Introduction
Being a large datastore, ScyllaDB operates many internal activities competing for disk I/O. There are data writers (for instance memtable flushing code or commitlog) and data readers (which are most likely fetching the data from the SSTables to serve client requests). Beyond that, there are background activities, like compaction or repair, which can do I/O in both directions. This competition is very important to tackle; otherwise just issuing a disk I/O without any fairness or balancing consideration, a query serving a read request can find itself buried in the middle of the pile of background writes. By the time it has the opportunity to run, all that wait would have translated into increased latency for the read.
While keeping the in-disk concurrency at a reasonably high level to utilize disk internal parallelism, it is then better for the database not to send all those requests to the disk in the first place, and keep them queued inside the database. Being inside the database, ScyllaDB can then tag those requests and through prioritization guarantee quality-of-service among various classes of I/O requests that the database has to serve: CQL query reads, commitlog writes, background compaction I/O, etc.
That being said, there’s a component in the ScyllaDB low-level engine called the I/O scheduler that operates several I/O request queues and tries to maintain a balance between two inefficiencies — overwhelming the disk with requests and underutilizing it. With the former, we achieve good throughput but end up compromising latency. With the latter, latency is good but throughput suffers. Our goal is to find the balance where we can extract most of the available disk throughput while still maintaining good latency.
Current State / Previous Big Change
Last time we touched this subject, it was about solving the disk throughput and IOPS capacity being statically partitioned between shards. Back then, the challenge was to make correct accounting and limiting of a shared resource constrained with the shard-per-core design of the library.
A side note: Seastar uses the “share nothing” approach, which means that any decisions made by CPU cores (often referred to as shards) are not synchronized with each other. In rare cases, when one shard needs the other shard’s help, they explicitly communicate with each other.
The essential part of the solution was to introduce a shared pair of counters that helped to achieve two goals: prevent shards from consuming more bandwidth than a disk can provide and also act as a “reservation” when each shard could claim the capacity, and wait for it to become available if needed — all in a “fair” manner.
Just re-sorting the requests, however, doesn’t make the I/O scheduler a good one. Another essential part of I/O scheduling is maintaining the balance between queueing and executing requests. Understanding what overwhelms the disk and what doesn’t turns out to be very tricky.
Towards Modeling the Disk
Most likely when evaluating a disk one would be looking at its 4 parameters — read/write IOPS and read/write throughput (such as in MB/s). Comparing these numbers to one another is a popular way of claiming one disk is better than the other and estimating the aforementioned “bandwidth capacity” of the drive by applying Little’s Law. With that, the scheduler’s job is to provide a certain level of concurrency inside the disk to get maximum bandwidth from it, but not to make this concurrency too high in order to prevent disk from queueing requests internally for longer than needed.
In its early days ScyllaDB took this concept literally and introduced the configuration option to control the maximum amount of requests that can be sent into the disk in one go. Later this concept was elaborated taking into account the disk bandwidth and the fact that reads and writes come at different costs. So the scheduler maintained not only the “maximum number of requests” but also the “maximum number of bytes” sent to the disk and evaluated these numbers differently for reads vs writes.
This model, however, didn’t take into account any potential interference read and write flows could have on each other. The assumption was that this influence should be negligible. Further experiments on mixed I/O showed that the model could be improved even further.
The Data
The model was elaborated by developing a tool, Diskplorer, to collect a full profile of how a disk behaves under all kinds of load. What the tool does is load the disk with reads and writes of different “intensities” (including pure workloads, when one of the dimensions is literally zero) and collects the resulting latencies of requests. The result is 5-dimension space showing how disk latency depends on the { read, write } x { iops, bandwidth } values. Drawing such a complex thing on the screen is challenging by itself. Instead, the tool renders a set of flat slices, some examples of which are shown below.
For instance, this is how read request latency depends on the intensity of small reads (challenging disk IOPS capacity) vs intensity of large writes (pursuing the disk bandwidth). The latency value is color-coded, the “interesting area” is painted in cyan — this is where the latency stays below 1 millisecond. The drive measured is the NVMe disk that comes with the AWS EC2 i3en.3xlarge instance.
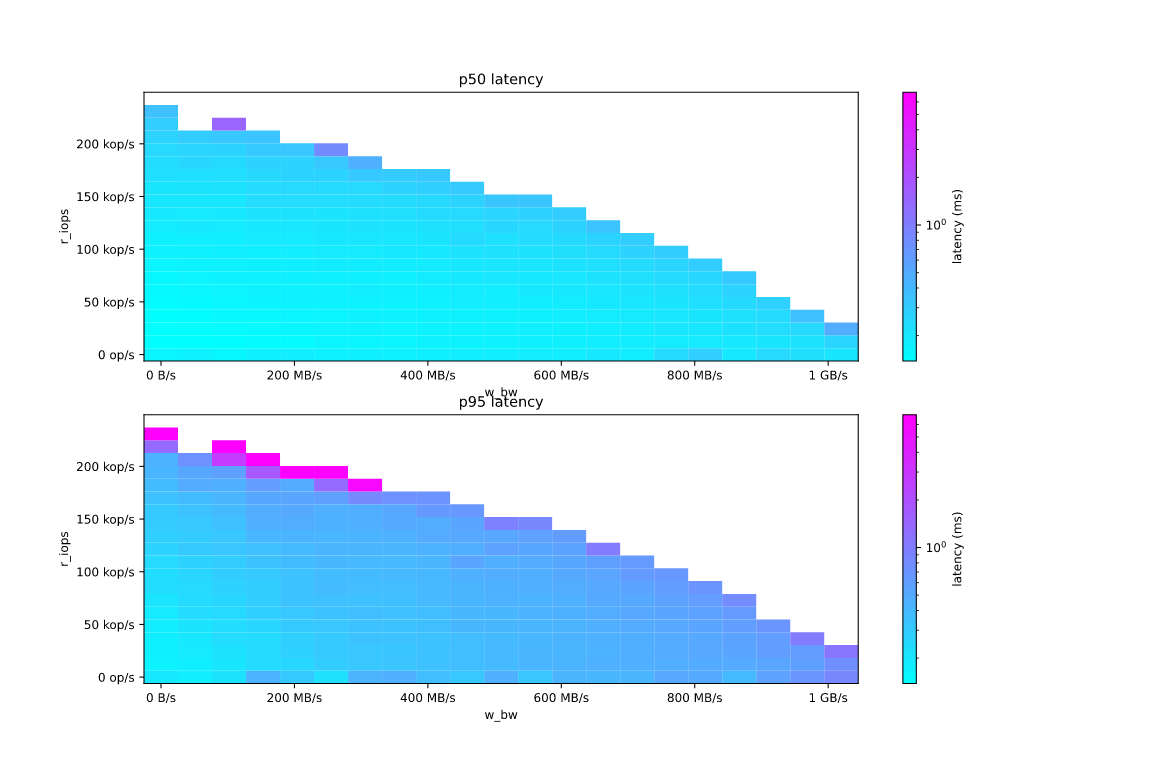
This drive demonstrates almost perfect half-duplex behavior — increasing the read intensity several times requires roughly the same reduction in write intensity to keep the disk operating at the same speed.
Similarly this is what the plot looks like for yet another AWS EC2 instance — the i3.3xlarge.
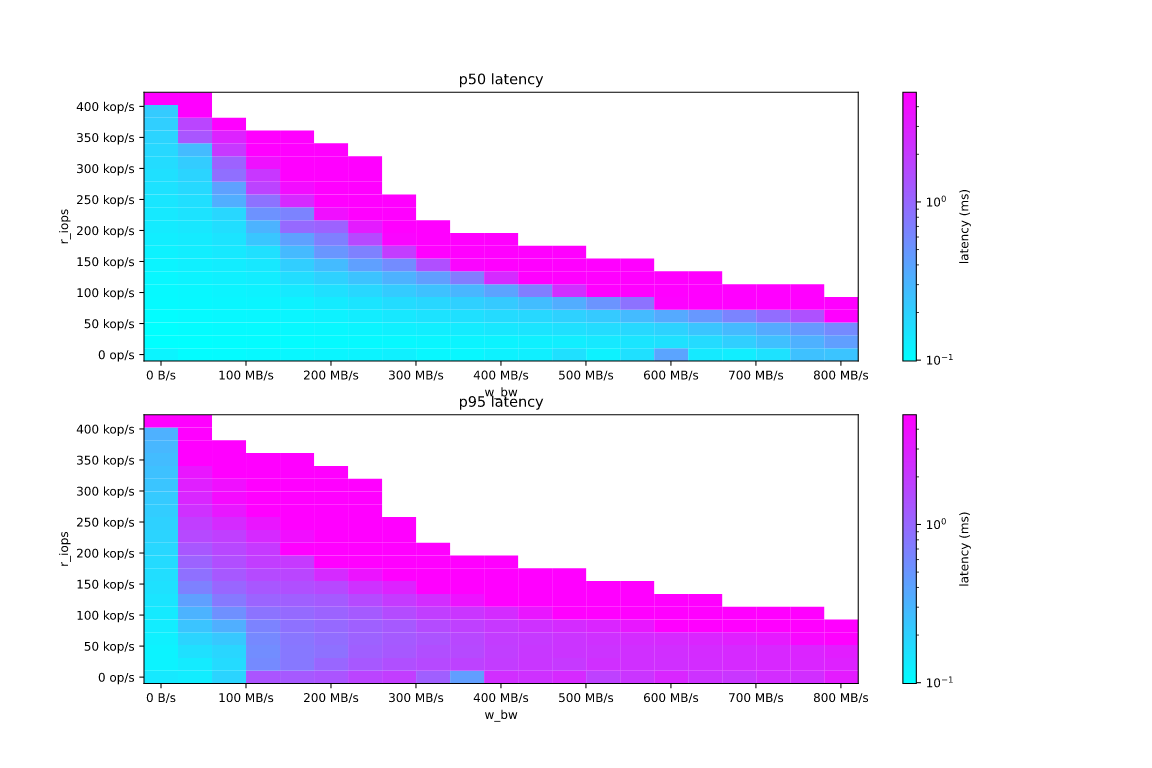
This drive demonstrates less than perfect, but still half-duplex behavior. Increasing reads intensity needs writes to slow down much deeper to keep up with the required speeds, but the drive is still able to maintain the mixed workload.
Less relevant for ScyllaDB, but still very interesting is the same plot for some local HDD. The axis and coloring are the same, but the scale differs, in particular, the cyan outlines ~100 milliseconds area.
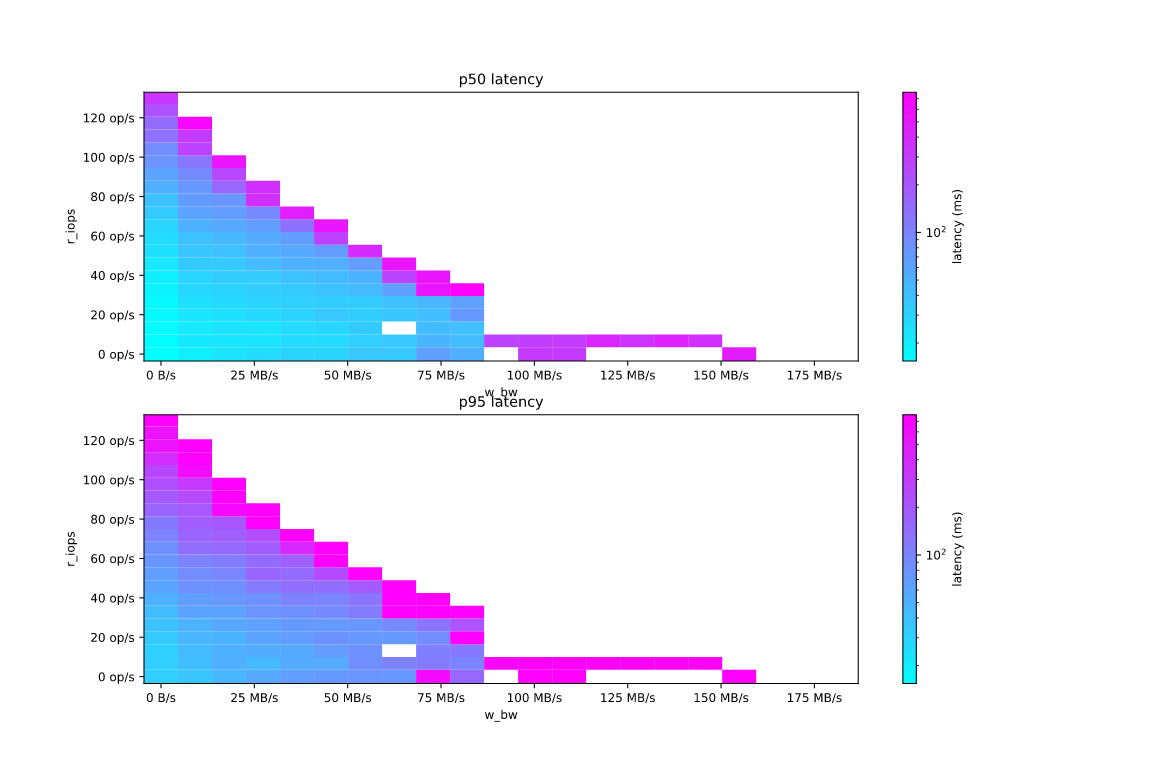
This drive is also half-duplex, but with write bandwidth above ~100MB/s the mixed workload cannot survive, despite a pure write workload being pretty possible on it.
It’s seen that the “safety area” when we can expect the disk request latency to stay below a value we want is a concave triangular-like area with its vertices located at zero and near disk’s maximum bandwidth and IOPS.
The Math
If trying to approximate the above plots with a linear equation, the result would be like this
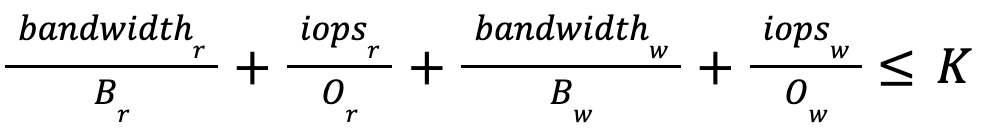
Where Bx are maximum read and write bandwidth values, Ox are the maximum IOPS values, and K is the constant with the exact value taken from the collected profile. Taking into account that bandwidth and IOPS are both time derivative of the respective bytes and ops numbers, i.e.
| and |
and introducing relations between maximum bandwidth and IOPS values
![]()
the above equation turns into some simpler form of
![]()
Let’s measure each request with a two-values tuple T = {1, bytes} for reads and T = {Mo, Mb · bytes} for writes and define the normalization operation to be
![]()
Now the final equation looks like
![]()
Why is it better or simpler than the original one? The thing is that measuring bandwidth (or IOPS) is not simple. If you look at any monitoring tool, be it a plain Linux top command or sophisticated Grafana stack, you’ll find that all such speedish values are calculated within some pre-defined time-frame, say 1 second. Limiting something that’s only measurable with a certain time gap is an even more complicated task.
In its final form, the scheduling equation has the great benefit — it needs to accumulate some instant numerical values — the aforementioned request tuples. The only difficulty here is that the algorithm should limit not the accumulated value itself, but the speed at which it grows. This task has its well known solution.
The Code
There’s a well developed algorithm called token bucket out there. It originates from telecommunications and networking and is used to make sure that a packet flow doesn’t exceed the configured rate or bandwidth.
In its bare essence, the algorithm maintains a bucket with two inputs and one output. The first input is the flow of packets to be transmitted. The second input is the rate-limited flow of tokens. Rate-limited here means that unlike packets that flow into the bucket as they appear, tokens are put into a bucket with some fixed rate, say N tokens per second. The output is the rate-limited flow of packets that had recently arrived into the bucket. Each outgoing packet carries one or more tokens with it and the number of tokens corresponds to what “measure” is rate-limited. If the token bucket needs to ensure the packets-per-second rate, then each packet takes away one token. If the goal is to limit the output for bytes-per-second, then each packet must carry as many tokens as many bytes its length is.
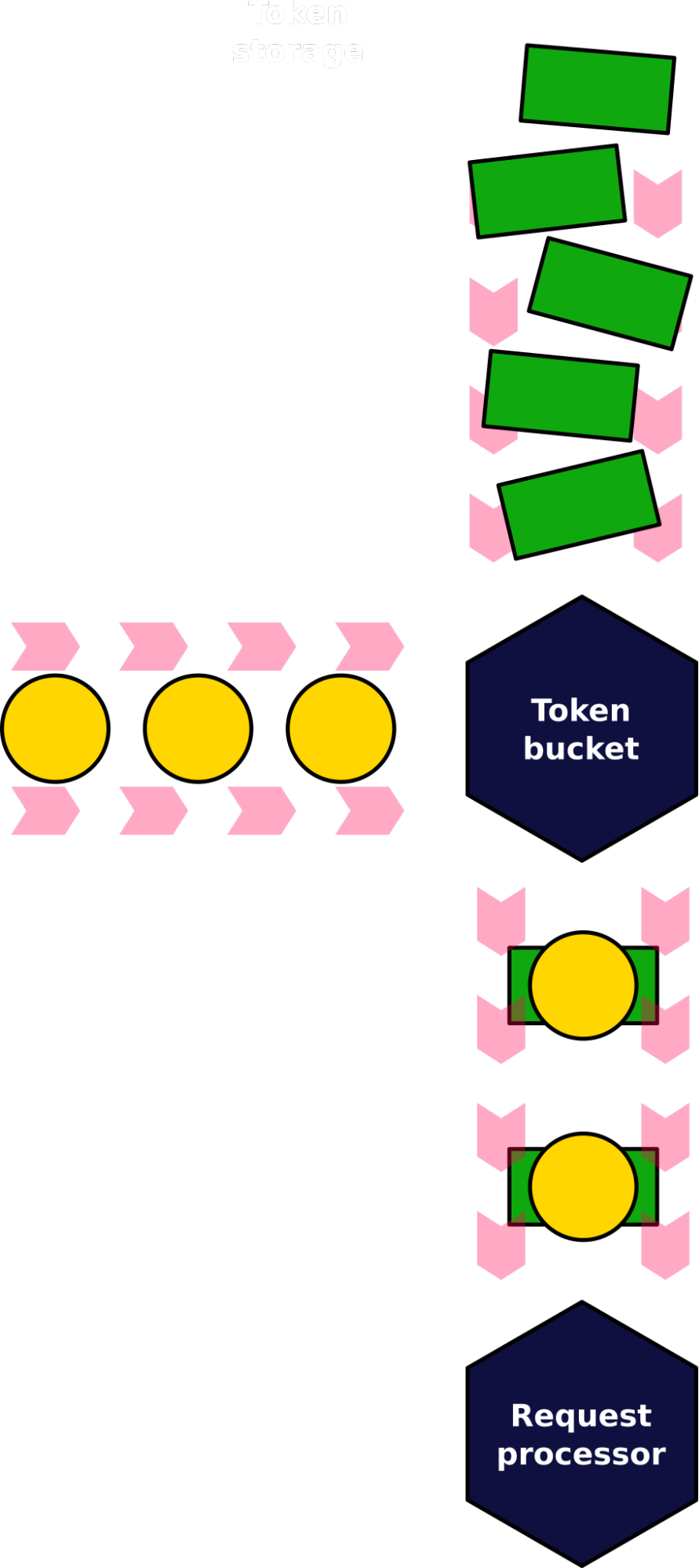
This algorithm can be applied to our needs. Remember, the goal is to rate-limit the outgoing requests’ normalized cost-tuples. Respectively, each request is only dispatched when it can get N(T) tokens with it, and the tokens flow into the bucket with the rate of K.
In fact, the classical token bucket algo had to be slightly adjusted to play nicely with the unpredictable nature of modern SSDs. The thing is that despite all the precautions and modeling, disks still can slow down unexpectedly. One of the reasons is background garbage collection performed by the FTL. Continuing to serve IOs at the initial rate into the disk running its background hygiene should be avoided as much as possible. To compensate for this, we added a backlink to the algorithm — tokens that flow into the bucket to not appear from nowhere (even in the strictly rate-limited manner), instead they originate from another bucket. In turn, this second bucket gets its tokens from the disk itself after requests complete.
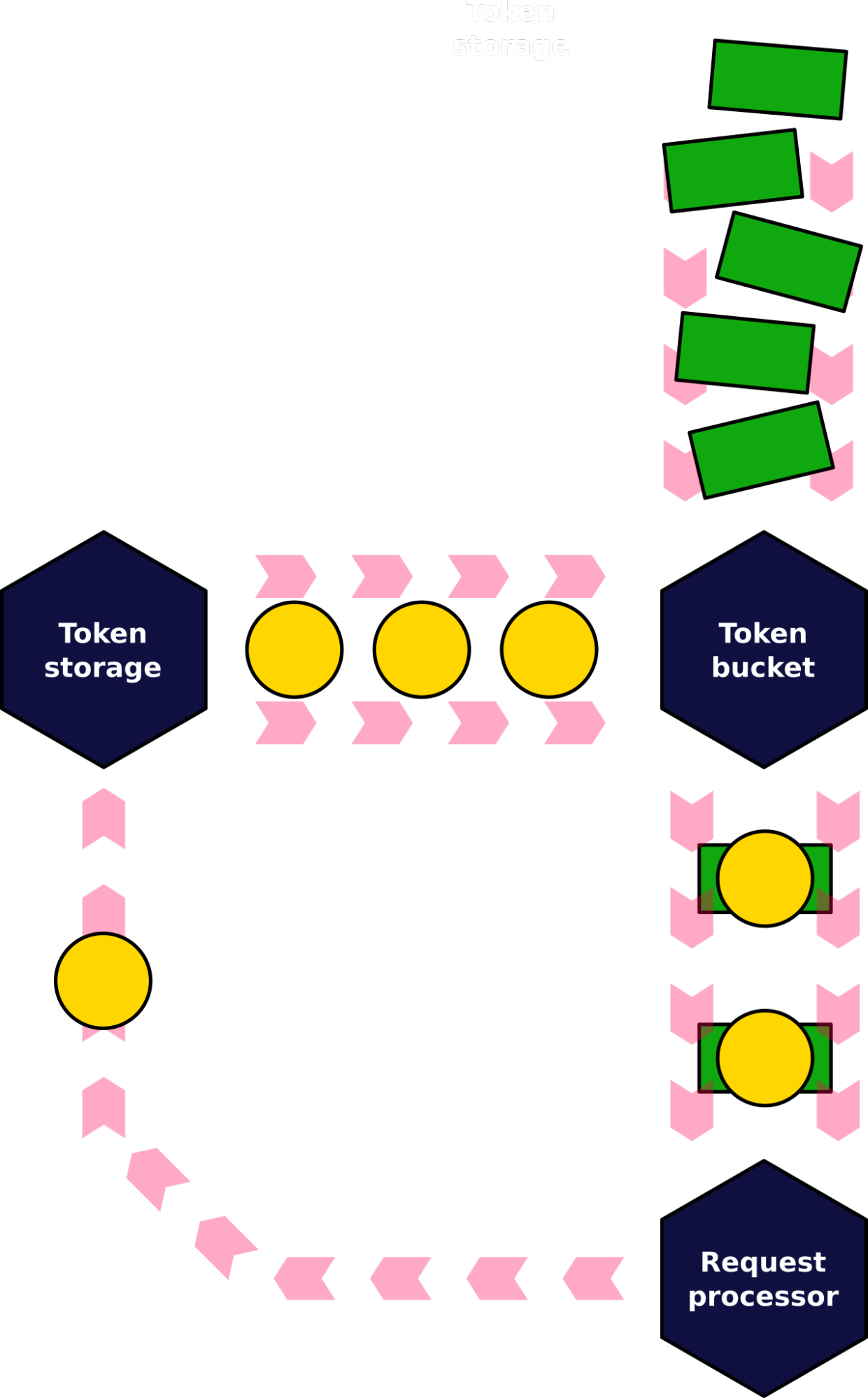
The modified algorithm makes sure the I/O scheduler serves requests with a rate that doesn’t exceed two values — the one predicted by the model and the one that the disk shows under real load.
Results
The results can be seen from two angles. First, is whether the scheduler does its job and ensures the bandwidth and IOPS stay in the “safety area” from the initial profile measurements. Second, is whether this really helps, i.e. does the disk show good latencies or not. To check both we ran a cassandra stress test over two versions of ScyllaDB — 4.6 with its old scheduler and 5.0 with the new one. There were four runs in a row for each version — the first run was to populate ScyllaDB with data, and subsequent to query this data back, but “disturbed” with background compaction (because we know that ordinary workload is too easy for modern NVMe disk to handle). The querying was performed with different rates of client requests — 10k, 5k and 7.5k requests per second.
Bandwidth/IOPS Management
Let’s first look at how the scheduler maintains I/O flows and respects the expected limitations.
 |
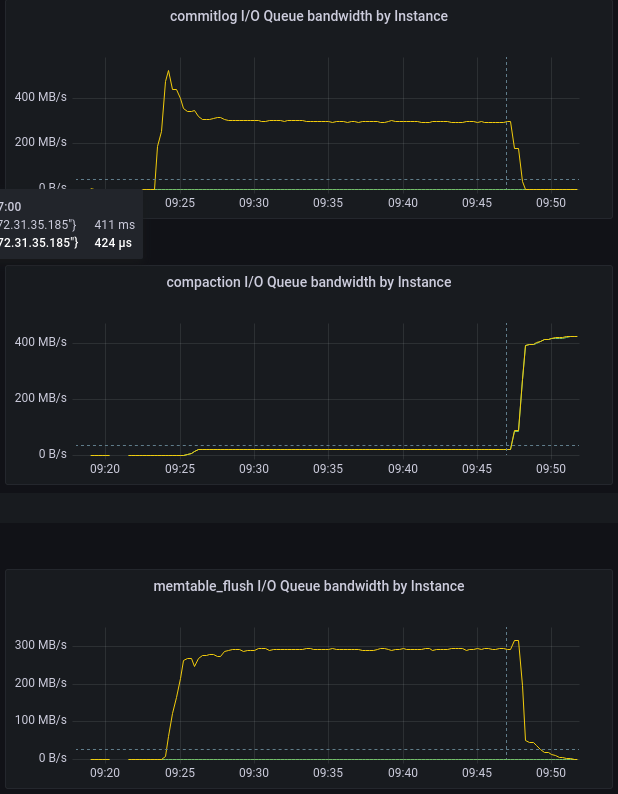 |
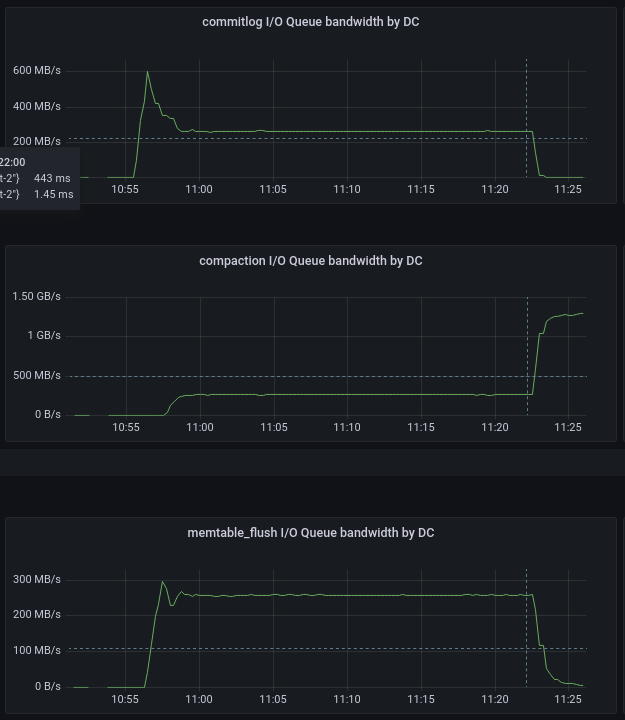
Population bandwidth: ScyllaDB 4.6 (total) vs 5.0 (split, green — R, yellow — W)
On the pair of plots above you can see bandwidth for three different flows — commitlog (write only), compaction (both reads and writes) and memtable flushing (write only). Note that ScyllaDB 5.0 can report read and write bandwidth independently.
ScyllaDB 4.6 maintains the total bandwidth to be 800 MB/s which is the peak of what the disk can do. ScyllaDB 5.0 doesn’t let the bandwidth exceed a somewhat lower value of 710 MB/s because the new formula requires that the balanced sum of bandwidth and IOPS, not their individual values, stays within the limit.
Similar effects can be seen during the reading phase of the test on the plots below. Since the reading part involves the low-size reading requests coming from the CQL requests processing, this time it’s good to see not only the bandwidth plots, but also the IOPS ones. Also note, that this time there are three different parts of the test — the incoming request rate was 10k, 5k and 7.5k, thus there are three distinct parts on the plots. And last but not least — the memtable flushing and commitlog classes are not present here, because this part of the test was read-only with the compaction job running in the background.
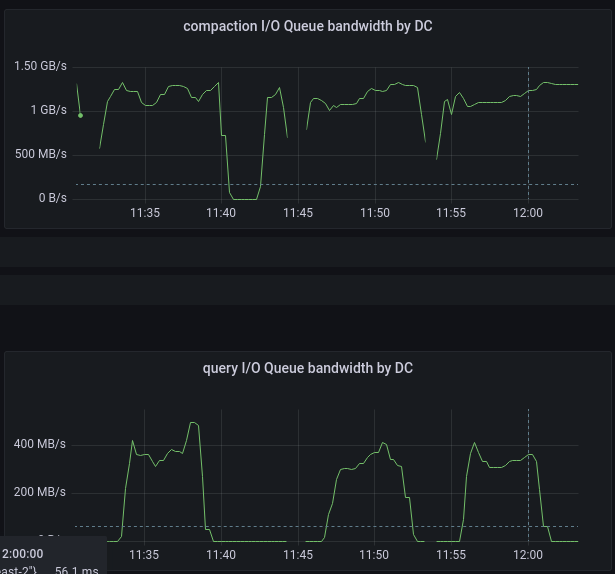 |
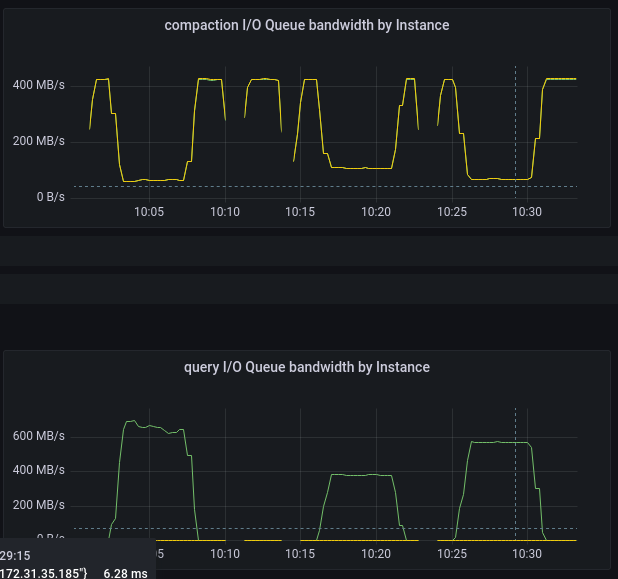 |
Query bandwidth: ScyllaDB 4.6 (total) vs 5.0 (split, green — R, yellow — W)
The first thing to note is that the 5.0 scheduler inhibits compaction class much heavier than in 4.6, letting the query class get more disk throughput — which is one of the goals we wanted to achieve. Second, it’s seen that like during the population stage, the net bandwidth on the 5.0 scheduler is lower than the one on 4.6 — again because the new scheduler takes into account the IOPS value together with the bandwidth, not separately.
By looking at the IOPS plots one may notice that 4.6 seems to provide more or less equal IOPS for different request rates in the query class, while 5.0’s allocated capacity is aligned with the incoming rate. That’s the correct observation, the answer to it — 4.6 didn’t manage to sustain even the request rate of 5k requests per second, while 5.0 felt well even at the rate of 7.5k and died at 10k. Now that is the clear indication that the new scheduler does provide the expected I/O latencies.
Latency Implications
Seastar keeps track of two latencies — in-queue and in-disk. The scheduler’s goal is to maintain the latter one. The in-queue can grow as high as it wants; it’s up to upper layers to handle it. For example, if the requests happen to wait too long in the queue, ScyllaDB activates a so-called “backpressure” mechanism which involves several techniques and may end up canceling some requests sitting in the queue.
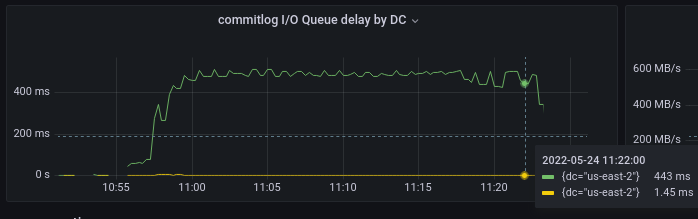
ScyllaDB 4.6 commitlog class delays (green — queue time, yellow — execution time)
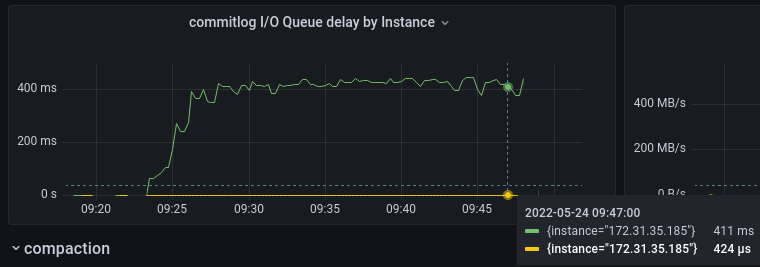
ScyllaDB 5.0 commitlog class delays (green — queue time, yellow — execution time)
The scale of the plot doesn’t make it obvious, but from the pop-up on the bottom-right it’s seen that the in-disk latency of the commitlog class dropped three times — from 1.5 milliseconds to about half a millisecond. This is the direct consequence of the overall decreased bandwidth as was seen above.
When it comes to querying workload, things get even better, because this time scheduler keeps bulky writes away from the disk when the system needs short and latency sensitive reads.
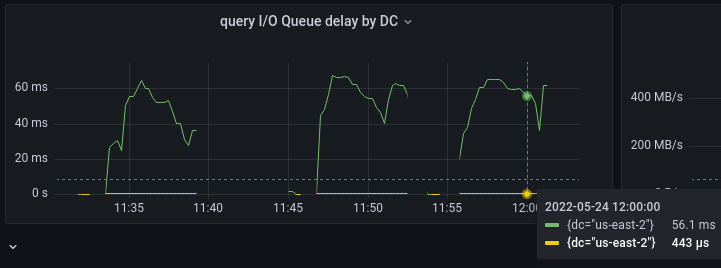
ScyllaDB 4.6 query class delays (green — queue time, yellow — execution time)
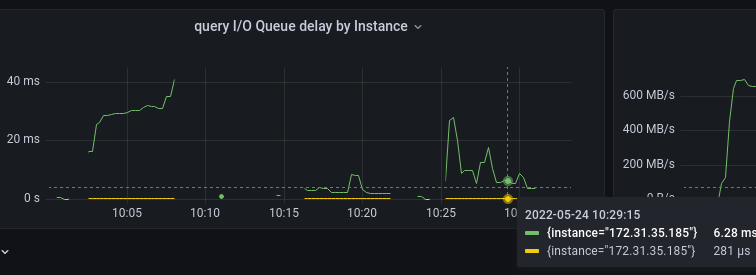
ScyllaDB 5.0 query class delays (green — queue time, yellow — execution time)
Yet again, the in-queue latencies are orders of magnitude larger than the in-disk ones, so the idea of what the latter are can be gotten from the pop-ups on the bottom-right. Query in-disk latencies dropped two times thanks to the suppressed compaction workload.
What’s Next
The renewed scheduler will come as a part of lots of other great improvements in 5.0. However, some new features should be added on top. For example — the metrics list will be extended to report the described accumulated costs each scheduling class had collected so far. Another important feature is in adjusting the rate limiting factor (the K thing) run-time to address disks aging out and any potential mis-evaluations we might have done. And finally, to adjust the scheduler to be usable on slow drives like persistent cloud disks or spinning HDDs we’ll need to tune the configuration of the latency goal the scheduler aims at.
Updated October 1, 2025