




Since 2019, ScyllaDB has been collaborating with the University of Warsaw by mentoring teams of students on their Bachelor’s theses. After the successful ScyllaDB Rust Driver, and the release of generics in Go 1.18 it was time for a new ScyllaDB Go driver to be born – with a goal of beating both GoCQL and ScyllaDB Rust Driver in terms of performance.
This blog will explain how the project succeeded in fulfilling this goal.
Focus: Performance, Performance, Performance
When designing the driver, we tried to make it follow ScyllaDB’s shared-nothing approach as much as possible, avoiding unnecessary mutex use for taking ownership of data, and focusing on clear, efficient communication between components using idiomatic Go channels and atomics.
This led to the new driver having just one mutex, local to a single TCP connection. For comparison, gocql uses them a lot, making it hard to make a larger change without creating an accidental data race.
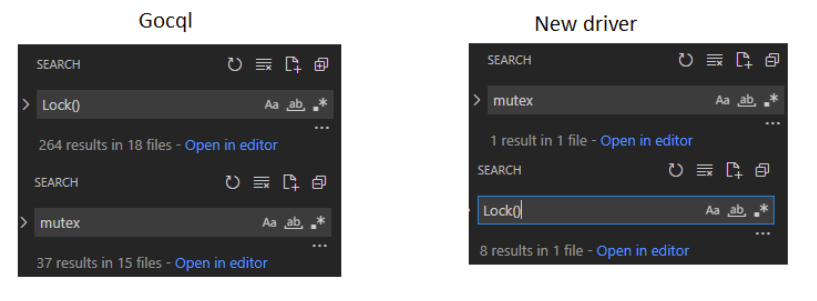
We also paid close attention to proper memory management, producing as little garbage as possible. During benchmarking, we observed that GoCQL results were heavily influenced by the garbage collector. With the default GOGC, it performed up to 30% slower than with optimal settings.
We are happy to announce that the garbage collector’s influence on the new driver is negligible, mostly due to the driver performing memory allocations 5x less often than GoCQL.
When creating new components, we performed various microbenchmarks to make the right decisions performance-wise.
Let’s dive deeper into how the driver works and why it’s monstrously fast.
Connection Architecture
Connection is likely the most crucial part of the driver’s performance, similar to the Rust driver. In the new Go driver, it consists of two parts:
- Writer loop – responsible for sending requests
- Reader loop – responsible for receiving and dispatching responses
The request lifetime in the new driver is as follows:
- Create a request
- Pick a connection that will perform the request
- Allocate a StreamID along with a response channel for the frame
- Send it through a channel to Writer loop
- Writer loop serializes and sends the frame to ScyllaDB, possibly coalescing it with other frames waiting to be sent on the writer’s channel
- Reader loop receives the response frame from ScyllaDB, deserializes it, and sends the result through a response channel corresponding to frame’s StreamID, freeing it
Frames are (de)serialized in buffers owned by the reader/writer, allowing reuse of memory between requests on a single connection.
This way the writer and reader loops have minimal overhead and can focus entirely on pushing frames through the network, without the need for excessive synchronization.
Benchmarking
To measure the driver’s performance, we used last year’s driver benchmark. Here are results of running that benchmark’s variant:
- Perform 10 million Inserts and Selects on the same table, evenly distributed over 1024 concurrent workers
Take a look at the flamegraph from the first time that we started profiling and optimizing the driver.

Before any optimizations
Benchmark total time: 50.21s / 100%
syscall.Write total time: 18.20s / 36.25%
Coalescing
Benchmarks showed that even though we were coalescing requests, the driver still spent nearly half of its runtime waiting on system calls, mostly in the writer’s loop (as you can see on the flame graph above).
The reason for this was that, even under heavy load, coalescing all awaiting requests would not fill the whole connection buffer. In fact, most of the time a flush was happening with every request, even though you could fit over 100 queries in the buffer.
A desired case would be to flush the buffer when it’s full. As the requests should reach the database as soon as they can, it is acceptable to wait for the buffer to fill up every time.
We could, however, wait for a fixed, unnoticeable amount of time for the requests to pile up before coalescing them. Below is a flamegraph of the driver benchmark with a coalescing pile-up time of 1 millisecond.
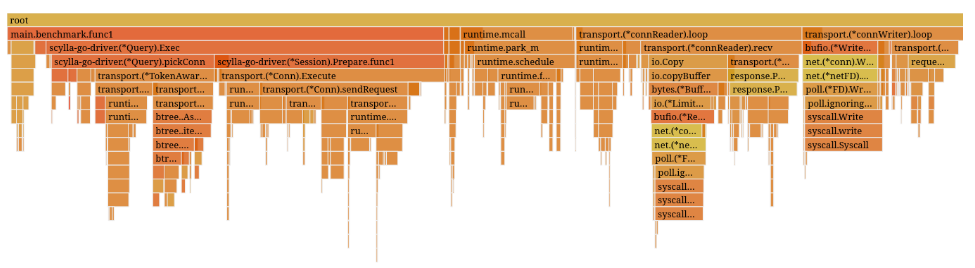
Benchmark total time: 22.03s / 100%
syscall.Write total time: 1.65s / 7.48%
As you can see above, this optimization doubled the driver’s performance on the benchmark, leading to even lower average latency despite the additional wait. You can read more details about this idea here.
Faster Routing
A very important feature of a driver is routing queries to the right nodes, performing load balancing, and retrying the queries to other nodes in some cases.
Following other drivers’ footsteps in terms of how we approach query routing, we also wanted to use an API where for each query we can ask for a query plan: an iterator function returning nodes in the order in which we should query them.
Profiling has shown that the driver performed a lot of small allocations of memory for iterators produced by this approach. As you can see on the flame graph below, allocations (e.g. runtime.newobject) take up about a third of the picking connections runtime.
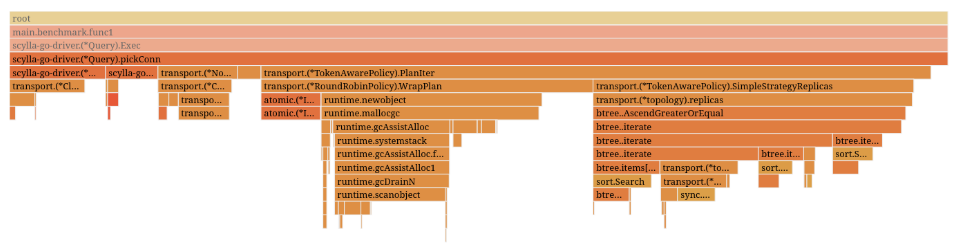
Benchmark total time: 22.03s / 100%
Picking connection total time: 3.76s / 17.06%
Trying to improve the performance of picking a connection, we first made improvements to Go’s BTree library. We adapted it to use generics, which made the allocations less impactful — you can read about it in this blog on Shaving 40% Off Google’s B-Tree Implementation with Go Generics. However, we came up with an even better idea — removing those allocations completely.
The key idea was that there are not so many different query plans, and most of the time we need only the first element of the plan, so we could preprocess them completely.
Instead of making plans on the fly, the new driver preprocesses them all when it registers changes in the cluster’s topology. Also, instead of generating a whole plan iterator for a query, it fetches only the nodes it needs.
This way we spend a tiny bit more time during topology refresh, for a notable decrease in the latency of sending a request. And what’s more important: we avoid the garbage collector.

Benchmark total time: 21.24s / 100%
Picking connection total time: 1.60s / 7.55%
Comparison and Future Plans
To compare the drivers, we first tried benchmarks on last year’s setup:
- Loader: c5.9xlarge (36vCPU, 96GiB memory)
- ScyllaDB: 3 instances running on i3.4xlarge (16vCPU, 122GiB memory)
However, test runs showed that the new driver was able to push ScyllaDB to maximum load with just 60% load on the loader. To make sure that the benchmark would be fair, we decided to use a smaller loader, and the more powerful EC2 instances for ScyllaDB listed below:
- Loader: c5n.2xlarge (8vCPU, 21GiB memory)
- ScyllaDB: 3 instances running on i3.8xlarge (32vCPU, 244GiB memory)
- Benchmark: Insert 100 million rows concurrently, evenly distributed across workers.
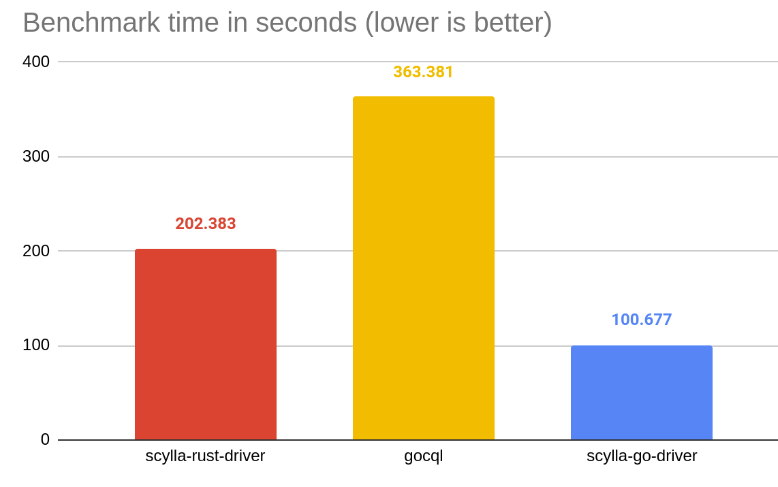
It turns out that the new Go driver is almost 4x faster than its predecessor and 2X faster than its Rust counterpart.
Let’s take a look at the results in terms of throughput (higher is better).
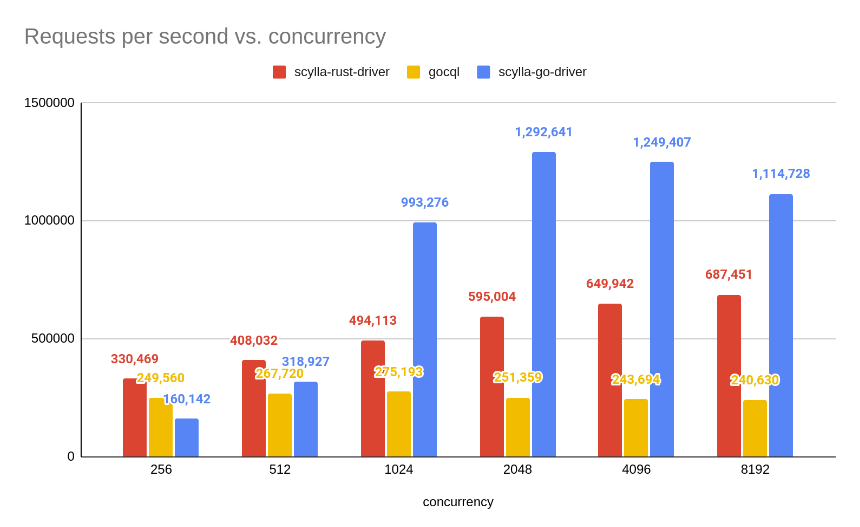
In comparison to other drivers, the new driver’s throughput scales much faster with increasing concurrency, reaching its peak around ~2000 concurrently running workers achieving a whopping ~1.3 million inserts per second.
The big difference between our Rust and Go drivers comes from coalescing; however, even with this optimization disabled in the Go driver, it’s still a bit faster.
Let’s see the latencies on those requests (lower is better):
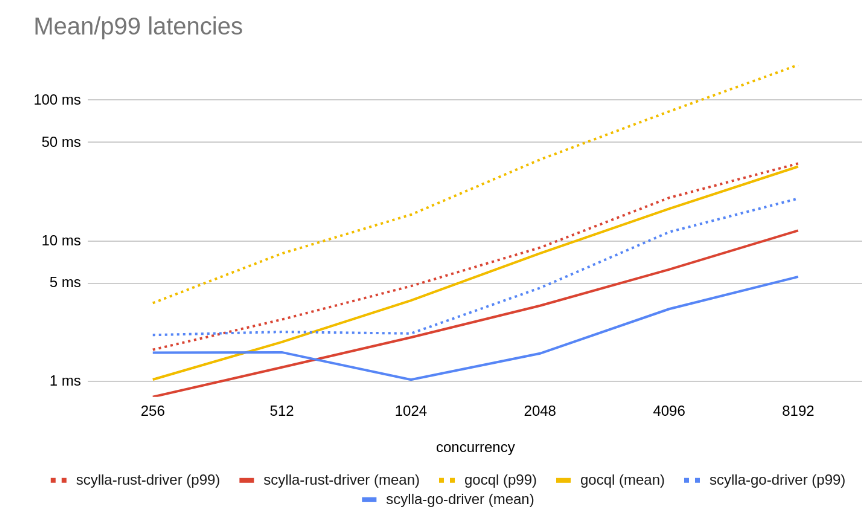
On the latency graph, you can clearly see that when the concurrency is high, the new driver shines with 2X lower average latency than other competitors and a much lower P99 latency than Gocql in all cases. However, in the case of lower concurrency, it is a bit slower due to the fixed coalescing wait. This will be improved in the future.
We also collected various metrics during the benchmark using bpftrace tools. These metrics clearly indicate that the driver gets the most out of each syscall and every memory allocation.
Disclaimer: Those results don’t take into account the overhead of profiling; in reality, they might be a bit higher.
| scylla-go-driver | gocql | rust | |
| syscalls per insert | 0.4664544279 | 0.8111697133 | 0.8969300866 |
| mallocs per insert | 0.682831517 | 3.442205618 | 0.9112366758 |
| median tcp packet size | [512, 1K) | [128,256) | [64,128) |
Wrap Up
Thanks to early design goals, extensive profiling, and benchmarking, we created a new ScyllaDB Go driver that performs great in a high concurrency environment, outclassing its predecessor in terms of runtime and memory management, and showing promise to replace it someday.
The driver is available on GitHub, though it is still in the early stages of development. Feel free to check it out and contribute.
You can also check out our bachelor’s thesis for more details about how the driver was developed.


