I recently had the pleasure of interviewing Hang Chan of Dstillery. Hang wears many hats at Dstillery, including responsibilities for IT infrastructure, systems, network and site reliability engineering. Hang drew from his breadth of experience to answer a few questions for me regarding Dstillery’s use of ScyllaDB.
If you could, please briefly describe your use of ScyllaDB.
Dstillery is the marketing and advertising industry’s leading custom audience solutions provider. Top agencies and brands rely on Dstillery’s high quality audiences for branding and direct response initiatives to thrive. To do this with accuracy and scale, Dstillery uses massive and diverse device-level data on a daily basis. We use ScyllaDB to look up various attributes for devices and to map devices between our systems and external partners.
What hard technical problems is Dstillery solving through use of ScyllaDB?
We need to be able to read and write at scale to the tune of hundreds of billions of requests a day with a timeout of 25 milliseconds.
What specific issues led you to migrate from Cassandra to ScyllaDB?
We were using Cassandra previously to provide us these capabilities. ScyllaDB is a drop-in replacement for Cassandra.
We were reaching a barrier where no matter how many nodes we added to the Cassandra cluster, we could not lower the failure rate. Even during periods of very low traffic, we would still see 0.1% failure rate using Cassandra, which amounts to thousands of failures. ScyllaDB brings it down to nearly 0.0%, or hundreds of failures. In one extreme case, we were able to reduce failure rate from 14% to 0.8% by replacing Cassandra with ScyllaDB.
Also, any details you can share about your Cassandra clusters?
We still have around 200 Cassandra nodes that we didn’t migrate because either they have a lot of data in them, or they don’t have the performance requirements of the clusters we migrated. These are mostly write-heavy workloads that don’t impact us as much.
One Cassandra cluster is on 3.11.3, and the other clusters are on 2.1.13.
On one cluster, we were able to reduce our server count by about 40% by switching to ScyllaDB.
What did you guys use Cassandra for and is ScyllaDB being used for the same thing? For example, a real-time bidding system?
We use ScyllaDB and Cassandra the same way – to be the backend datastore to model our audiences, create insights, and power our RTB platform.
What do you like most about ScyllaDB? You’ve mentioned low latencies and self-optimizing, is there anything else?
With Cassandra, we needed to tune around 40 different settings for garbage collection, JVM, memtables, compaction, and cache sizes. These settings would also need to be constantly adjusted over time. Since ScyllaDB tunes itself according to the workload, we just set the host IP, cluster name, seeds, and let it go knowing that the performance will normalize itself over time without any manual intervention.
The support on the slack channel and Google group is top notch. A little while back, we were having an issue where compaction was utilizing too many resources and causing failures. Glauber suggested we try a new setting which would throttle the compaction process. Updating the setting reduced our failures. I really appreciate that engineers like Glauber are there when you have issues and always ready to help.
Some other questions we have is how many CPU cores does each node have?
Our nodes are bare metal – they have 40 CPU cores.
Do you have ScyllaDB monitoring installed?
Yes, we collect ScyllaDB metrics via Prometheus, implemented using ScyllaDB Monitoring Stack.
Have you checked out ScyllaDB Open Source 3.0?
We’re really excited about the SSTable format change. Reducing storage usage would be huge as that’s one of the biggest reasons we add more nodes.
How do you backup and restore? What is your repair process like?
We take snapshots for backups and restores, but usually do it as and when needed, such as before an upgrade. We don’t do repairs as it’s a rather intensive operation – at least in Cassandra it was. Haven’t really used repairs in ScyllaDB. Latency and throughput is the most important for our use case and some tradeoffs needed to be made to achieve an acceptable level of performance for both metrics.
How many nodes are you running? And how are they organized into clusters?
We have 8 clusters of around 130 nodes in 2 DCs. This was around 250 nodes before a hardware refresh.Our applications handle the replication.
I read about Dstillery’s method for determining geodata authenticity, detecting inaccurate or falsified GPS coordinates for mobile users, and I was wondering: how is your use of ScyllaDB related to that capability?
ScyllaDB provides the device location history that we apply our algorithms against to detect inaccurate location data. We also use ScyllaDB for device web and app history, which is used to further validate location data quality.
No database operates in a vacuum. What other systems and infrastructure does ScyllaDB integrate with at Dstillery?
We generally use ScyllaDB in cases where we need to keep a lot of data and make simple lookups very quickly. The most common queries is usually a select * from table where key =. For cases where more logic is required, we would use a relational db like MySQL or PostgreSQL.
Mercuryd is middleware we created in-house which allows our apps to route to different datasources.
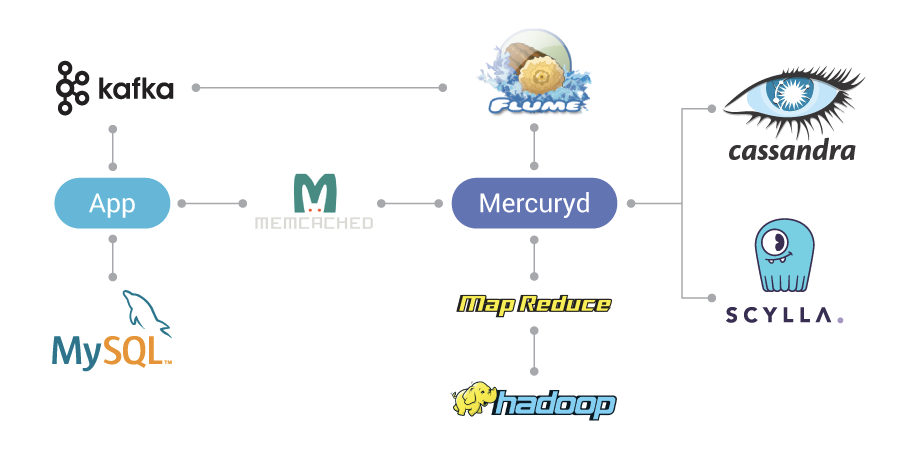
Dstillery’s Big Data adtech architecture, incorporating both SQL (MySQL) and NoSQL (memcached, Cassandra, and ScyllaDB) databases, Hadoop/MapReduce for analytics, plus both Apache Kafka and Apache Flume for streaming data. Mercuryd is Dstillery’s own in-house middleware solution.
My thanks to Hang for his time, insights and leadership. And from all of us here at ScyllaDB, our thanks and best wishes to everyone at Dstillery for choosing ScyllaDB.
Do you have a Big Data story of your own to share? If so, please contact us and let us know about your use case.