




Disasters can strike any business on any day. This particular disaster, a fire at the OVHcloud Strasbourg datacenter, struck recently and the investigation and recovery are still ongoing. This is an initial report of one company’s resiliency in the face of that disaster.
Overview of the Incident
Less than an hour after midnight on Wednesday, March 10, 2021, in the city of Strasbourg, at 0:47 CET, a fire began in a room at the SBG2 datacenter of OVHcloud, the popular French cloud provider. Within hours the fire had been contained, but not before wreaking havoc. The fire nearly entirely destroyed SBG2, and gutted four of twelve rooms in the adjacent SBG1 datacenter. Additionally, combatting the fire required proactively switching off the other two datacenters, SBG3 and SBG4.
Netcraft estimates this disaster accounted for knocking out 3.6 million websites spread across 464,000 domains. Of those,184,000 websites across nearly 60,000 domains were in the French country code Top Level Domain (ccTLD) .FR — about 1 in 50 servers for the entire .FR domain. As Netcraft stated, “Websites that went offline during the fire included online banks, webmail services, news sites, online shops selling PPE to protect against coronavirus, and several countries’ government websites.”

OVHcloud’s Strasbourg SBG2 Datacenter engulfed in flames. (Image: SDIS du Bas Rhin )
Kiwi.com Keeps Running
However, one company that had their servers deployed in OVHcloud fared better than others: Kiwi.com, the popular online travel site. ScyllaDB, the NoSQL database Kiwi.com had standardized upon, was designed from the ground up to be highly available and resilient, even in the face of disaster.
Around 01:12 CET, about a half hour after the fire initially broke out, Kiwi.com’s monitoring dashboards produced alerts as nodes went down and left the cluster. There were momentary traffic spikes as these nodes became unresponsive, but soon the two other OVHcloud European datacenters used by Kiwi.com took over requests bound for Strasbourg.
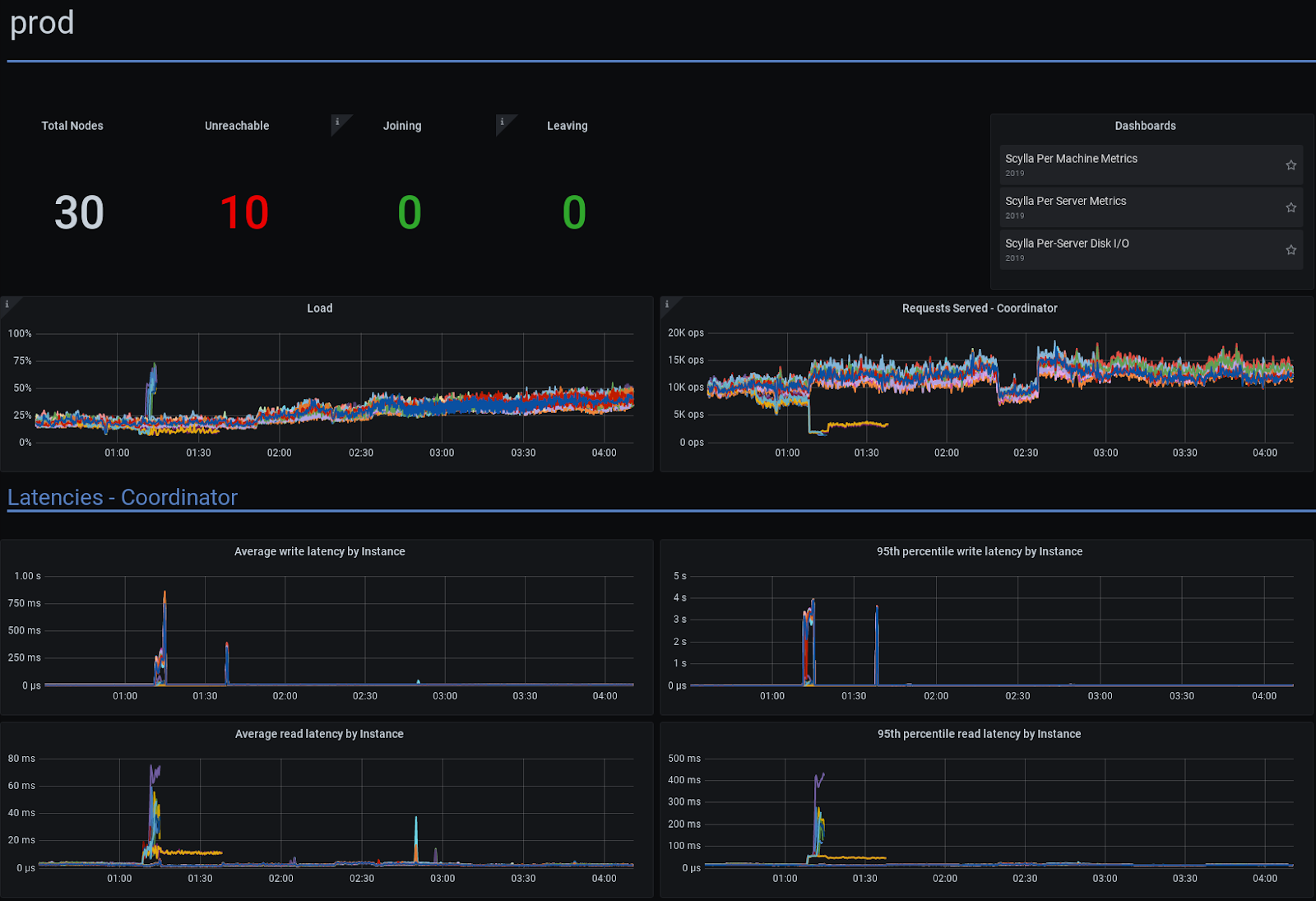
Out of a thirty node distributed NoSQL cluster, ten nodes became suddenly unavailable. Other than a brief blip around 1:15, Kiwi.com’s ScyllaDB cluster continued working seamlessly. Load on the remaining online nodes rose from ~25% before the outage to ~30-50% three hours later. (Source: Kiwi.com)
Kiwi.com had just lost 10 server nodes out of 30 nodes total, but the remaining ScyllaDB database cluster was capable of rebalancing itself and handling the load. Plus, because ScyllaDB is datacenter topology aware and kept multiple copies of data geographically distributed, their database kept running with zero data loss.
According to Kiwi.com’s Milos Vyletel, “As we designed ScyllaDB to be running on three independent locations — every location at least 200 kilometers from another — Kiwi.com survived without any major impact of services.”
The multi-local OVHcloud infrastructure enabled Kiwi.com to build out a robust and scalable triple replicated ScyllaDB database in three datacenters all in separate locations. The secure OVH vRack synchronised the connection of the three sites via a reliable private network, allowing the cluster optimal replication and scalability across multiple locations.
Indeed, Kiwi.com had done their disaster planning years before, even joking about their resiliency by having their initial ScyllaDB cluster launch party in a Cold War era nuclear fallout shelter. Now their planning, and their technology choice, had paid back in full.

As dawn broke, the fire was out, but the extensive damage to the OVHcloud Strasbourg datacenter was clear. (Image: AP Photo/Jean-Francois Badias)
With the dawning of a new day, load on Kiwi.com’s database picked up, which taxed the remaining servers, yet ScyllaDB kept performing. As Milos informed the ScyllaDB support team, “ScyllaDB seems fine. A bit red but everything works as designed.”
The Road to Disaster Recovery
In total, ten production nodes, plus two other development servers, located in SBG2 were lost to Kiwi.com and are unrecoverable. The next steps are to await for the other OVHcloud SBG buildings to be brought back up again, at which point Kiwi.com will refresh their hardware with new servers. Kiwi.com is also considering using this opportunity to update the servers in their other datacenters.
Lessons Learned
Milos provided this advice from Kiwi.com’s perspective: “One thing we have learned is to test full datacenter outages on a regular basis. We always wanted to test it on one product, as one of the devs was pushing us to do, but never really had taken the time.”
“Fortunately, we sized our ScyllaDB cluster in a way that two DCs were able to handle the load just fine. We applied the same principles to other (non-ScyllaDB) clusters as well, but over time as new functionality was added we have not been adding new capacity for various reasons — COVID impact being the major one over this last year or so. We are kind of pushing limits on those clusters — we had to do some reshuffling of servers to accommodate for the lost compute power.
“The bottom line is it is more expensive to have data replicated on multiple geographically distributed locations, providing enough capacity to survive a full DC outage, but when these kinds of situations happen it is priceless to be able to get over it with basically no downtime whatsoever.”



