




ScyllaDB is recognized for a number of things. Our KVM roots. A database built on Seastar’s shard-per-core architecture that enables unprecedented performance with unparalleled hardware efficiency. Tackling the toughest database engineering challenges with the world’s top infrastructure engineers. And, of course, the adorable one-eyed monster.
Today, I’m excited to share how we’re taking that mission to new levels with ScyllaDB V: the latest evolution of our monstrously fast and scalable NoSQL database. It represents the fifth generation of our distributed database architecture.
ScyllaDB 5.0 is the first milestone for ScyllaDB V. It introduces a host of functional, performance, and stability improvements. First and foremost, we integrated Raft to provide consistent manageability and consistent operations. We are also using a new IO scheduler that allows us to scale the cluster and cope with any failure mode with a mere 3ms increase in our P99 latency. It is a real breakthrough after 2 years of development. Moreover, ScyllaDB V is introducing additional enhancements that transform ScyllaDB into an extremely solid and robust database, with impressive stability and manageability.
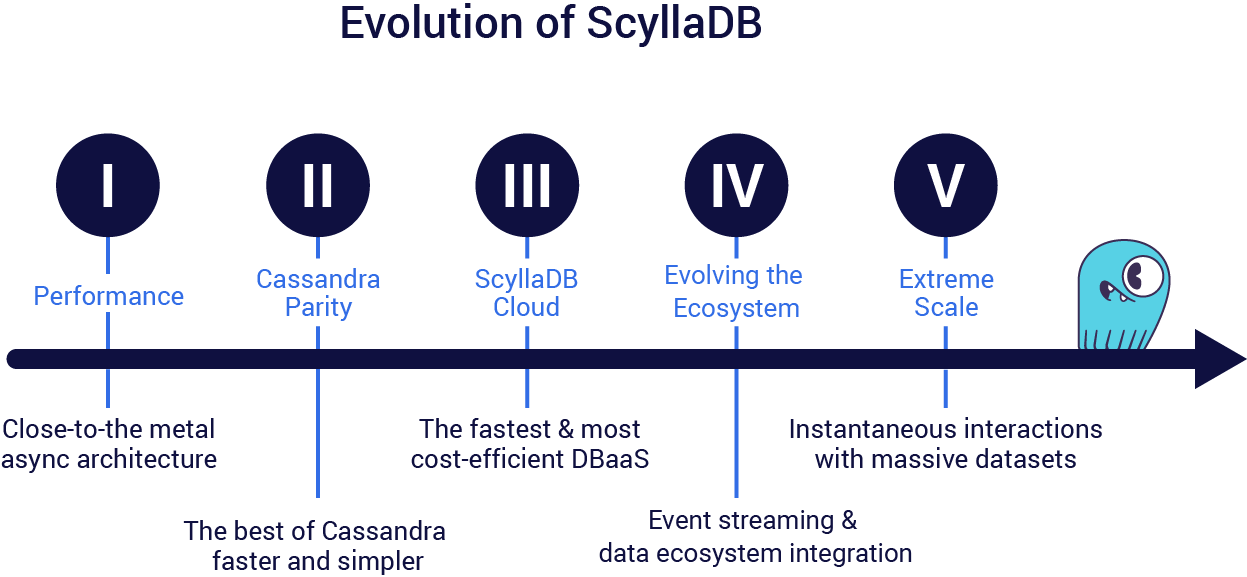
I: Performance
First generation ScyllaDB focused on raw, brute force performance. Our original goal was to utilize all of the cores of a modern CPU with a minimal performance penalty. Before writing the first line of code, our goal was to achieve 1 million operations per second per server. This goal was accomplished when we emerged out of stealth mode in late 2015.
Performance remains a focus and we continue to be excited about it. Today, ScyllaDB can run a petabyte-scale deployment with 20 i3en.metal AWS instances doing millions of transactions – all at single-digit millisecond P99 latency.
II: Cassandra Parity
Second generation ScyllaDB was about reaching full API compatibility with the popular Apache Cassandra database. Among many other issues, we solved the garbage collection and compaction challenges that plague Cassandra to this day. This certainly has not gone unnoticed or unappreciated; many of our users came to ScyllaDB with a single request: ‘get me out of Java/GC.’
III: Into the Cloud
Third generation ScyllaDB moved into the cloud, providing the industry’s fastest and most cost-efficient NoSQL database-as-a-service (DBaaS). Dev teams at industry-leading companies like Disney+ Hotstar and Instacart appreciate ScyllaDB Cloud’s speed and scale – without the hassle and toil of self-management. Given the simple startup and seamless scaling, it’s not surprising that usage of ScyllaDB Cloud has surged 198% year over year.
IV: Evolving the Ecosystem
With this accomplished, we turned to making ScyllaDB the best database to integrate into your overall data ecosystem. One of the key revolutions of the past few years has been the relentless drive toward event streaming. Integrating databases with event streaming was initially difficult with existing tech stacks. In response, we provided a shard-aware Kafka sink connector. Then, to effectively make ScyllaDB an efficient event streaming producer, we implemented Change Data Capture (CDC) with an elegant solution for a complex problem. It pairs perfectly with our Kafka Source connector based on Debezium. We also added event streaming to our Cassandra-compatible CQL interface and as Alternator Streams for our DynamoDB-compatible API. Additionally, we implemented a more efficient implementation of Lightweight Transactions (LWT), an entirely new compaction strategy, and other features.
V: Innovations for Extreme Scale
Now we turn the page on a new chapter. ScyllaDB V is focused on innovations for the extreme scale that is driving this next tech cycle.
The Raft consensus algorithm lies at the heart of the ScyllaDB V transition. ScyllaDB 5.0 utilizes Raft to provide transactional schema changes. No more schema conflict! Subsequent ScyllaDB 5.x releases will allow transactional topology changes, which will simplify operations and improve elasticity. Eventually, Raft will be used to provide immediate consistency instead of the good old eventual consistency.
In ScyllaDB V, the operator is king. The new IO scheduler smooths out the latency created by the enormous streaming load of terabytes traveling between the nodes. Repair, streaming, decommission, failures – all their impacts are now unnoticeable.
In addition, introducing repair-based operations makes node replacement operations restartable and faster. We committed an exciting new partition-rate-limit feature in the master branch, allowing you to control access to your database. Traditionally, there were cases where too much data could be entered into a database, (for example, malicious bots could overload partitions). With ScyllaDB V, your database is protected and can avoid global and local overloads.
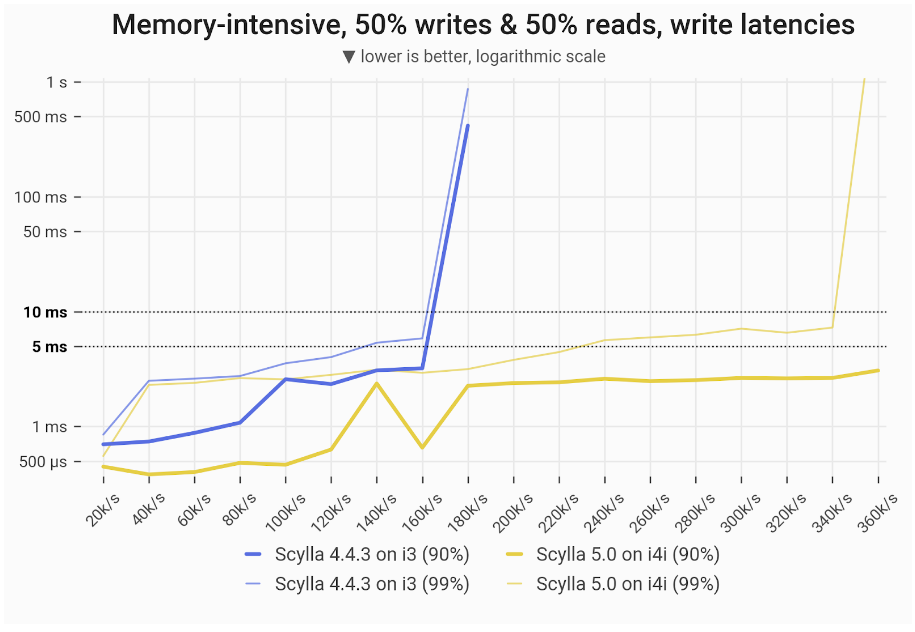
Given ScyllaDB’s obsession with high throughput and low latency, we can’t overlook performance. We’ll share all the latest benchmark results in the coming weeks. As a little teaser, here’s the performance comparison of two 3-node, 16 vCPU clusters: one running ScyllaDB 4.4 on AWS i3.4xl and the other ScyllaDB 5.0 on the new AWS i4.4xl. Notice the improvement in both throughput and latency.
Why ScyllaDB V?
So why did we decide to focus on these innovations for extreme scale? Just look at what’s driving this next tech cycle:
- Infrastructure has advanced substantially, offering tremendous power and performance to applications that can take advantage of it.
- Applications need to work at previously-unimaginable scale — fast — and available all the time. They need to work flawlessly across a dizzying array of environments and conditions. And the teams building them need the ability to move seamlessly from MVP to global scale – and to rapidly evolve business-critical applications in production.
- Data-intensive applications from food delivery, to fitness tracking apps, to communication platforms are now woven into the fabric of our lives. Data is involved in virtually everything that we do.
- NFTs, cryptocurrency, distributed ledger technology, and the metaverse are taking distributed applications to a new level
This not only means more data, but also new pressures on the database. Organizations are now performing up to 100x more queries than before, on data sets that are often 10x larger than before. Data is being enriched, cleaned, streamed, fed into AI/ML pipelines, replicated, and cached from multiple sources. The more data you have, the more you use that data…and that means more opportunity to gain advantages via data in this new world of ours.
What does this mean for your database latency? If you have 100x the queries, P99 becomes P36 (100 queries to fulfill an app response, takes the P99 to the power of 100). Things break at scale. And costs skyrocket.
That’s why it’s more important than ever to have a database that’s up to the task. And that’s the driving force behind ScyllaDB V. To help fast-growing, fast-moving teams deliver lightning-fast experiences at extreme scale, this generation of ScyllaDB focuses on innovations that:
- Extract every ounce of power from the latest and greatest infrastructure for better performance, fewer admin headaches, and lower costs
- Enable massive clusters to be doubled or tripled almost instantly when demand surges
- Make it feasible to manage thousands of clusters, use meganodes or tiny pods, and do further cluster consolidation and table consolidation within a cluster
- Remove the performance penalties from working with large partitions, reversed queries, and even achieving the stronger consistency required by many use cases
For more details on how we’re achieving these and other innovations for extreme scale, I invite you to watch Avi Kivity (co-founder and CTO) share his take in the following video:
Also, see the ScyllaDB V page for high-level overview of key features.
I hope that you share my excitement about the many opportunities that ScyllaDB V unlocks. I’m eager to see all the great things that our users accomplish with it. As always, please don’t hesitate to contact us on Slack or through your representatives if you have any questions or feedback!







