




We recently concluded testing and benchmarking ScyllaDB with KairosDB. The settings and results of this work can be found in the blog post, KairosDB and ScyllaDB: A Time-Series Solution for Performance and Scalability, and in our documentation.
In this post, we will share the questions and poll results from our recent live webinar with Brian Hawkins, the creator of KairosDB.
Q: Can I still use ScyllaDB and KairosDB in a single node installation? Meaning one ScyllaDB node and one KairosDB node?
A: Yes, it is possible to have a single node of ScyllaDB and a single node of KairosDB for the development stage, where high availability and resiliency of the stored data is not a requirement. However, we highly recommended using at least three ScyllaDB nodes and two KairosDB nodes in production and test environments to fully test for high availability and resiliency.
Q: What are the prerequisites for KairosDB?
A: The prerequisites for installing and using KairosDB are described on the KairosDB site. KairosDB requires Java 1.8 or higher and the JAVA_HOME definition on a Linux-based server (e.g. Ubuntu/Centos). We recommend using 4 CPUs, 8GB RAM, and at least 200GB of storage for your KairosDB node.
Q: Are there any minimal requirements for ScyllaDB (CPU / Disk size / Ram)?
A: ScyllaDB can be installed on various environment settings. Deployments can be used for development, staging, or production. We recommend at least 4 CPUS, 8GB or RAM and 1TB of SSD storage in each ScyllaDB node. A complete guide for ScyllaDB deployments can be found here.
Q: What is on the roadmap for KairosDB local queueing — e.g. durable writes into local file or memory that survives KairosDB node failures?
A: With KairosDB v1.2, there is an option to define a local queue, in which the KairosDB client is acknowledged on the write. The data is persisted on the KairosDB node, and in case of a KairosDB node restart, the data can be “replayed” into the persistent storage solution (e.g. ScyllaDB or Cassandra) attached to the KairosDB node.
Q: Why did you use three KairosDB Instances in your testing — is it for high availability or scalability?
A: Both. Users can configure their clients to send the data to multiple KairosDB instances and later on consolidate the multiple entries with roll-ups such as average, gaining high availability on the KairosDB front. With multiple KarioDB nodes, we achieved linear throughput growth from KairosDB into ScyllaDB.
Q: How long did you run the tests?
A: We executed each test for 1 hour.
Q: What configuration tuning do I need to do in ScyllaDB for huge writes?
A: ScyllaDB today has better support for wide row inserts and retrievals. There is no need to set any specific configurations to support those writes. KairosDB creates a 3-week long partition for each metric. You can read more about wide partition support in this blog post.
Q: We have a use case where upstream systems also queue so we’d like to turn off KairosDB write queuing (e.g. not mem or file based) — can this work?
A: Currently, KairosDB will queue the inserted data. However, the KairosDB team is working to enable a direct pass to the backend storage. Users should be aware of the latency performance of their backend storage to minimize any data loss. Look for further news on the KairosDB mailing list.
Q: Does ScyllaDB have special support for time-series data?
A: ScyllaDB does not have special support for time series data. However, the wide row support within the ScyllaDB architecture helps solutions such as KairosDB store data efficiently, while supporting fast and coherent reads from the persistent storage.
Q: How is the combined solution easier/better than simply running ElasticSearch?
A: While ElasticSearch has great indexing capabilities, the combined ScyllaDB and KairosDB solution is much easier to administer and maintain. Most notable capability in the combined solution is the ability to set Time To Live (TTL) to inserted data. If users are looking to retire data that is no longer needed, doing so with ElasticSearch can be cumbersome. With KairosDB and ScyllaDB, it is a simple set of the TTL data at the time of insert. Also, ScyllaDB outperforms ElasticSearch in throughput and latency characteristics.
Q: What latencies can one expect if one reads from a different node from where the data is collected? Is there a SYNC function or mechanism that would block until the data is consistent across the cluster?
A: Regarding latencies, ScyllaDB benefits from the smart driver used by the KairosDB server, it means that the KairosDB node “knows” where the data resides within the cluster. In the case of writes, we have set the Consistency Level (CL) to ONE. With CL=1, once the data is written and acknowledged by a single ScyllaDB node, the data is persisted in the cluster. The latency associated with such writes are in the single digit millisecond, as demonstrated in our testing.
When reading data from the cluster, we set the consistency level to Quorum. In the testing conducted, we had 3 nodes. So, CL=QUORUM means we have to get at least 2 coherent results from our 3 node cluster to define if the data is valid and return it to the client.
Q: How portable is the complete solution if an application is already running on a time-series database? I’m assuming that applications should not need an overhaul to accommodate or try ScyllaDB and KairosDB.
A: KairosDB supports multiple protocols to ingest and retrieve data. We expect to offer a smooth and easy migration. However, It will be beneficial to understand the data model you are using to give you the most accurate answer. If you’d like to consult with us, we are available on the following channels:
KairosDB mailing list
ScyllaDB mailing list
ScyllaDB Slack channel
During the webinar, we conducted two polls among the attendees. Below you can examine the polling results.
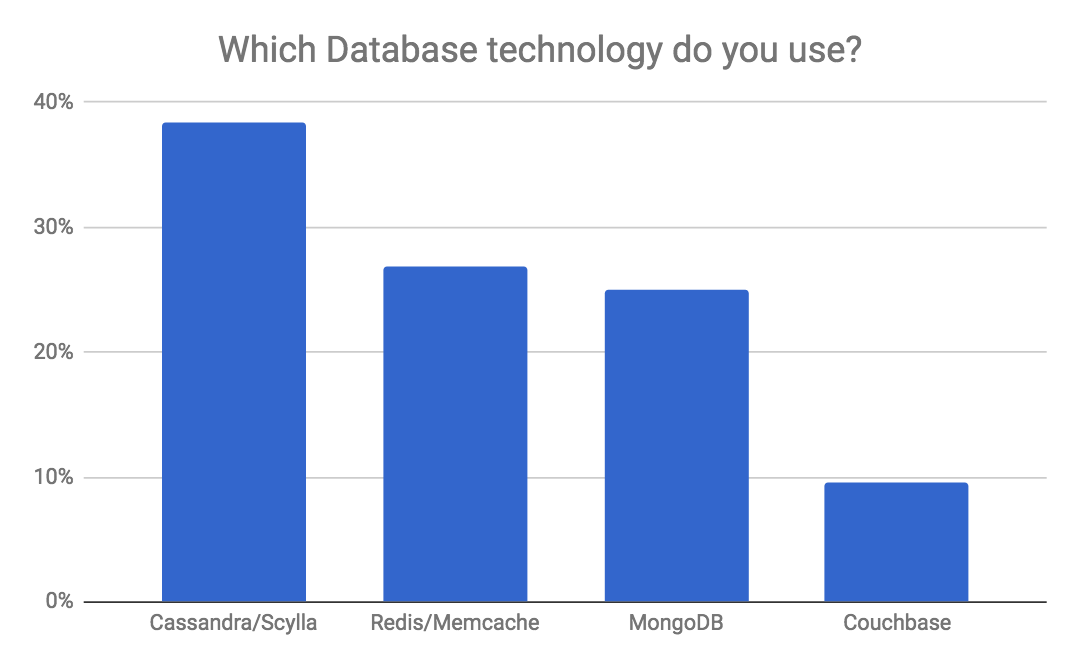
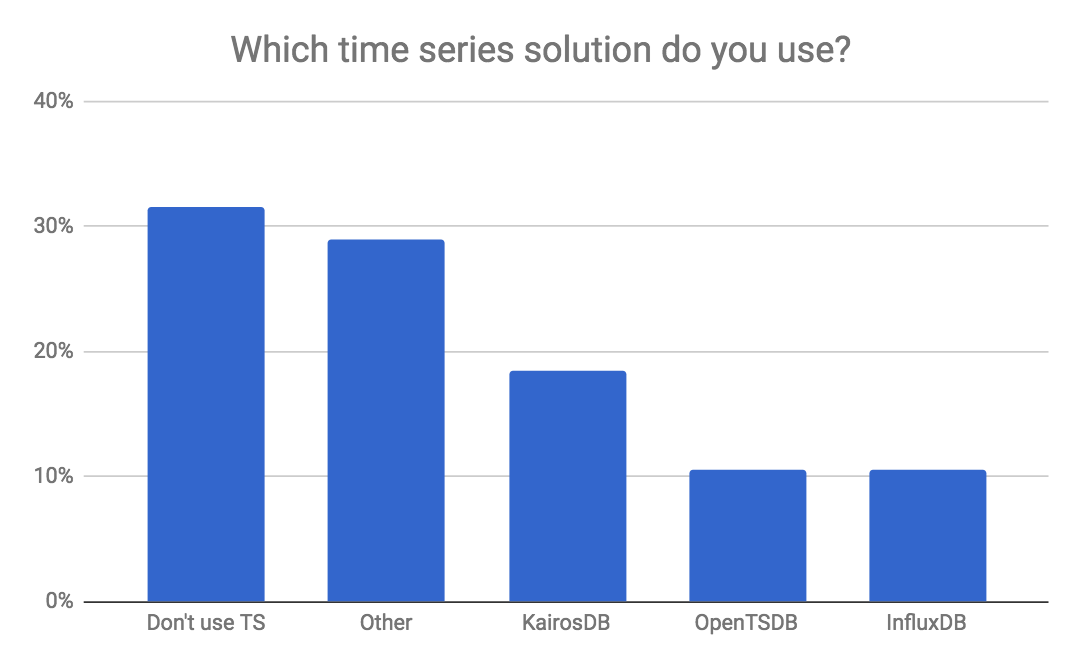
The slides from the webinar are available below:
Next Steps
- Watch our webinar, How to Build a Highly Available Time-Series Solution with KairosDB
- Learn more about ScyllaDB on our product page.
- See what our users are saying about ScyllaDB.
- Download ScyllaDB. Check out our download page to run ScyllaDB on AWS, install it locally in a Virtual Machine, or run it in Docker.



