Performance Report: ScyllaDB 1.6 vs Cassandra 3.0.9 on Amazon Web Services i2.8xlarge Instances Using 2TB of Data for Different YCSB Workloads
ScyllaDB on AWS i2.8xlarge Benchmark
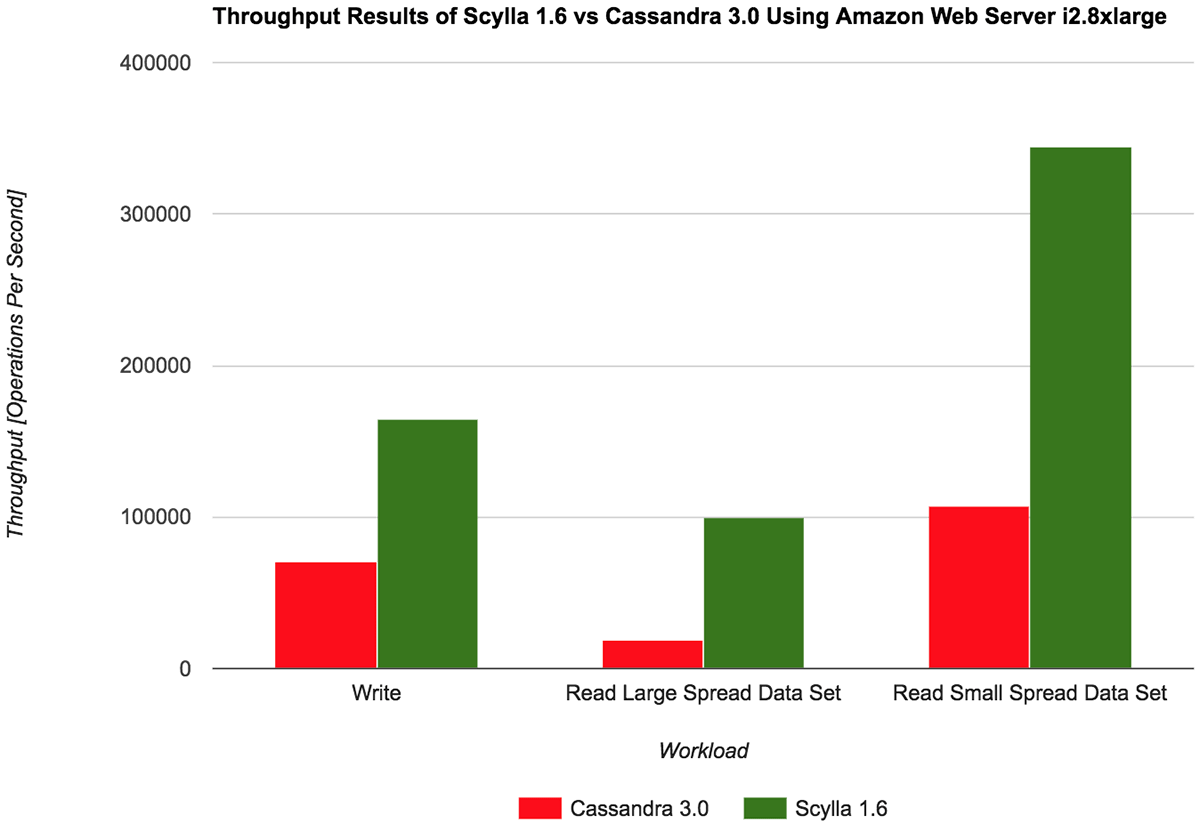
Benchmarking database systems helps users determine the best database solution for their application. ScyllaDB, an Apache Cassandra and Amazon DynamoDB drop-in replacement database, uses novel techniques to deliver best-in-class throughput and latency to users of wide column NoSQL databases. This AWS i2.8xlarge performance benchmark provides a throughput and latency measurements comparison of ScyllaDB 1.6 release vs. Cassandra 3.0.9 release. The results obtained from extensive testing show ScyllaDB outperforms Cassandra by factors of 2.3 to 5.1 based on the different workload tested. This document reviews the testing process, tuning and throughput and the latency measurements.
The Cassandra testing process
Our initial target version to benchmark Apache Cassandra was 3.9.0 from the Apache Cassandra repository. However, we ended up using the DataStax Community (DSC) version for the benchmark below. Tuning and operating Apache Cassandra and DSC is a lengthy process. We had several iterations and more than 80 hours of false starts before we were able to set up a stable Cassandra cluster. We learned that the DSC out-of-the-box experience will not provide users with the expected performance or stability for a production environment. Please refer to the settings applied to the Apache Cassandra installation at the end of this document. While testing Apache Cassandra 3.9.0, we found that extensive tuning is required to get the system stable, and the results obtained from Cassandra were far below our expectations. After installing Apache Cassandra 3.9.0, the first test we created was the data insertion test (write). During the test, insertion clients came to a halt and reported data insertion failures to the point that the job ended with a failure set. We added tuning to make sure we had enough file handlers and reduced the number of loaders. Still, the tests showed miserable performance results. We experienced write throughput in rates that were a small percentage of the ScyllaDB throughput rate. At that point, we decided to switch to the 3.x stable release (DSC version) and not use the cutting-edge Cassandra 3.9 release. The DSC is based on Apache Cassandra 3.0.9 version. While the installation process is more straightforward than the Apache version, the testing yielded some insight about the ways to operate Apache Cassandra. The first testing of data insertion of 11,600,000,000 partitions started smoothly. Our first configuration was naive—we didn’t change the JVM settings or the number of compactors used. So, with a default 4GB heap size, we tried to inject over 1TB of data. Once the initial writes failed we increased the JVM heap size to 24GB, and the data insertions went well until we reached ~50% of data in the servers. At the halfway point, all three Cassandra servers crashed with OOM errors. To save time we decided to stick with half the dataset testing and proceed with comparing Cassandra 3.9.0 to ScyllaDB. Later research yielded another configuration setting—increase the number of memory mapped files in the kernel from 64k to 1M to solve the dataset size limitation.
System under test
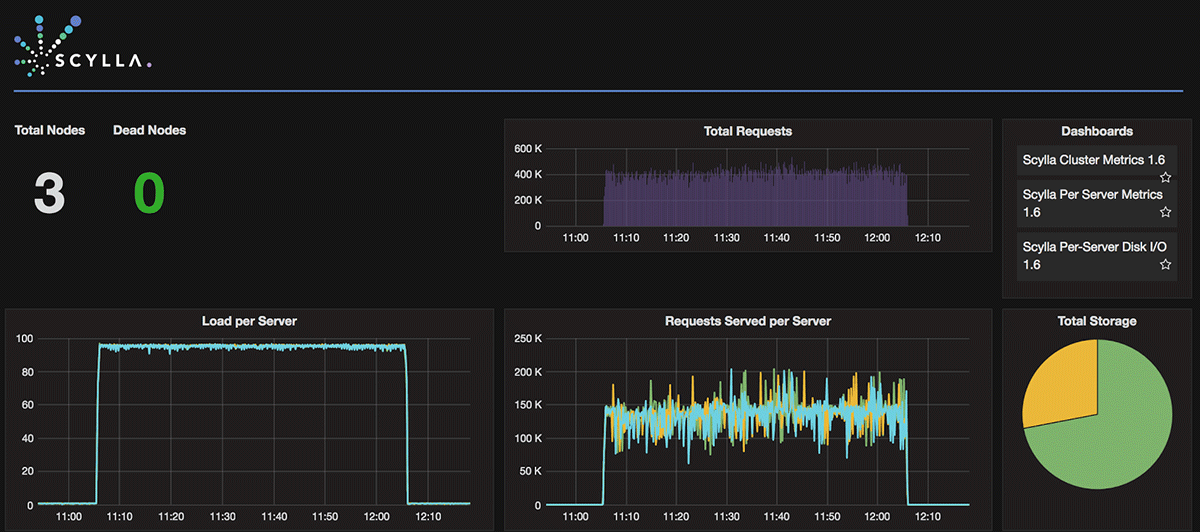
Both ScyllaDB and Cassandra use three i2.8xlarge AWS servers to cluster a 3-node database. Write and read loads are generated through 10 m4.2xlarge instances deployed in the same VPC. Installation, settings, and configurations of the servers and loaders are described later in the Installation and Setup section of this document.
Measurements from Cassandra stress tool
The Cassandra stress tool reports the number of operations per second (OPS) as measured by the client and provides six latency measurements: mean, median, 95%, 99%, 99.9% and max. All latency measurements are reported in milliseconds.
About the tests conducted
In each test scenario, ScyllaDB and Cassandra used their own 3 nodes of i2.8xlarge machines, provisioned on AWS EC2 west-2 region.
ScyllaDB setup included 3 database servers and 10 loaders. The Cassandra setup also included 3 database servers and 10 loaders.
Write workload test
To determine the performance of a write-only workload, each loader created unique partitions in the stress keyspace. A test schema using a replication factor of three was generated in each database. Table 1: Write workload results
Measurement
ScyllaDB 1.6
Cassandra 3.0.9
Row rate [OPS]
164,610
70,771
Latency mean [ms]
30
71
Latency median [ms]
24
20
Latency 95th percentile [ms]
51
143
Latency 99th percentile [ms]
66
478
Latency 99.9th percentile [ms]
296
1,384
Latency max [ms]
3,607
32,601
Observations from the write throughput workload test
ScyllaDB provides 230% better throughput while maintaining 99.9% latency at roughly one fifth of Cassandra latency. Looking into the bounding factors of the test, we observe that ScyllaDB throughput is bounded by CPU capacity, and the load on each server is nearly 100%. One note about latency: these are latency results under 100% CPU workload, and this is a throughput benchmark and thus the high latency results. If ScyllaDB or even Cassandra were run for working range (30%-50% load), the latency numbers would be dramatically lower.
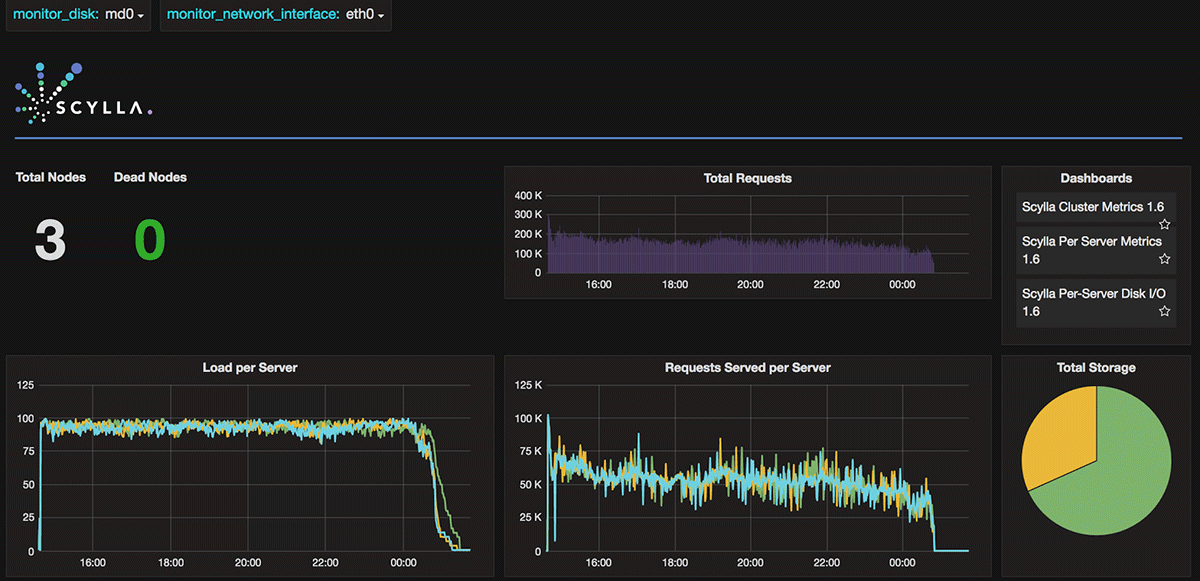
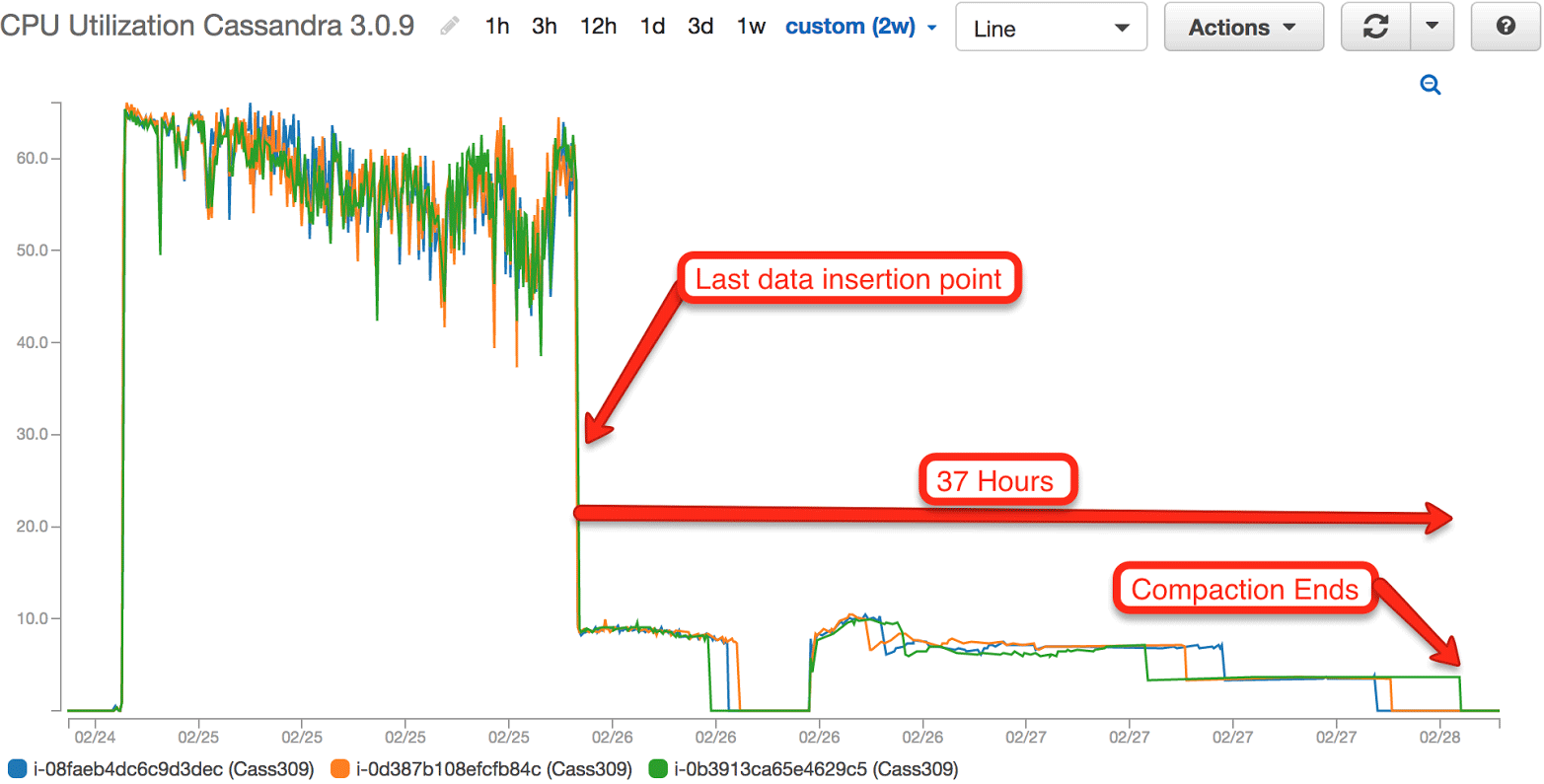
Figure 2 (above) shows ScyllaDB behavior during dataset insertion. CPU utilization is at peak. As can be seen, the CPU workload is back to idle roughly 30 minutes after the last data insertion. The short 30-minutes of additional CPU processing is attributed to the compaction process. For Cassandra CPU utilization, we see that the utilization process continued for an additional ~37 hours, for our data set of 1.3TB. The short period of low utilization seen in Figure 3 (below) is a time period in which the cluster crashed and restarted.
Read workload tests:
For the read workload tests, we generated two scenarios. The first scenario (large spread) explores a use case when most of the reads are fetched from disk. This scenario describes patterns where most of the data is not stored in cache, or the dataset is larger than the server’s RAM. The second scenario (small spread) explores a use case when most of the reads are fetched from memory. This scenario describes patterns, where data size is smaller than the server’s RAM, or a very narrow range of data is read by the application. Table 2: Large spread read results
Measurement
ScyllaDB 1.6
Cassandra 3.0.9
Row rate [OPS]
100,128
19,091
Latency mean [ms]
50
281
Latency median [ms]
5
55
Latency 95th percentile [ms]
138
618
Latency 99th percentile [ms]
569
4,027
Latency 99.9th percentile [ms]
2,344
9,465
Latency max [ms]
5,975
32,017
Table 3: Small spread read results
Measurement
ScyllaDB 1.6
Cassandra 3.0.9
Row rate [OPS]
344,051
107,598
Latency mean [ms]
15
50
Latency median [ms]
7
30
Latency 95th percentile [ms]
14
122
Latency 99th percentile [ms]
176
173
Latency 99.9th percentile [ms]
466
242
Latency max [ms]
1,138
389
Observations from ScyllaDB vs Cassandra read throughput tests
As mentioned before, we expect the large spread dataset read is to be served mostly from the storage media, in our case the 8x800GB SSD ephemeral volumes. Reviewing the load on ScyllaDB servers, we observe that the CPU is not bounded. However, the media is working at peak IOPs. The next order of work is to repeat the tests with newly available i3 instances on AWS—stay tuned for the next benchmarking reports.
Figure 4 (above) shows ScyllaDB behavior during the large dataset read test. CPU utilization and per-server requests are described in the lower part of the graph.
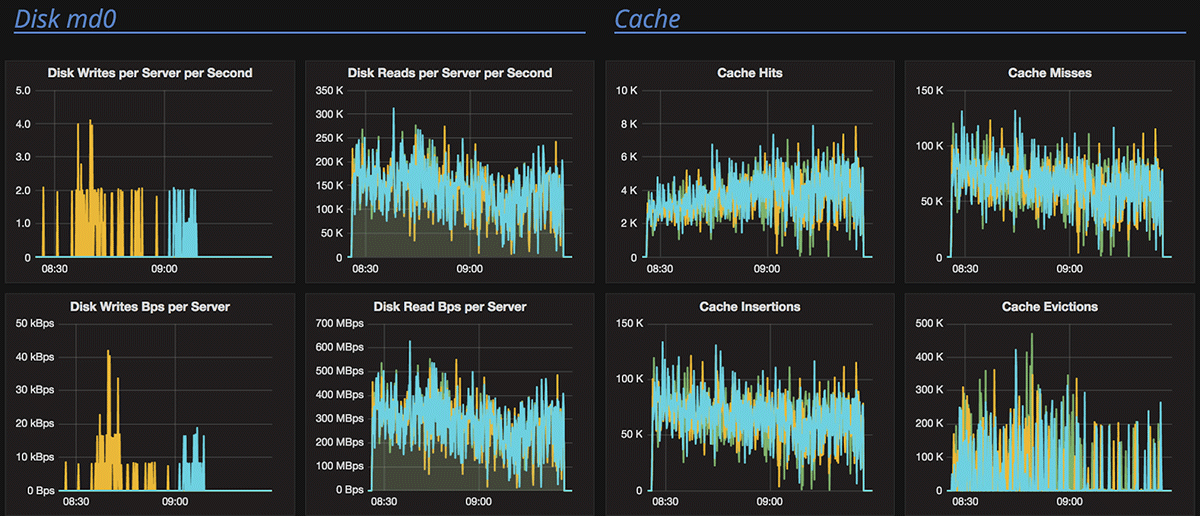
Figure 5 (above) shows ScyllaDB disk and cache behavior during the large dataset read process and illustrates the high rate of reads from disk and the expected high rate of cache misses. In the small spread read scenario, the media operation is minimal to non-existent, and the requests are served from server’s cache, sending the CPU load to its peak of nearly 100%.
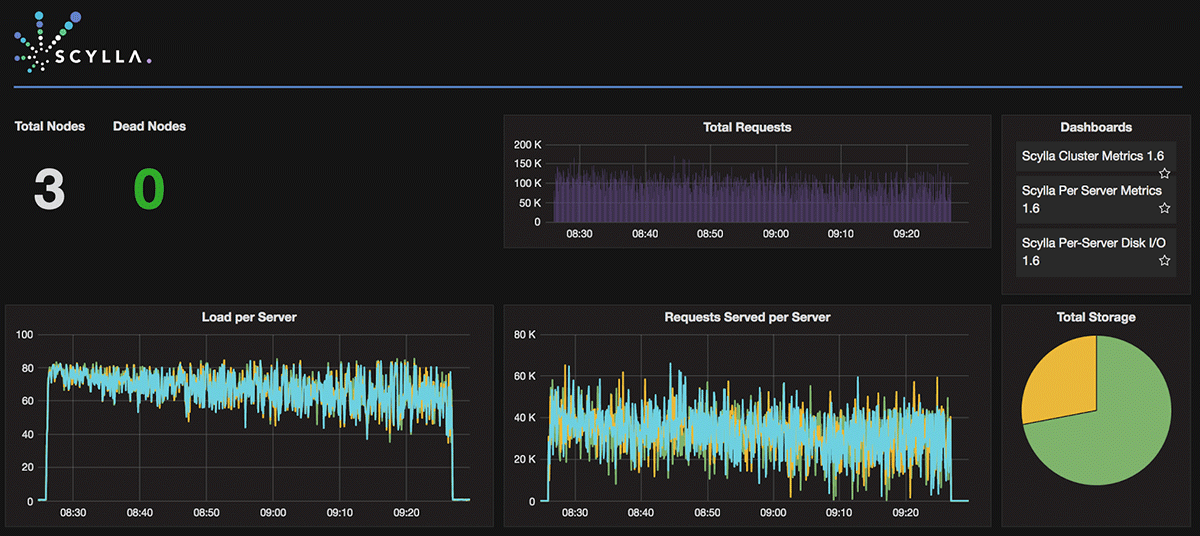
Figure 6 (above) shows ScyllaDB behavior during the small spread read test. CPU utilization is maximized and each server delivered more than 130K operations per second.
Figure 7 (above) shows ScyllaDB’s disk and cache behavior during the small spread read test. Nearly all requests are served from ScyllaDB’s cache.
Installation, configuration, and workload creation
In the following section, we will review the methods used to install ScyllaDB 1.6 and Cassandra 3.0.9 servers and loaders, which configuration settings were applied, and the method of creating the write, large spread read, and small spread read workloads.
Cassandra 3.0.9 Installation
For the Cassandra installation, we used DataStax Cassandra Community release, based on Apache Cassandra 3.0.9. Using Centos 7.2 AMI: ami-d2c924b2 as operating system for the instances.
We used ScyllaDB AMI ScyllaDB 1.6.0 (ami-930bb0f3), a three node orchestration completed on i2.8xlarge machines. No further settings or changes were made to the deployment.