the partition key, which is associated with the secondary key, and afterward the data value for the secondary key on the right partition.
These different storage architectures result in a different usage of the available hardware to handle the workload. MongoDB does not pin internal threads to available CPU cores but applies an unbound approach to distributed threads to cores. With modern NUMA-based CPU architectures, this can cause a performance degradation, especially for large servers because threads can dynamically be assigned to cores on different sockets with different memory nodes. In contrast, ScyllaDB follows a shard per core approach that allows it to pin the responsible threads to specific cores and avoids switching between different cores and memory spaces. In consequence, the shard key needs to be selected carefully to ensure an equal data distribution across the shards and to prevent hot shards. Moreover, ScyllaDB comes with an I/O scheduler that provides built-in priority classes for latency sensitive and insensitive queries, as well as the coordinated I/O scheduling across the shards on one node to maximize disk performance. Finally, ScyllaDB’s install scripts come with a performance auto-tuning step by applying the optimal database configuration based on the available resources. In consequence, a clear performance advantage of ScyllaDB can be expected.
ScyllaDB allows the user to control whether data should reside in the DB cache or bypass it for rarely accessed partitions. ScyllaDB allows the client to reach the node and cpu core (shard) that owns the data. This provides lower latency, consistent performance and perfect load balancing. ScyllaDB also provides ‘workload prioritization’ which provides the user different SLAs for different workloads to guarantee lower latency for certain, crucial workloads.
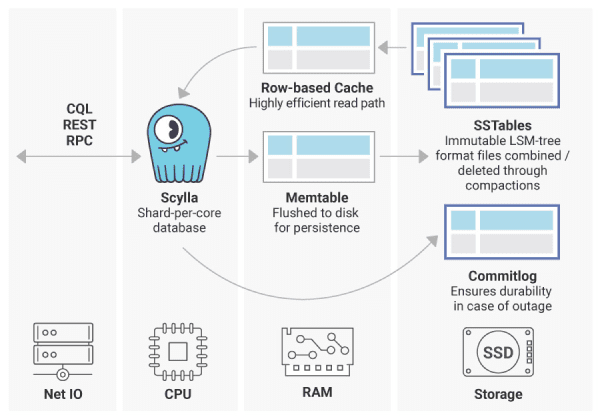
The MongoDB Distributed Architecture – Two Operation Modes For High Availability and Scalability
The MongoDB database architecture offers two cluster modes that are described in the following sections: a replica set cluster targets high availability, while a sharded cluster targets horizontal scalability and high availability.
Replica Set Cluster: High Availability with Limited Scalability
The MongoDB architecture enables high availability by the concept of replica sets. MongoDB replica sets follow the concept of Primary-Secondary nodes, where only the primary handles the WRITE operations. The secondaries hold a copy of the data and can be enabled to handle READ operations only. A common replica set deployment consists of two secondaries, but additional secondaries can be added to increase availability or to scale read-heavy workloads. MongoDB supports up to 50 secondaries within one replica set. Secondaries will be elected as primary in case of a failure at the former primary.
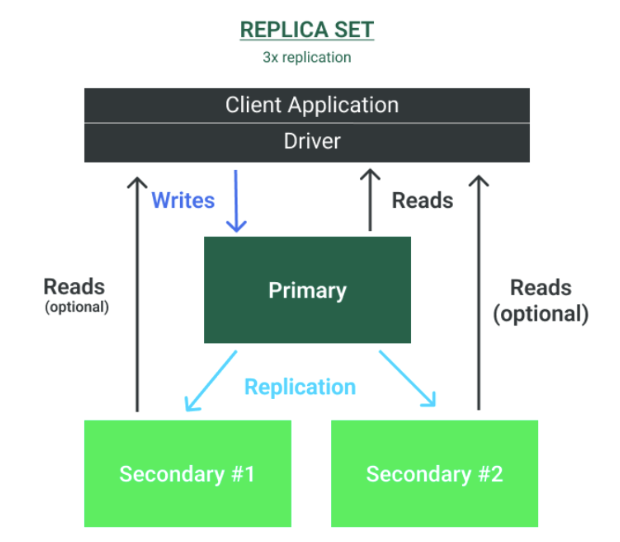
Regarding geo-distribution, MongoDB supports geo-distributed deployments for replica sets to ensure high availability in case of data center failures. In this context, secondary instances can be distributed across multiple data centers, as shown in the following figure. In addition, secondaries with limited resources or network constraints can be configured with a priority to control their electability as primary in case of a failure.
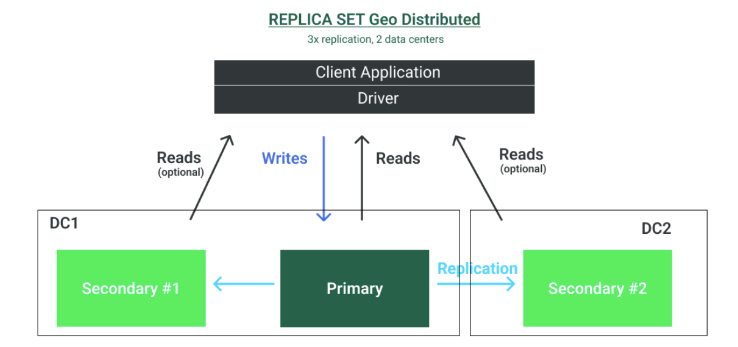
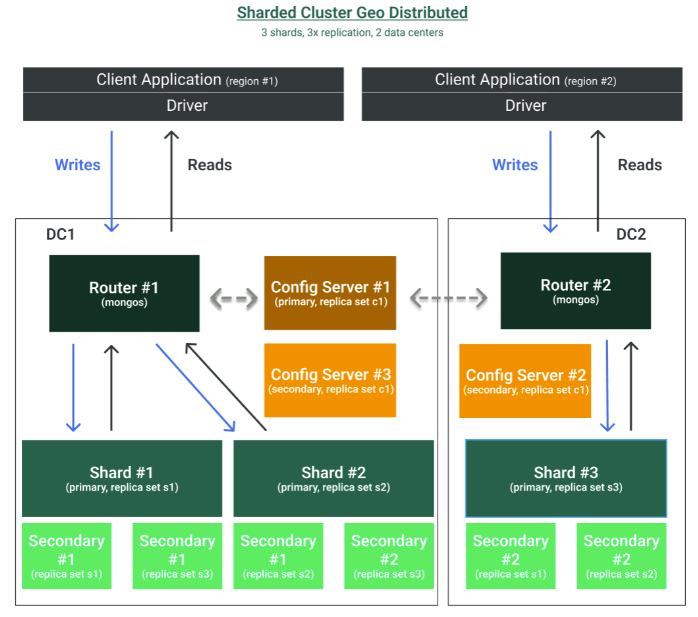
Sharded Cluster: Horizontal Scalability and High-Availability with Operational Complexity
MongoDB supports horizontal scaling by sharding data across multiple primary instances to cope with write-intensive workloads and growing data sizes. In a sharded cluster, each replica set consisting of one primary and multiple secondaries represents a shard. Since MongoDB 4.4 secondaries can also be used to handle read requests by using the hedged read option.
To enable sharding, additional MongoDB node types are required: query routers (mongos) and config servers. A mongos instance acts as a query router, providing an interface between client applications and the sharded cluster. In consequence, clients never communicate directly with the shards, but always via the query router. Query routers are stateless and lightweight components that can be operated on dedicated resources or together with the client applications.
It is recommended to deploy multiple query routers to ensure the accessibility of the cluster because the query routers are the direct interface for the client drivers. There is no limit to the number of query routers, but as they communicate frequently with the config servers, it should be noted that too many query routers can overload the config servers. Config servers store the metadata of a sharded cluster, including state and organization for all data and components. The metadata includes the list of chunks on every shard and the ranges that define the chunks. Config servers need to be deployed as a replica set itself to ensure high availability.
Data sharding in MongoDB is done at the collection level, and a collection can be sharded based on a shard key. MongoDB uses a shard key to determine which documents belong on which shard. Common shard key choices include the _id field and a field with a high cardinality, such as a timestamp or user ID. MongoDB supports three sharding strategies: range based, hash based and zone based.
Ranged sharding partitions documents across shards according to the shard key value. This keeps documents with shard key values close to one another and works well for range-based queries, e.g. on time series data. Hashed sharding guarantees a uniform distribution of writes across shards, which favors write workloads. Zoned sharding allows developers to define custom sharding rules, for instance to ensure that the most relevant data reside on shards that are geographically closest to the application servers.
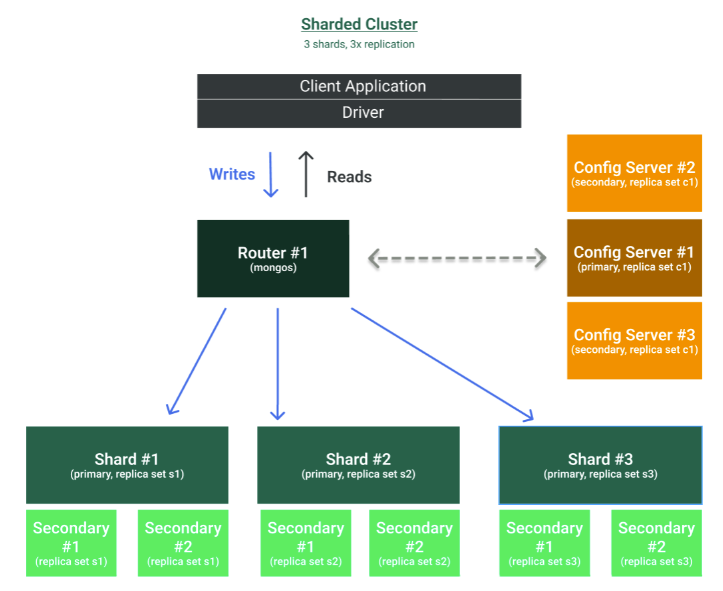
Also, sharded clusters can be deployed in a geo-distributed setup to overcome data center failures, as depicted in the following figure.
The ScyllaDB Architecture – Multi-Primary for High-Availability and Horizontal Scalability
Unlike MongoDB, ScyllaDB does not follow the classical RDBMS architectures with one primary node and multiple secondary nodes, but uses a decentralized structure, where all data is systematically distributed and replicated across multiple nodes forming a cluster. This architecture is commonly referred to as multi-primary architecture.
A cluster is a collection of interconnected nodes organized into a virtual ring architecture, across which data is distributed. The ring is divided into vNodes, which represent a range of tokens assigned to a physical node, and are replicated across physical nodes according to the replication factor set for the keyspace. All nodes are considered equal, in a multi-primary sense. Without a defined leader, the cluster has no single point of failure. Nodes can be individual on-premises servers, or virtual servers (public cloud instances) composed of a subset of hardware on a larger physical server. On each node, data is further partitioned into shards. Shards operate as mostly independently operating units, known as a “shared nothing” design. This greatly reduces contention and the need for expensive processing locks.
All nodes communicate with each other via the gossip protocol. This protocol decides in which partition which data is written and searches for the data records in the right partition using the indexes.
When it comes to scaling, ScyllaDB’s architecture is made for easy horizontal sharding across multiple servers and regions. Sharding in ScyllaDB is done at the table level, and a table can be sharded based on a partition key. The partition key can be a single column or a composite of multiple columns. ScyllaDB also supports range-based sharding, where rows are distributed across shards based on the partition key value range, as well as hash-based sharding for equally distributing data and to avoid hot spots.
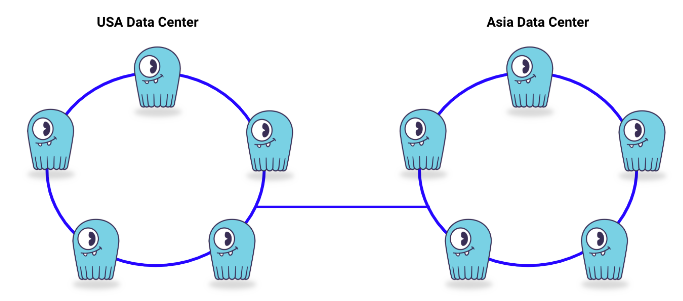
Additionally, ScyllaDB allows for data to be replicated across multiple data centers for higher availability and lower latencies. In this multi-data-center or multi-region setup, the data between data centers is asynchronously replicated.
On the client side, applications may or may not be aware of the multi datacenter deployment, and it is up to the application developer to decide on the awareness to fallback data-center(s). This can be configured via the read and write consistency options that define if queries are executed against a single data center or across all data centers. Load balancing in a multi datacenter setup depends on the available settings within the specific programming language driver.
A Comparative Scalability Viewpoint on the Distributed Architectures of MongoDB and ScyllaDB
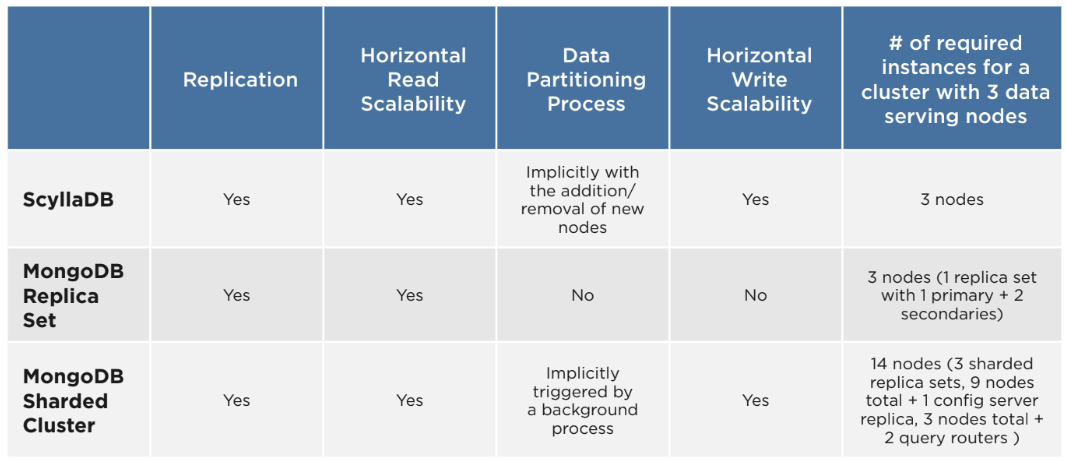
When it comes to scalability, the significantly different distribution approaches of both ScyllaDB and MongoDB need to be considered, especially for self-managed clusters running on-premises or on IaaS. MongoDB’s architecture easily allows scaling read-heavy workloads by increasing the number of secondaries in a replica set.
Yet, for scaling workloads with a notable write proportion, the replica sets need to be transformed into a sharded replica set and this comes with several challenges. First, two additional MongoDB services are required: n query routers (mongos) and a replica set of config servers to ensure high availability. Consequently, considerably more resources are required to enable sharding in the first place. Moreover, the operational complexity clearly increases. For instance, a sharded cluster with three shards requires a replica set of three mongos instances, a replica set of three config servers and three shards – each shard consisting of one primary and at least two secondaries.
The second challenge is the repartitioning of data in the sharded cluster. Here, MongoDB applies a constantly running background task that autonomously triggers the redistribution of data across the shards. The repartitioning does not take place as soon as a new shard is added to the cluster, but when certain internal thresholds are reached. Consequently, increasing the number of shards will immediately scale the cluster but may have a delayed scaling effect. Until MongoDB Version 5.0, MongoDB engineers themselves recommend to not shard, but rather to scale vertically with bigger machines if possible.
Scaling a ScyllaDB cluster is comparably easy and transparent for the user thanks to ScyllaDB’s multi-primary architecture. Here, each node is equal, and no additional services are needed to scale the cluster to hundreds of nodes. Moreover, data repartitioning is triggered as soon as a new node is added to the cluster. In this context, ScyllaDB offers clear advantages over MongoDB. First, thanks to the consistent hashing approach, data does not need to be repartitioned across the full cluster, only across a subset of nodes. Second, the partitioning starts with adding the new node, which eases the timing of the scaling action. This is important, since repartitioning will put some additional load on the cluster and should be avoided at peak workload phases.
The main scalability differences are summarized in the following table:
Conclusion and Outlook
When you compare two distributed NoSQL databases, you always discover some parallels, but also numerous considerable differences. This is also the case here with ScyllaDB vs MongoDB.
Both databases address similar use cases and have a similar product and community strategy. But when it comes to the technical side, you can see the different approaches and focus. Both databases are built for enabling high availability through a distributed architecture. But when it comes to the target workloads, MongoDB enables easily getting started with single node or replica set deployments that fit well for small and medium workloads, while addressing large workloads and data sets becomes a challenge due to the technical architecture.
ScyllaDB clearly addresses performance critical workloads that demand for easy and high scalability, high throughput, low and stable latency, and everything in a multi datacenter deployment. This is also shown by data intensive use cases of companies such Discord, Numberly or TRACTIAN that migrated from MongoDB to ScyllaDB to successfully solve performance problems.
And to provide further insights into their respective performance capabilities, we provide a transparent and reproducible performance comparison in a separate benchmark report that investigates the performance, scalability, and costs for MongoDB Atlas and ScyllaDB Cloud.
Additional ScyllaDB vs. MongoDB Comparison Details
See the complete benchANT MongoDB vs ScyllaDB comparison for an extended version of this technical comparison, including details comparing:
- Data model
- Query language
- Use cases and customer examples
- Data consistency options
- First-hand operational experience

