





Earlier this year, we compared ScyllaDB 4.4.3’s performance on early-access instances of AWS’s storage-optimized I4i instances for IO-heavy workloads. Running ScyllaDB 4.4.3 on both the i4i.16xlarge and i3.16xlarge, we observed up to 2.7x higher throughput per vCPU for reads. With an even mix of reads and writes, we observed 2.2x higher throughput per vCPU on the new i4i series, with a 40% reduction in average latency than I3 instances. [Read the results from this i4i.16xlarge benchmark].
Since then, the complete family of I4i instances went into general availability – opening up access to the i4i.4xlarge instances that are closely related to the i3.4xlarge instances used in our recent ScyllaDB vs Cassandra benchmarks and our general ScyllaDB vs Cassandra page. Also, a major new release of ScyllaDB went to general availability with performance optimizations such as a new IO scheduler that’s optimized for mixed read/write workloads.
Curious to quantify the combined performance impact of the new I4is plus ScyllaDB’s latest performance optimizations, we recently kicked off a new series of benchmarks. This blog shares the first results from that project: ScyllaDB Open Source 5.0 on i4i.4xlarge vs. ScyllaDB 4.4.3 on the i3.4xlarge we used in previous benchmarks. We are working on expanding these benchmarks – stay tuned to our blog for additional comparisons and findings.
What’s So Interesting About the AWS I4i Instances?
The new I4i instances are powered by the latest generation Intel Xeon Scalable (Ice Lake) Processors with an all-core turbo frequency of 3.5 GHz. Compare this to the I3’s Intel Xeon E5-2686 v4 (Broadwell) @ 2.3 GHz (2.7 GHz). Moreover, they use AWS’s directly-attached, NVMe-based Nitro SSD devices that were designed to minimize latency and maximize transactions per second. AWS found that they offer up to 30% better compute price performance, 60% lower storage I/O latency, and 75% lower storage I/O latency variability compared to I3 instances. Another difference: there’s also a new, larger instance size (i4i.32xlarge) that features 2x the RAM of the i3.metal as well as 2x the SSD — a whopping 128 vCPUs backed by a terabtye of RAM and 30 terabtyes of storage per node.
Here are the I4i technical specs:
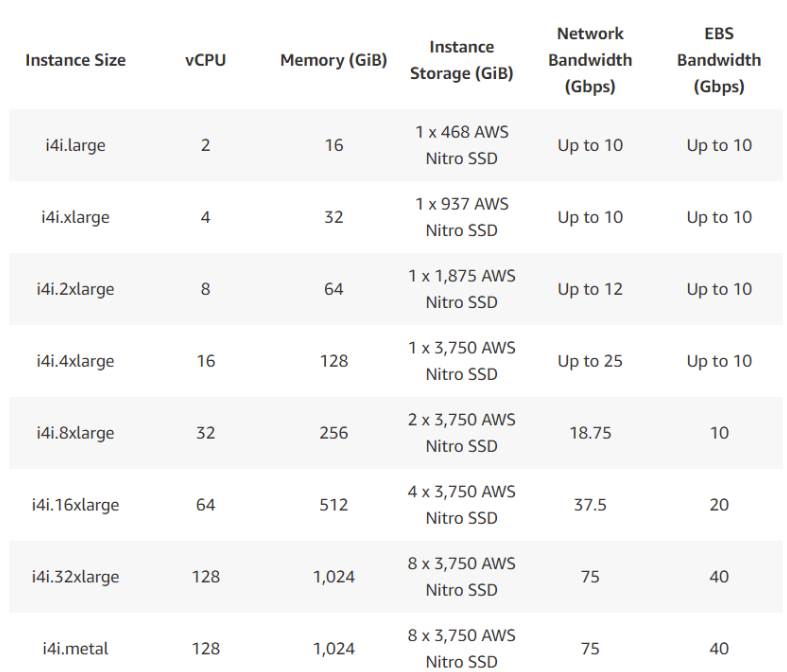
Our Setup
The benchmarking was a series of simple invocations of Cassandra-stress with CL=QUORUM. The procedure was:
- Set up the cluster from intact AMIs and spin up powerful loaders.
- Load the cluster with 3TB of data.
- Warm up the cache by ~3 hours of reads.
- Apply the data distributions (described below) in gradual increments of 10k ops/s.
- Stop when p90 latency exceeds 1000 ms.
See the earlier ScyllaDB vs Cassandra benchmark for all the setup details
For this round of benchmarking, we ran a total of 10 scenarios spanning different data distributions and workloads. The data distributions used were:
- Uniform distribution, with a close-to-zero cache, hit ratio
- “Real-life” (Gaussian) distribution, with sensible cache-hit ratios of ~30%
The workloads were read only, write only, and mixed (50% read, 50% write). For each of these 3 variations, we ran disk-intensive workloads as well as memory-intensive workloads (e.g., the entire dataset could fit in RAM).
Benchmark Results: i4i.4xlarge vs i3.4xlarge
Here’s a summary of the results (maximum throughput in k/s with single-digit ms P99 latencies).
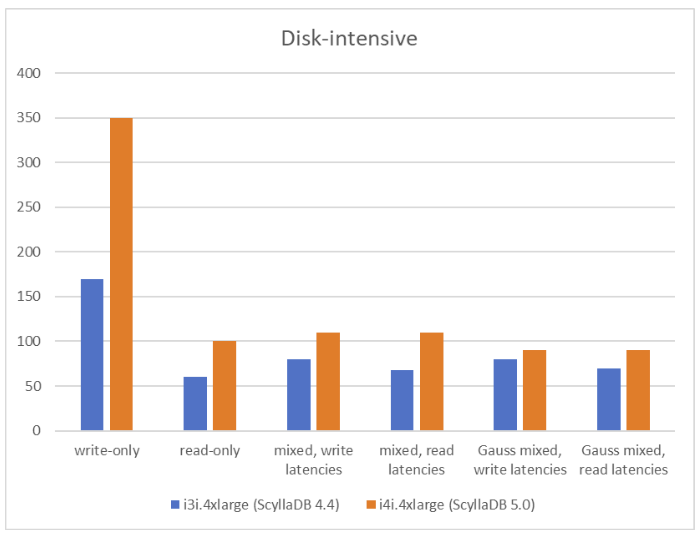
Disk-intensive write-only workload
With a disk-intensive workload of 100% writes, ScyllaDB 5.0 on the i4i achieved 2X (100%) greater throughput with single-digit ms P99 latencies: 350k vs 170k.
Disk-intensive read-only workload
For 100% reads, ScyllaDB 5.0 on the i4i achieved 67% greater throughput with single-digit ms P99 latencies: 100k vs 60k.
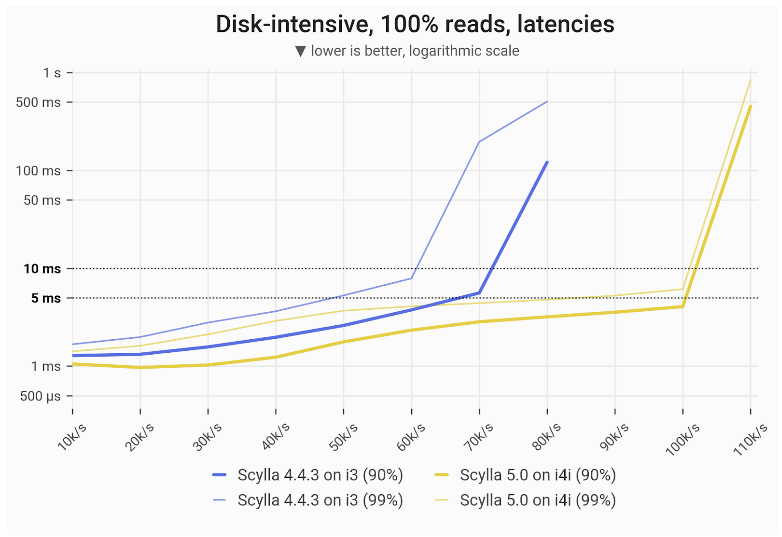
Disk-intensive mixed workload – write latencies
With a 50% read / 50% write workload, ScyllaDB 5.0 on the i4i achieved 37% greater throughput with single-digit ms P99 latencies for writes: 110k vs 80k.
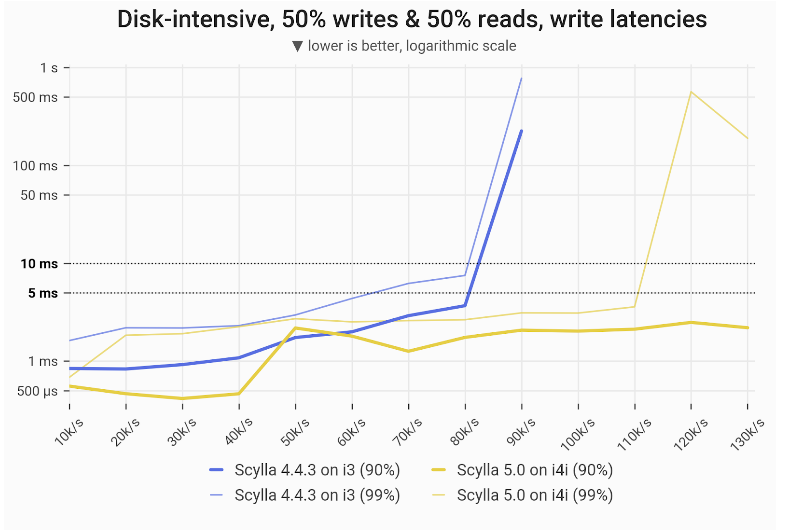
Disk-intensive mixed workload – read latencies
With a 50% read / 50% write workload, ScyllaDB 5.0 on the i4i achieved 62% greater throughput with single-digit ms P99 latencies for reads: 110k vs 68k.
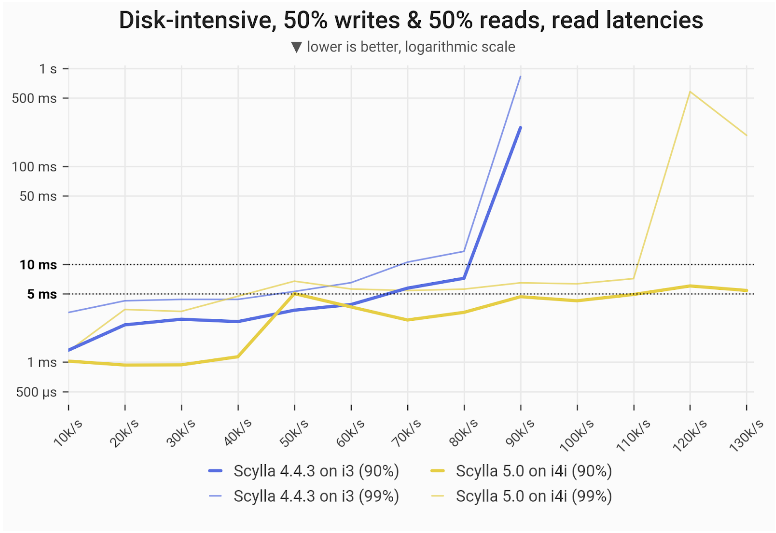
Disk-intensive Gaussian mixed workload – write latencies
With the Gaussian distribution mixed workload, ScyllaDB 5.0 on the i4i achieved 12.5% greater throughput with single-digit ms P99 latencies for writes: 90k vs 80k.
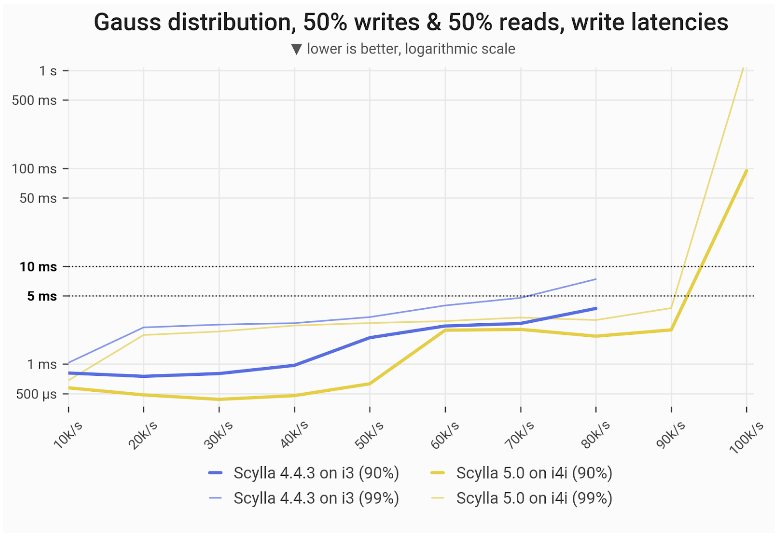
Disk-intensive Gaussian mixed workload – read latencies
With the Gaussian distribution mixed workload, ScyllaDB 5.0 on the i4i achieved 28% greater throughput with single-digit ms P99 latencies for reads: 90k vs 70k.
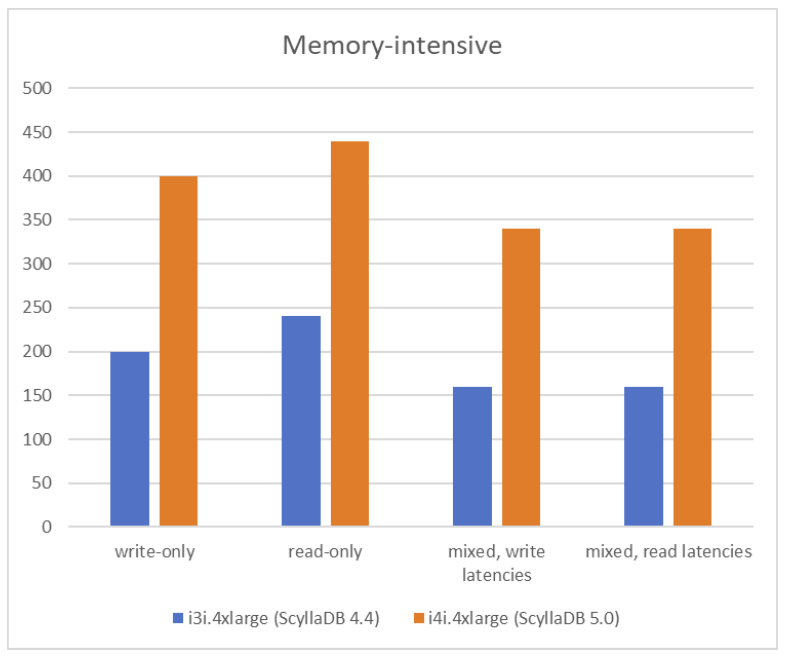
Memory-intensive write-only workload
Now, over to the memory-intensive workloads, where the entire dataset could fit in RAM.
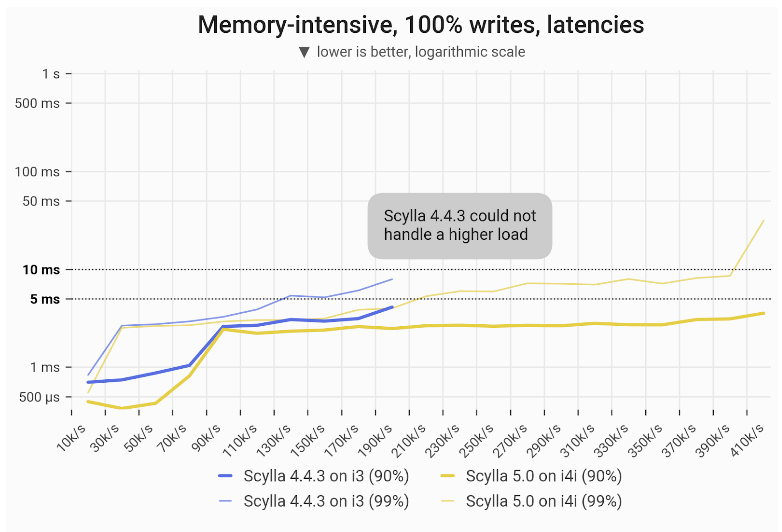
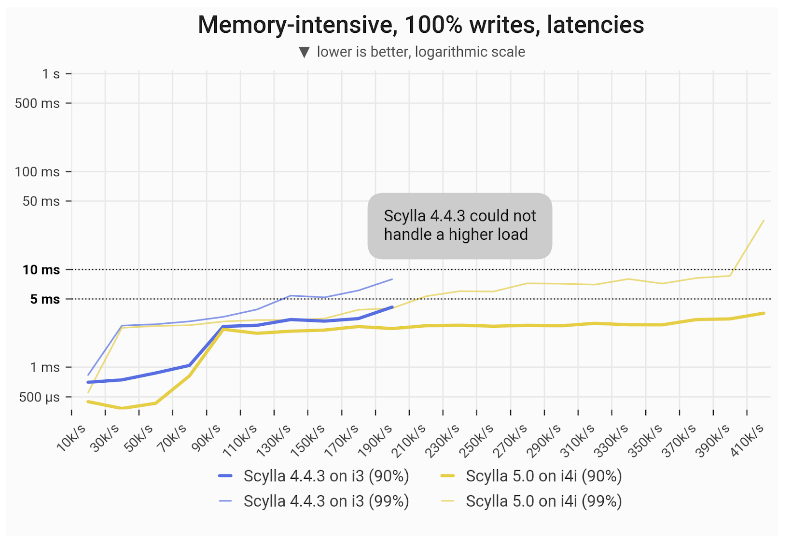
With a disk-intensive workload of 100% writes, ScyllaDB 5.0 on the i4i achieved 2X (100%) greater throughput with single-digit ms P99 latencies: 400k vs 200k. This 2X improvement in throughput matches the gain from the disk-intensive write-only workload.
Memory-intensive read-only workload
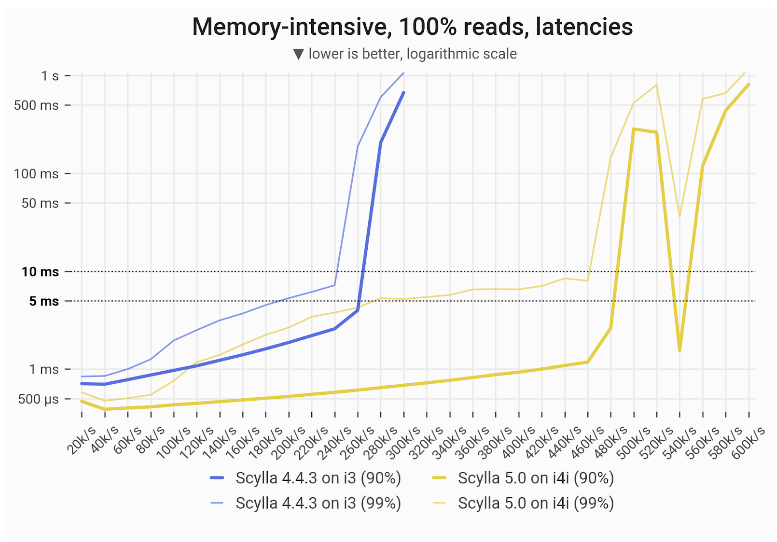
For 100% reads, ScyllaDB 5.0 on the i4i achieved 83% greater throughput with single-digit ms P99 latencies: 440k vs 240k.
Memory-intensive mixed workload – write latencies
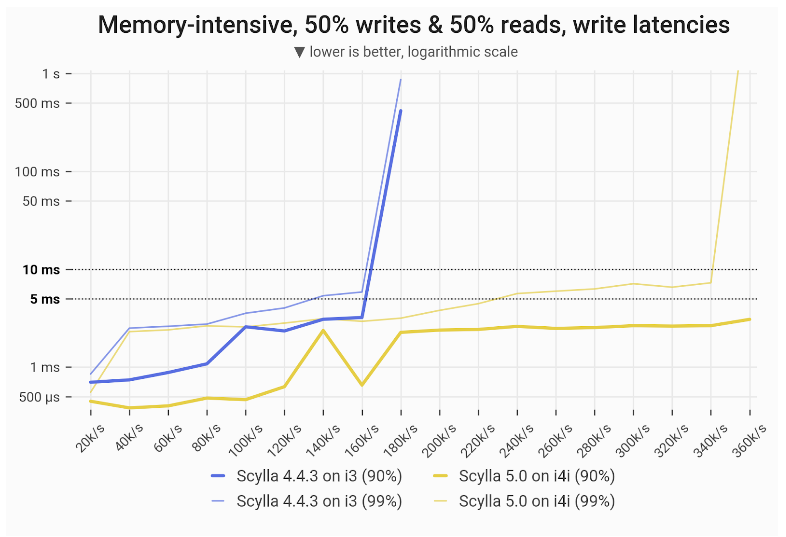
With a 50% read / 50% write workload, ScyllaDB 5.0 on the i4i achieved 112% greater throughput with single-digit ms P99 latencies for writes: 340k vs 160k.
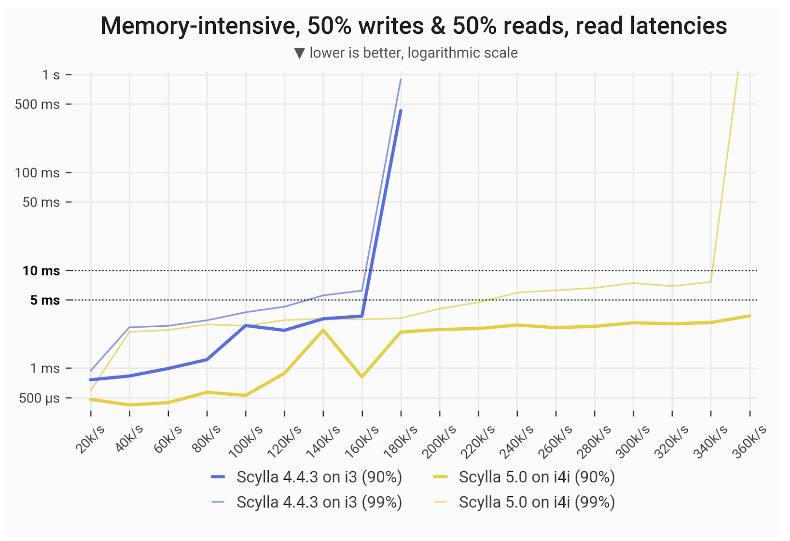
Memory-intensive mixed workload – read latencies
With a 50% read / 50% write workload, ScyllaDB 5.0 on the i4i achieved 112% greater throughput with single-digit ms P99 latencies for reads: 340k vs 160k.
Surprising Latencies for Administrative Operations
Finally, we measured the latencies during “Add Node” and “Major Compaction” operations. We used 3x i4i.4xlarge for “Add Node,” 1x i4i.4xlarge for “Major Compaction, ScyllaDB 5.0, ~50% ScyllaDB load of background workload, and mixed disk-intensive workload. We aimed at 30% CPU load but overshot.
Here are the results for adding a node:
| Write latency (in ms) | Read latency (in ms) | |
| Mean | 1.17 | 2.41 |
| p90 | 2.28 | 4.41 |
| p99 | 2.72 | 5.52 |
And here are the results for major compaction:
| Write latency (in ms) | Read latency (in ms) | |
| Mean | 1.11 | 3.79 |
| p90 | 1.35 | 5.21 |
| p99 | 1.52 | 6.06/span> |
Yes – compaction unexpectedly improved the P99 write latencies ever so slightly. There are cases where it’s better for ScyllaDB to process data than to go back to the idle loop.
Final Thoughts
Of course, your mileage will vary. We strongly encourage you to perform your own benchmarks with your own workloads. In the meantime, we’ll be performing more benchmarking as well.
We want to delve into some of the more interesting results (for example the discrepancy across the read and write latencies on the Gaussian distribution and the dip in read latencies for the memory-intensive workload). Additionally, we want to compare ScyllaDB’s performance on I4is vs that of other databases. We are also considering more matchups like our “4 x 40” benchmark: ScyllaDB on 4 nodes vs. Cassandra on 40 nodes.


