




With continued and growing interest in Apache Spark, we had two speakers present at ScyllaDB Summit 2018 on the topic. This is the first of a two-part article, covering the talk by ScyllaDB’s Eyal Gutkind. The second part covers the talk by Google’s Holden Karau.
With business demanding more actionable insight and ROI out of their big data, it is no surprise that analytics are a common workload on ScyllaDB. Nor is it a surprise that Spark is a perennial favorite on the ScyllaDB Summit agenda, and our annual gathering last year proved to be no exception. The focus was on the practical side of using ScyllaDB with Spark, understanding the interplay between cluster configuration between the two, and making a Spark installation more resilient to failures late in a long-running analytics job.
Apache Spark
Apache Spark bills itself as a unified analytics engine for large-scale data processing. It achieves its high performance using a directed acyclic graph (DAG) scheduler, along with a query optimizer and an execution engine.
In many ways Spark can be seen as a successor to Hadoop’s MapReduce. Invented by Google, MapReduce was the first to leverage large server clusters to index the web. Following Spark’s release, it was quickly adopted by enterprises. Today, Spark’s community encompasses a broad community ranging from individual developers to tech giants like IBM. Use cases expanded to support traditional SQL batch jobs and ETL workloads across large data sets, as well as streaming machine data.
While Spark has achieved broad adoption, users often wrestle with a few common issues. The first issue is how Spark should be deployed in a heterogeneous big data environment, where many sources of data, including unstructured NoSQL data, feed analytics pipelines. The second issue is how to make a very long-running analytics pipeline more resilient to failures.
Best Practices for Running Spark with ScyllaDB
First on the agenda was Eyal Gutkind, ScyllaDB’s head of Solutions Architecture. In this role, Eyal helps ScyllaDB customers successfully deploy and integrate ScyllaDB in their heterogeneous data architectures — everything from helping them with sizing their cluster to hooking up ScyllaDB with their Spark or Kafka infrastructure. Eyal pointed out that side-by-side Spark and ScyllaDB deployments are a common theme in modern IT. Executing analytics workloads on transactional data provide insights to the business team. ETL workloads using Spark and ScyllaDB are also common. In his presentation, Eyal covered different workloads that his team has seen in practice, and how they helped optimize both Spark and ScyllaDB deployments to support a smooth and efficient workflow. Some of the best practices that Eyal covered included properly sizing the Spark and ScyllaDB nodes, tuning partitions sizes, setting connectors concurrency and Spark retry policies. Finally, Eyal addressed ways to use Spark and ScyllaDB in migrations from different data models.
Mapping ScyllaDB’s Token Architecture and Spark RDDs
Eyal homed in on the architectural differences between ScyllaDB and Spark. ScyllaDB shards differently than Spark. But the main difference is the way Spark consumes data out of ScyllaDB.
Spark is a distributed system with a driver program—the main function. Each executor has different cache and memory settings. Memory is ordered in a resilient distributed dataset (RDD), which is stored on each node.
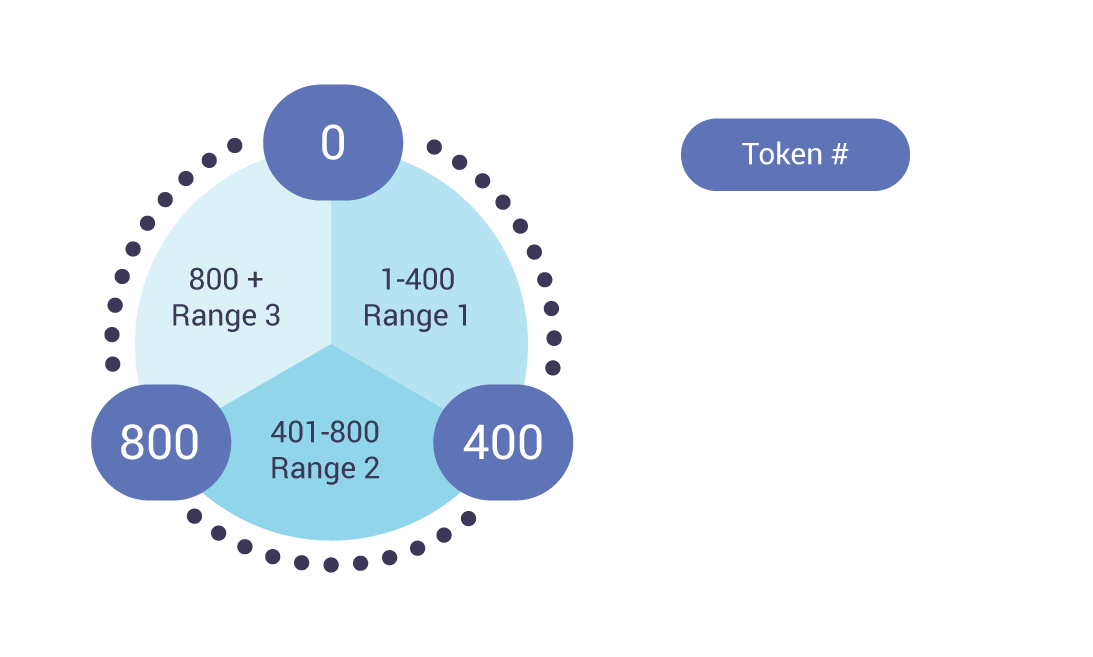
A basic example of how ScyllaDB makes evenly-distributed partitions via token ranges
ScyllaDB takes the partitioned data and shards it by cores, distributing data across clusters using Murmur3 to make sure that every node will have an even number of partitions to prevent hotspots. This guarantees the load on each node will be even. (Read more about the murmur3 partitioner in our ScyllaDB Ring Architecture documentation.)
The driver hashes the partition key and sends the hash to a node. From there, the cluster replicates the data to other nodes based on your replication factor (RF).
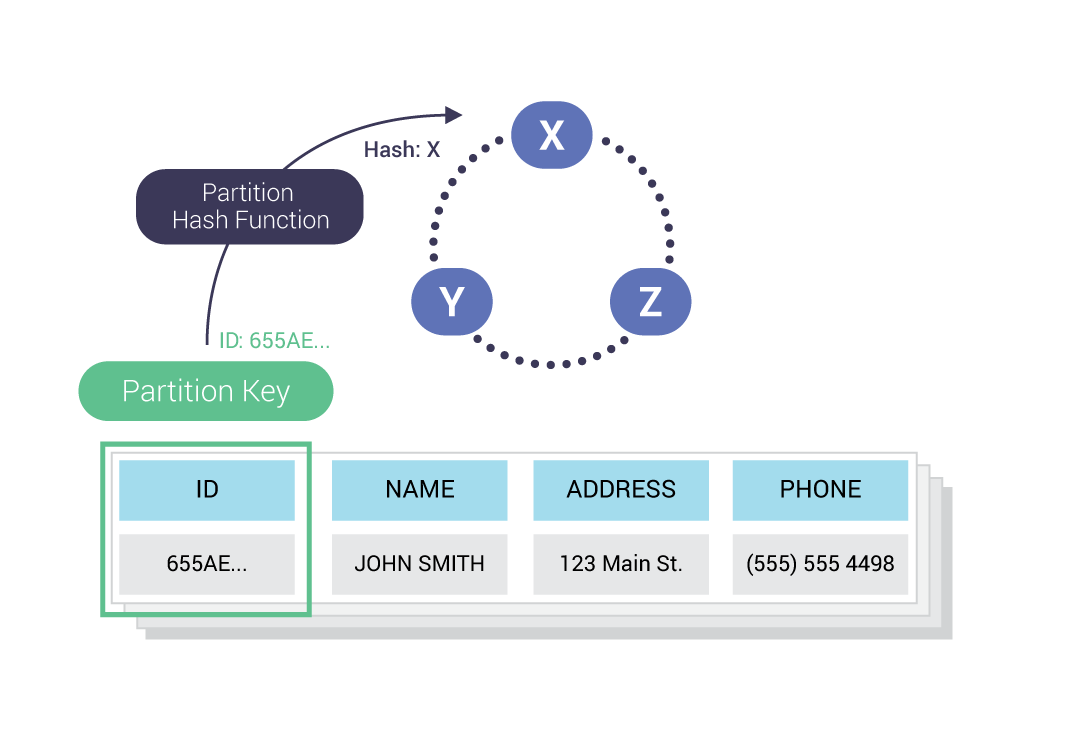
An example of how the partition hash function is applied to data to insert it into a token range
In contrast, Spark is a lazy system. It consumes data, but doesn’t do anything with it; the actual execution happens only when Spark writes data. Spark reads data taken from ScyllaDB into RDDs, which are distributed across different nodes.
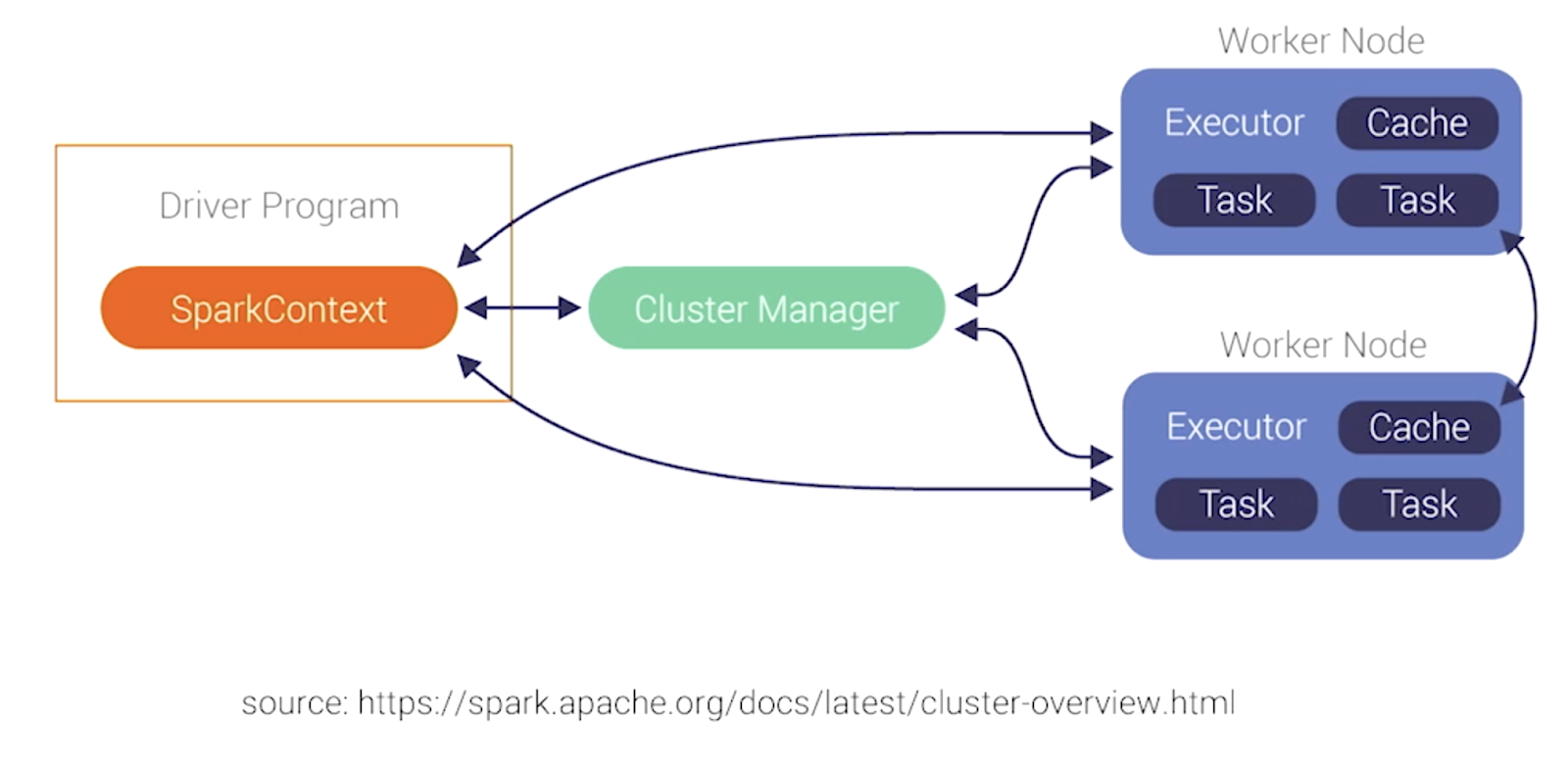
How Apache Spark distributes data across different nodes using SparkContext
When running the two systems side-by-side, multiple partitions from ScyllaDB will be written into multiple RDDs on different Spark nodes. For example:
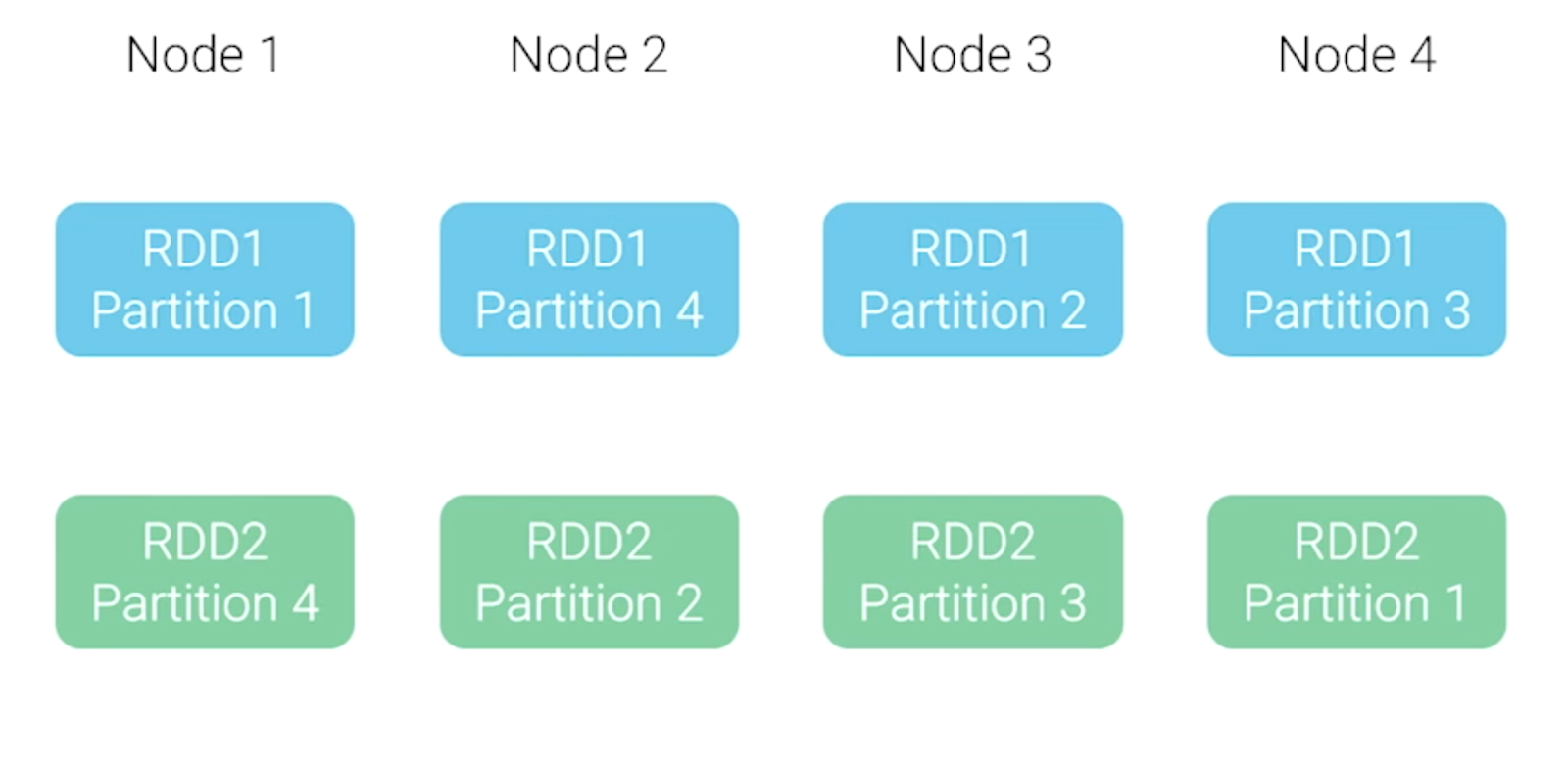
How Apache Spark splits multiple RDDs across nodes into partitions
Spark was written to work with the Hadoop file system (HDFS), where the execution unit sits on top of the data. The idea is to minimize traffic on the network and make it efficient. ScyllaDB works differently; partitions sit on different nodes in the cluster. So there is a mismatch in data locality between ScyllaDB and Spark nodes.
Tables are stored on different nodes, and gathering data across different nodes is an expensive operation. The Cassandra-Spark collector creates a SparkContext, which is an abstraction of the Spark notion of the data inside ScyllaDB for the Spark executors. It writes information into ScyllaDB in batches; there are nuances to how this happens. Currently, the Spark connector is packaged with the Java driver. “We are trying to bring in more efficient drivers so that we can connect better between Java Application and ScyllaDB—the Spark connector benefits from this.”
When Spark Writes to ScyllaDB: Strategies for Batching
The Spark connector batches information inside Spark. As Eyal outlined, when you deploy Spark on ScyllaDB you need to look at the following settings:

For example, if you have to write 1,000 rows, it won’t start writing to ScyllaDB until 1,001 rows have been collected (then the first 1,000 will be sent). There are ways to change the buffer size, though. (Default is 1,000.) Another trigger, the amount of data in buffer (measured in bytes), ensures you don’t overcommit ScyllaDB nodes to throughput that cannot be sustained. You can also define the number of concurrent writes. The default is 5.
These settings determine how groups will be batched. Batches are inefficient when batching multiple partition keys in a single batch, so you need to make sure that those batches return to a single partition key. These settings allow multiple strategies. The default is by partition key, but you can’t guarantee the same P key for each batch.
Another option is batching by replica set, and the third option is NONE; to disregard the grouping option. Once a batch is ready it goes to all nodes or partitions that are participating.
The maximum batch size is 1K. If you’re going to change the size of the batch and there are some key use cases where you want to do this, be aware that it actually might collide with your ScyllaDB settings. You’ll see warnings in your log, errors when you exceed five kilobytes, or it’s going to error out and that can be painful!
Eyal pointed out that is important to make sure that you are aligned between the size of the batches you defined in your connector and the ones that you actually use inside your system.
When ScyllaDB or the connector writes into the ScyllaDB nodes, it’s going to use a local quorum. It will ask at least if you have a replication factor of three; two nodes to acknowledge the write. If you have a very high write throughput you might want to change it to a local one to prevent any type of additional latency in the system.
The Spark connector will check the table size. For example, the table has a gigabyte of data. The driver then checks how many executors of Spark have been assigned to run the job, for example, 10.
That one gigabyte will be divided by 10, for 100 megabytes that will have to be fetched for each one of those executors. The connector says “wait! that might be too much!” For example, in a Cassandra cluster I want to throttle it, or make sure that I don’t over commit the cluster.
The default setting for input.split.size_in_mb is going to take that RDD or that data and chunk it into 64 megabyte reads from the cluster. Since driver was written for Cassandra, the awareness is by node, not by shard. To do this operation by shard, from the ScyllaDB perspective, now a single shard, a single connection, will try to read 64 megabytes, making it inefficient. Our recommendation is to use a smaller chunk, which will create more reads from the cluster, but each of those reads will hit a different shard in the cluster. This provides better concurrency on the read side. (For example, in an 8-CPU machine, where each CPU represents a shard, you could divide the default by the number of shards, setting input.split.size_in_mb to 64mb / 8 = 8mb.)
If you have a huge partition and you want to dice it by different rows, you can configure it to be 50, 60, or 100 rows. The current default is 1,000 rows, which is efficient. Eyal recommended that ScyllaDB users experiment with various input sizes to find the setting that works best for each use case.
To Collocate, or Not to Collocate?
Eyal discussed a common topic from his customer engagements; whether or not to collocate ScyllaDB and Spark. He pointed out that other systems recommend that you put your Spark cluster together with your data cluster, which provides some efficiencies in that you manage fewer nodes overall. This arrangement is more efficient from spinning up and down system since you don’t have to multiply your control plane.
There’s a cost to that, however. Every Spark node has executors. You need to define how many cores in each one of your servers will be an executor. For example, say you have a 16 core server — 8 cores for ScyllaDB and 8 cores for the Spark executors, dividing the node in half. This may be efficient in cases where you have a constant analytics workload running against that specific cluster. It might be worthwhile to increase or scale-up the node to collocate Spark together with ScyllaDB.
Eyal said that in his experience, “those workloads that are constantly running are fairly small, so the benefit of collocation might not be that beneficial. We do recommend separating the Spark cluster from the ScyllaDB cluster. You’ll have to tune less. You have a more efficient ScyllaDB that will provide better performance. And you might want to tear down or scale up/scale down your Spark cluster, so the dynamic of actually using the Spark is going to be more efficient.”
Since Spark is implemented in Java, you have to manage memory. If you’re going to set up some kind of a off-heap memory, you have to consider ScyllaDB usage of that specific memory to prevent collisions.
Fine Tuning
Spark exposes a setting that defines the number of parallel tasks you want the executor to run. The default setting of 1 can be increased to the number of cores you have in the ScyllaDB node, creating more parallel connections. You can also reduce the split size from 64 mb to 1 mb.
There is a setting inside the Cassandra connector that determines the maximum connections to deploy. The default is calculated by the number of executors. Eyal recommended that ScyllaDB users increase this setting to the number of cores or more that you have in the ScyllaDB side, to open more connections. The number of connections going to open by the way if you don’t have any workload is one. So the Java connector will open one connection between your Spark executors and your ScyllaDB nodes.
The different concurrent writes — the actual writes batch in-flight you can have — have a default of 5. It might make sense to increase that number, if you have a very high write load. The default for Concurrent.reads for each one of those connections is 512. Again, it makes sense if you need a very high read workload to increase that number.
To Conclude
ScyllaDB does enable you to run analytics workloads. And ScyllaDB actually plans to improve the processes more (see ScyllaDB’s Workload Prioritization feature). To support analytics user that can benefit from a different path of data and scanning those tables in a more efficient way.
Eyal recommended from his perspective that “if you have some questions about the most efficient way to deploy your Spark cluster with ScyllaDB, talk to us. We have found that there are several unique use cases, and you can achieve better performance by minor tuning in the connector, or by replacing the Java driver underneath it. Resource management is the key for a performant cluster. Time after time, we see that if your resource management is correct, and you size it correctly from the Spark side and the ScyllaDB side, you’ll be happy with the results.”
Part Two of this article covers Google’s Holden Karau and her ScyllaDB Summit 2018 presentation on Building Recoverable (and Optionally Asychronous) Pipelines in Spark.
Register Now for ScyllaDB Summit 2019!
If you enjoy technical insights from industry leaders, and want to learn more about how to get the most out of ScyllaDB and your big data infrastructure, sign up for ScyllaDB Summit 2019, coming up this November 5-6, 2019 in San Francisco, California.

