



By default, ScyllaDB SSTables will be compressed when they are written to disk. As mandated by the file format, data is compressed in chunks of a certain size – 4kB if not explicitly set. The size of the chunk is one of the parameters for the compression property to be set at table creation.
Chunk-based compression presents trade-offs that users may not be aware of. In this post, I will try to explore what those trade-offs are and how to set them correctly for maximum benefit. As trade-offs imply different results for different loads, we will focus on single-partition read workloads for this analysis.
Reads versus Writes
Systems that are write-bound and bottlenecked at the disk may benefit from a larger chunk size. For those systems, increasing the chunk size will reduce the bandwidth used to write data.
Reads fall on the other side of the spectrum if your partitions are considerably smaller than the chunk size and the read has to reach the disk. What ends up happening is that the database has to fetch a lot more data to serve the request as the whole chunk needs to be brought to memory before it is decompressed.
Usually reading more than we have to is not a total loss because ScyllaDB can cache the vicinity of the partition currently being read. However, in databases like ScyllaDB and Cassandra that are backed by SSTables, spatial locality is poor because partitions are put side by side randomly according to the hash values of their partition keys.
Full-table-scans can still benefit from larger chunk sizes as I/O itself will be more efficient and we will eventually get to all of the partitions. But the situation changes dramatically for single-partitions reads.
Let’s look at a real example, trimmed for brevity, of “nodetool cfhistograms” run on a real table during a read workload:
In that output, we are interested in the “Partition Size” distribution. As we can see, 95 % of the requests are significantly smaller than the default chunk size of 4kB. In particular, 75 % of them are even smaller than 1kB – the minimum chunk size.
The end result of that is that every read ends up being amplified and we’ll have to read 4kB from disk to serve 310 bytes (75 % of the cases).
Such is the nature of trade-offs: if there are many more writes than reads, changing the chunk size may be detrimental. But if we are in a system that is expected to receive a lot more single-partition reads than writes, reducing the chunk size will lead to less disk I/O. As the individual requests get cheaper, this leads to better latencies as well.
Changing the chunk size is just a matter of doing:
ALTER TABLE ks.cf WITH compression = {'sstable_compression': 'org.apache.cassandra.io.compress.LZ4Compressor', 'chunk_length_kb': 1};
Existing tables will still have the current chunk length, but new tables will have 1kB chunks now. To see the effects of the change faster, one can issue “nodetool compact” on all nodes which will force the existing tables to be compacted.
Figures one and two were taken from a live 6-node cluster running a read-mostly (25:1 ratio) workload and were both taken in the absence of compactions – meaning that all bandwidth comes from reads.
As we can see in Figure one, all servers use approximately 80 MB/s of disk bandwidth, which is reduced to around 20MB/s – a factor of 4 as expected.
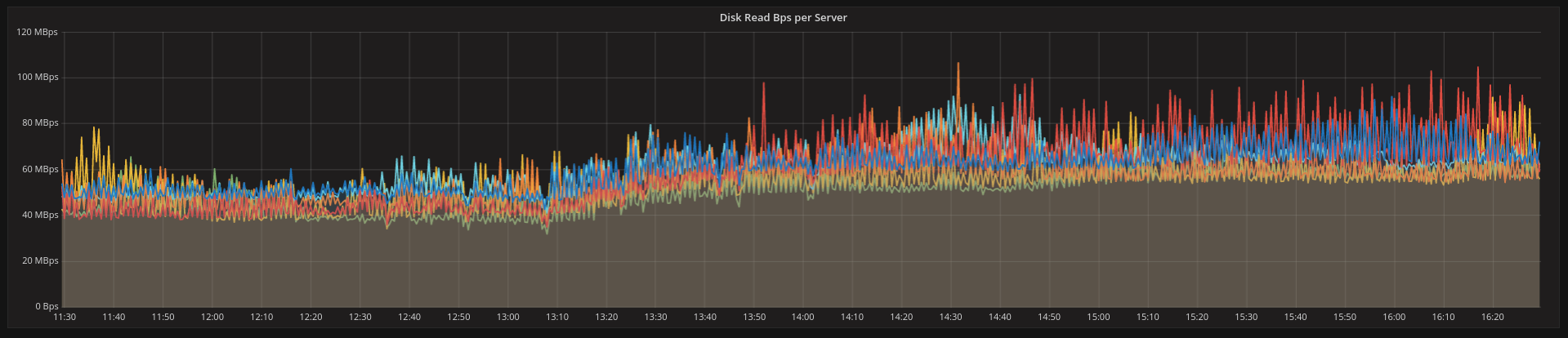
Figure 1: With 4kB chunks, reads use as much as 80MB/s worth of disk bandwidth. It’s mostly wasted since partitions are much smaller than that and there is no locality for caching.
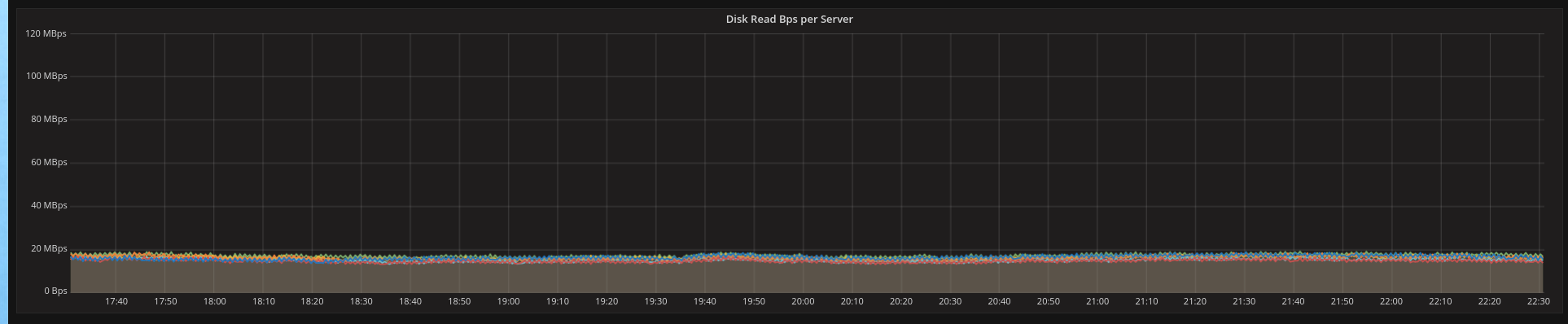
Figure 2: With 1kB chunks, the load is much easier on the disk.
Other factors to consider
Most metadata describing the SSTable files must be kept in memory to support fast access. That is also the case for the chunk descriptors. Smaller chunks will result is more chunk descriptors which imply more memory usage. Another factor to keep in mind is that bigger chunks may provide better compression ratios. Users that need a very low chunk size would benefit from experimenting with disabling compression altogether.
Conclusion
In this article, we have explored some factors that should be taken into consideration when selecting the chunk size for tables in ScyllaDB. We have seen that in situations in which locality is poor, such as single-partition reads, the disk usage and latency can be improved significantly if the chunk sizes are set in a way to reduce waste. Table 1 summarizes what the expected direction should be for common use cases – but actual results may vary!
Use case
|
Recommendation
|
Comments
|
small single key
|
smaller chunks
|
as close as possible to expected partition size
|
large single key
|
larger chunks
|
as close as possible to expected partition size
|
range scans
|
larger chunks
|
good cache locality
|
mostly writes
|
larger chunks
|
saves write bandwidth
|
Table 1: General direction for tuning compression chunk size.

