




Cloning a database cluster is probably the most common usage of backup data. This process can be very useful in case of a catastrophic event — say you were running in a single DC and it just burnt down overnight. (For the record, we are always encouraging you to follow our high availability and disaster recovery best practices to avoid such catastrophic failures. For distributed topologies we have you covered via built-in multi-datacenter replication and ScyllaDB’s fundamental high availability design.) When you have to restore your system from scratch, that process is going to require cloning your existing data from a backup onto your new database cluster. Beyond disaster recovery, cloning a cluster is very handy in case if you want to migrate a cluster to different hardware, or if you want to create a copy of your production system for analytical or testing purposes. This blog post describes how to clone a database cluster with ScyllaDB Manager 2.4.
The latest release of ScyllaDB Manager 2.4 adds a new ScyllaDB Manager Agent download-files command. It replaces vendor specific tools, like AWS CLI or gcloud CLI for accessing and downloading remote files. With many features specific to ScyllaDB Manager, it is a “Swiss army knife” data restoration tool.
The ScyllaDB Manager Agent download-files command allows you to:
- List clusters and nodes in a backup location, example:
scylla-manager-agent download-files -L <backup-location> --list-nodes
- List the node’s snapshots with filtering by keyspace / table glob patterns, example:
scylla-manager-agent download-files -L <backup-location> --list-snapshots -K 'my_ks*'
- Download backup files to ScyllaDB upload directory, example:
scylla-manager-agent download-files -L <backup-location> -T <snapshot-tag> -d /var/lib/scylla/data/
In addition to that it can:
- Download to table upload directories or keyspace/table directory structure suitable for sstable loader (flag
--mode) - Remove existing sstables prior to download (flag
--clear-tables) - Limit download bandwidth limit (flag
--rate-limit) - Validate disk space and data dir owner prior to download
- Printout execution plan (flag
--dry-run) - Printout manifest JSON (flag
--dump-manifest)
Restore Automation
Cloning a cluster from a ScyllaDB Manager backup is automated using the Ansible playbook available in the ScyllaDB Manager repository. The download-files command works with any backups created with ScyllaDB Manager. The restore playbook works with backups created with ScyllaDB Manager 2.3 or newer. It requires token information in the backup file.
With your backups in a backup location, to clone a cluster you will need to:
- Create a new cluster with the same number of nodes as the cluster you want to clone. If you do not know the exact number of nodes you can learn it in the process.
- Install ScyllaDB Manager Agent on all the nodes (ScyllaDB Manager server is not mandatory)
- Grant access to the backup location to all the nodes.
- Checkout the playbook locally.
The playbook requires the following parameters:
backup_location– the location parameter used in ScyllaDB Manager when scheduling a backup of a cluster.snapshot_tag– the ScyllaDB Manager snapshot tag you want to restorehost_id– mapping from the clone cluster node IP to the source cluster host ID
The parameter values shall be put into a vars.yaml file, below an example file for a six node cluster.
Example
I created a 3 node cluster and filled each node with approx 350GiB of data (RF=2). Then I ran backup with ScyllaDB Manager and deleted the cluster. Later I figured out that I want to get the cluster back. I created a new cluster of 3 nodes, based on i3.xlarge machines.
Step 1: Getting the Playbook
First thing to do is to clone the ScyllaDB Manager repository from GitHub “git clone git@github.com:scylladb/scylla-manager.git“ and changing directory “cd scylla-manager/ansible/restore“. All restore parameters shall be put to vars.yaml file. We can copy vars.yaml.example as vars.yaml to get a template.
Step 2: Setting the Playbook Parameters
For each node in the freshly created cluster we assign the ID of the node it would clone. We do that by specifying the `host_id` mapping in the vars.yaml file. If the source cluster is running you can use “Host ID” values from “sctool status” or “nodetool status” command output. Below is a sample “sctool status” output.
If the cluster is deleted we can SSH one of the new nodes and list all backed up nodes in the backup location.
Based on that information we can rewrite the host_id
When we have node IDs we can list the snapshot tags for that node.
We now can set the snapshot_tag parameter as snapshot_tag: sm_20210624122942UTC.
If you have the source cluster running under ScyllaDB Manager it’s easier to run “sctool backup list” command to get the listing of available snapshots.
Lastly we specify the backup location as in ScyllaDB Manager. Below is a full listing of vars.yaml:
The IPs nodes in the new cluster must be put to Ansible inventory and saved as hosts:
Step 3: Check the Restore Plan
Before jumping into restoration right away, it may be useful to see the execution plan for a node first
With --dry-run you may see how other flags like --mode or --clear-tables would affect the restoration process.
Step 4: Press Play
It may be handy to configure default user and private key in ansible.cfg.
When done, “press play” (run the ansible-playbook) and get a coffee:
The restoration took about 15 minutes on a 10Gb network. The download saturated at approximately 416MB/s.
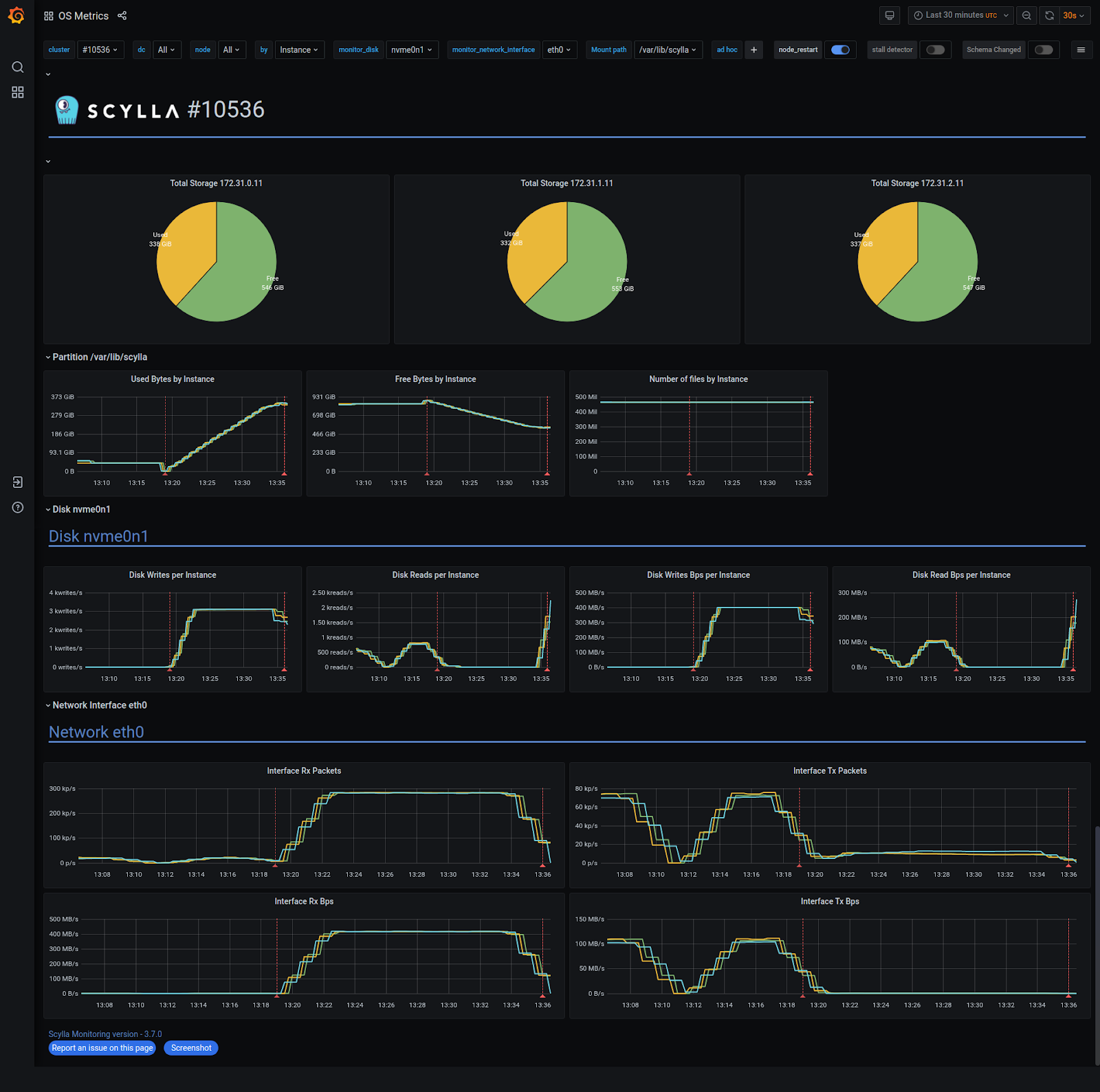
CQL Shell Works Just Fine.
After completing the restore, it’s recommended to run a repair with ScyllaDB Manager.
Next Steps
If you want to try this out yourself, you can get a hold of ScyllaDB Manager either as a ScyllaDB Open Source user (for up to five nodes), or as a ScyllaDB Enterprise customer (for any sized cluster). You can get started by heading to our Download Center, and then checking out the Ansible Playbook in our ScyllaDB Manager Github repository.
If you have any questions, we encourage you to join our community on Slack.



